アルゴリズム
アルゴリズム 畳み込みで画像解析とは?仕組み・フィルター・特徴マップをやさしく解説
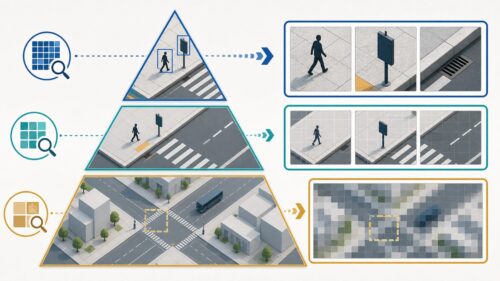
畳み込みとは、画像や音声といった情報を処理する際に、重要な特徴を抜き出すための手法です。まるで写真の上に虫眼鏡を滑らせるように、小さな枠(フィルター、またはカーネルと呼ばれます)を元の情報の上で少しずつ動かしていきます。この枠を通して見える一部分の情報と、枠に設定された数値をかけ合わせ、その合計値を新たな情報として記録します。これが、畳み込みの基礎となる計算です。
例として、画像の輪郭を強調したいとしましょう。この場合、フィルターには輪郭を検出するための特別な数値が設定されています。画像の明るい部分と暗い部分の境界にフィルターが重なると、大きな値が計算されます。逆に、色の変化が少ない部分では小さな値になります。このようにして、フィルターを画像全体に適用することで、輪郭が強調された新たな画像が生成されます。
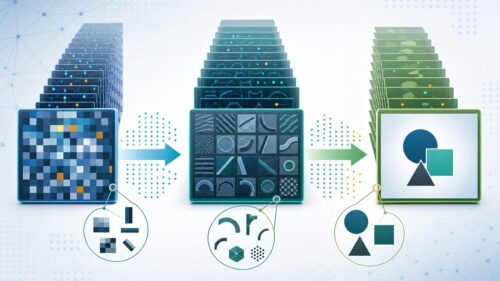
畳み込みは、様々な分野で活用されています。例えば、顔認識技術では、目や鼻、口といった顔の特徴を捉えるために畳み込みが使われています。また、音声認識では、特定の音声パターンを認識するために利用されています。さらに、自動運転技術では、周囲の物体を認識するために畳み込みが重要な役割を果たしています。
畳み込みの利点の一つは、フィルターの種類を変えることで、様々な特徴を抽出できることです。例えば、ぼかし効果を出したい場合は、周りの画素と平均を取るようなフィルターを用います。逆に、画像を鮮明にしたい場合は、輪郭を強調するフィルターを用います。このように、目的に応じてフィルターを使い分けることで、多様な画像処理を実現できます。また、畳み込みは並列処理に適しており、高速な計算が可能です。そのため、膨大なデータを扱う現代の情報処理において、不可欠な技術となっています。