学習
学習 L1正則化:モデルをシンプルにする魔法
機械学習の模型作りでは、学習しすぎるという問題によく直面します。これは、作った模型が、学習に使ったデータの特徴を捉えすぎることで起こります。例えるなら、特定の年の過去問を完璧に解けるように勉強した受験生が、本番の試験では応用問題に対応できず、良い点数が取れないようなものです。学習に使ったデータでは良い結果が出ても、新しいデータではうまくいかない、これが過学習です。
この過学習を防ぐための方法の一つに、正則化というものがあります。正則化は、模型が学習しすぎるのを抑えるための工夫のようなものです。受験生の例で言えば、過去問だけでなく、教科書の基本的な内容もしっかりと復習させるようなものです。正則化には色々な種類がありますが、中でもL1正則化は強力な手法として知られています。
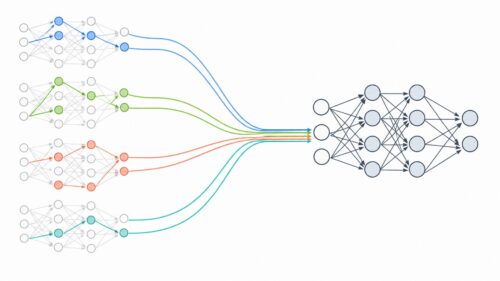
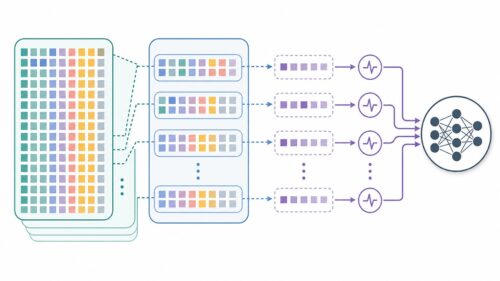
L1正則化は、模型の複雑さを抑える働きをします。模型を作る際には、たくさんの調整つまみのようなものがあり、これらをパラメータと呼びます。L1正則化は、これらのパラメータの多くをゼロに近づけることで、模型を単純化します。たくさんのつまみを複雑に操作するよりも、重要なつまみだけを操作する方が、模型の動きが分かりやすく、新しいデータにも対応しやすくなります。
このように、L1正則化は、模型が学習データに過度に適応するのを防ぎ、新しいデータにも対応できる能力、すなわち汎化性能を高めるために役立ちます。複雑で扱いにくい模型を、シンプルで扱いやすい模型に変える、まるで魔法の杖のような役割を果たすのです。