交差検証でモデルの精度を高める

AIの初心者
先生、「交差検証」って、データを分けて学習と評価に使うんですよね? なぜそんなことをするんですか?

AI専門家
いい質問だね。全部のデータで学習させて、全部のデータで評価したら良さそうに見えるよね。でも、それでは作ったAIが、未知のデータに対してきちんと動くか分からないんだ。だから、学習に使っていないデータで評価することで、本当の力を確かめる必要があるんだよ。
AIの初心者
なるほど。未知のデータで試すために、あえて学習に使わないデータを残しておくってことですね。でも、データを分けてしまうと、学習に使えるデータが減って、AIの性能が下がってしまうんじゃないですか?
AI専門家
その通り。だから、データをランダムに何度も分割し直して、その都度学習と評価を繰り返すんだ。そうすることで、限られたデータでも、色々な分割パターンで試せて、AIの性能をより正確に測ることができるんだよ。
交差検証とは。
「人工知能」についてよく使われる言葉である「交差検証」の説明です。いま手元にある全てのデータを、学習に使うデータ(訓練データ)と、学習した結果を評価するためのデータ(テストデータ)の2つに、ランダムに分けて評価する手法を「交差検証」と言います。
交差検証とは

機械学習の分野では、作った模型がどれくらい使えるのかを正しく測ることがとても大切です。この測り方のひとつに、交差検証というものがあります。交差検証は、限られた学習の材料をうまく使い回し、模型が初めて見る材料に対してどれくらいうまく対応できるのかを調べる方法です。
模型を作るには、学習用の材料と、出来上がった模型を試すための材料の2種類が必要です。もし、材料を単純に2つに分けるだけだと、分け方によって模型の出来栄えの見積もりが大きく変わってしまうことがあります。例えば、たまたま学習用の材料に難しい問題ばかり集まってしまうと、模型は実際よりも悪いように見えてしまいます。逆に、簡単な問題ばかりだと、実際よりも良く見えてしまうかもしれません。
このような偏りをなくすために、交差検証を使います。交差検証では、材料をいくつかの組に分け、それぞれの組を順番にテスト用の材料として使います。例えば、材料を5つの組に分けるとしましょう。最初の組をテスト用、残りの4つの組を学習用として模型を作ります。次に、2番目の組をテスト用、残りの4つの組を学習用として、また模型を作ります。これを全ての組が1回ずつテスト用になるまで繰り返します。
このようにすることで、全ての材料が1回ずつテストに使われることになります。それぞれのテストの結果を平均することで、特定の分け方に偏ることなく、模型の性能をより正確に見積もることができます。これは、まるで色々な問題を解かせてみて、その平均点で模型の本当の力を測るようなものです。この方法のおかげで、新しい材料に対する模型の対応力をしっかりと確かめることができ、より信頼できる模型を作ることができるのです。
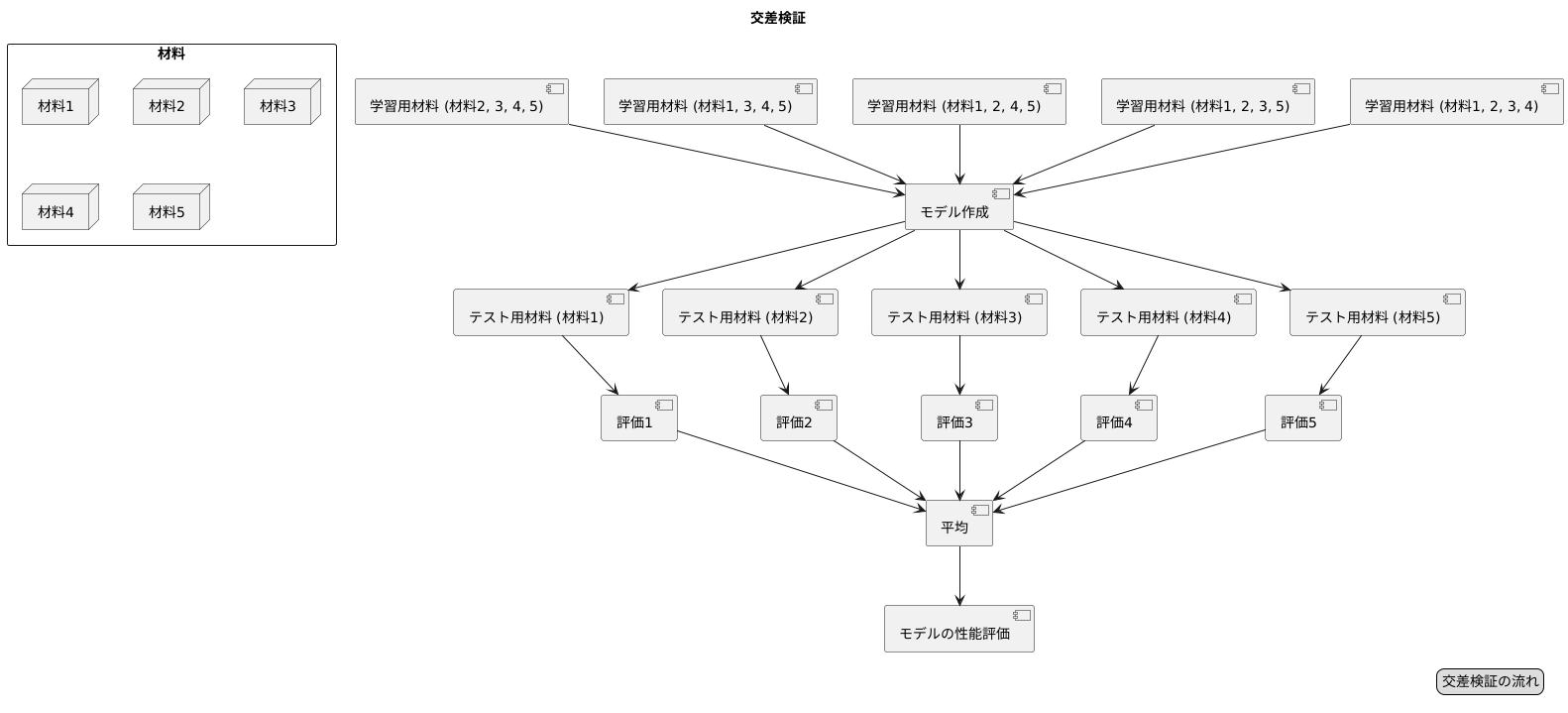
交差検証の方法

機械学習モデルの性能を正しく測るためには、交差検証という手法が欠かせません。この手法は、限られた学習データを有効に活用して、モデルの汎化性能、つまり未知のデータに対する予測能力を評価するものです。交差検証には様々な方法がありますが、ここでは代表的なものをいくつか紹介します。
まず、最も広く使われているのが「K分割交差検証」です。この方法では、データを同じくらいの大きさを持つK個のグループに分割します。そして、そのうちの1つのグループを評価用データ、残りのK-1個のグループを学習用データとしてモデルを学習させます。この手順をK回繰り返し、毎回異なるグループを評価用データとして使用することで、全てのデータが一度ずつ評価用データとして使われます。それぞれの評価結果を平均することで、モデルの全体的な性能を評価します。例えば、5分割交差検証であれば、データを5つのグループに分け、それぞれのグループを一度ずつ評価用データとして使用し、5回の評価結果を平均します。分割数Kの選び方はデータ量に依存しますが、一般的には5分割や10分割がよく使われます。Kが小さすぎると評価のばらつきが大きくなり、Kが大きすぎると計算時間が長くなります。
次に、「Leave-One-Out交差検証」を紹介します。これは、K分割交差検証の特殊な場合で、Kをデータ数と同じにしたものです。つまり、データを1つずつ評価用データとして使用し、残りのデータを学習用データとしてモデルを学習させます。この手順をデータ数と同じ回数だけ繰り返します。この方法は、データ数が少ない場合に有効ですが、データ数が多い場合は計算コストが非常に高くなります。
どの交差検証の方法が最適かは、データ量やモデルの複雑さによって異なります。データ量が少ない場合は、Leave-One-Out交差検証が適している場合もありますが、計算コストを考慮する必要があるでしょう。データ量が多い場合は、K分割交差検証が一般的です。いずれの場合も、目的に合わせて適切な方法を選択することが重要です。
| 交差検証手法 | 説明 | 利点 | 欠点 | 適用ケース |
|---|---|---|---|---|
| K分割交差検証 | データをK個のグループに分割し、1グループを評価用、残りを学習用としてK回学習・評価を行う。 | 広く使われており、比較的計算コストが低い。 | K値の選択が重要。小さすぎるとばらつきが大きく、大きすぎると計算時間が長い。 | データ量が多い場合に一般的。 |
| Leave-One-Out交差検証 | K分割交差検証の特殊ケースで、Kをデータ数と同じにする。つまり、1つずつデータを評価用とし、残りを学習用とする。 | データ数が少ない場合に有効。 | データ数が多い場合、計算コストが非常に高い。 | データ数が少ない場合。 |
交差検証の利点

機械学習モデルを作る上で、限られた学習データを最大限に活用することは非常に重要です。そのための有効な手法の一つが交差検証です。交差検証は、持っているデータを複数のグループに分割し、それぞれのグループを順番に検証データとして使い、残りのデータを学習データとしてモデルを学習させます。この手順を全てのグループに対して行うことで、全てのデータが学習と検証の両方で使われます。
交差検証の大きな利点は、モデルの汎化性能をより正確に評価できることです。汎化性能とは、未知のデータに対する予測精度のことです。通常の学習では、学習データと検証データを固定して評価しますが、これはデータの分け方によって評価結果が変わる可能性があります。交差検証では、全てのデータを検証に使うため、特定のデータの分け方に偏ることなく、モデルの真の実力を測ることができます。
もう一つの利点は、過学習の早期発見です。過学習とは、学習データの特徴を捉えすぎてしまい、未知のデータに対してうまく予測できない状態のことです。交差検証を行うと、それぞれのグループで検証した時の性能が大きく異なる場合、過学習が起きている可能性が高いと判断できます。例えば、あるグループでは非常に高い精度が出ているのに、別のグループでは精度が低い場合、モデルが特定のグループのデータに過剰に適合してしまっていると考えられます。このように、交差検証によって過学習の兆候を早期に捉えることで、モデルの調整や改良を行い、より信頼性の高いモデルを構築することができます。
つまり、交差検証は限られたデータを有効活用しながら、モデルの真の性能を測り、過学習を防ぐための強力な手法と言えるでしょう。
| 交差検証のメリット | 説明 |
|---|---|
| 限られたデータを有効活用 | 全てのデータを学習と検証の両方で使うことで、限られた学習データを最大限に活用できる。 |
| モデルの汎化性能をより正確に評価 | 全てのデータを検証に使うため、データの分け方に偏ることなく、モデルの真の実力を測ることができる。 |
| 過学習の早期発見 | それぞれのグループで検証した時の性能が大きく異なる場合、過学習が起きている可能性が高いと判断できる。 |
交差検証の注意点

学習の計算量が増えるという点に注意が必要です。
たとえば、データを5つに分割して検証する5分割交差検証を行うとします。この場合、モデルの学習と性能の評価を5回繰り返すことになります。単純な学習と評価に比べて5倍の時間がかかることになります。
特にデータの量が多い場合や複雑なモデルを使う場合は、計算にかかる時間は無視できないほど大きくなります。
膨大な量のデータを扱う場合、1回の学習に数時間、あるいは数日かかることもあります。これを5回繰り返すと、計算時間はさらに増大します。複雑なモデルも同様に、学習に多くの時間を要します。
計算に使える資源とデータの量を考慮して、適切な検証方法を選ぶことが重要です。
また、交差検証によって得られる結果は、あくまで推定値であることを理解しておく必要があります。
交差検証は、学習に使わなかったデータで性能を評価することで、未知のデータに対する性能を推定する方法です。しかし、これはあくまでも推定値であり、真の性能とは異なる可能性があります。真の性能を完全に知ることはできませんが、交差検証によってより正確な推定値を得ることができ、モデルの改良に役立てることができます。
交差検証は便利な手法ですが、計算時間や結果の解釈には注意が必要です。これらの点を踏まえ、適切に交差検証を活用することで、より信頼性の高いモデルを構築することができます。
| メリット | デメリット | 注意点 |
|---|---|---|
| 未知のデータに対する性能を推定できることで、モデルの改良に役立てることができる。 |
|
|
交差検証の実施例

病気を見分ける仕組みを作る場面を想像してみましょう。例えば、千人の患者さんの情報があり、それぞれの人が病気か健康かを示す印がついているとします。この情報を、学習用と評価用に分けます。学習用には八百人分、評価用には二百人分とします。この分け方で病気を見分ける仕組みを学習させると、たまたま評価用の二百人に特定の症状を持つ人が多く含まれているかもしれません。そのせいで、仕組みの精度が実際よりも高く見えてしまうことがあります。
そこで、五分割交差検証という方法を使います。これは、千人全員分の情報を学習と評価の両方に満遍なく使う方法です。具体的には、千人を二百人ずつの五つのグループに分けます。そして、それぞれのグループを順番に評価用として使い、残りの八百人を学習用として仕組みを学習させます。つまり、五回学習と評価を繰り返すことになります。
最初のグループを評価用とした場合、残りの四つのグループを合わせて八百人を学習用とします。この学習用データで学習させた仕組みを、最初のグループ二百人で評価します。次に、二番目のグループを評価用、残りの八百人を学習用として、同じように学習と評価を行います。これを五回繰り返します。それぞれのグループが一度ずつ評価用になるように順番に五回繰り返すわけです。
こうして五回分の評価結果が出ますので、これらを平均します。そうすることで、特定のグループに偏ることなく、より確かな精度を算出できます。一つだけの分け方で評価するよりも、全てのデータを使って評価することで、より信頼できる結果が得られるのです。
交差検証のまとめ

機械学習の分野では、作った模型がどれほど役に立つかをきちんと調べることがとても大切です。この作業を模型の評価と言い、その評価方法の一つに交差検証があります。交差検証は、限られた学習資料をうまく使い、模型が未知の資料にどれだけ対応できるかを正確に見積もるための方法です。
交差検証は、持っている学習資料をいくつかの組に分け、一つの組を検証用資料、残りの組を学習用資料として模型を作ります。そして、検証用資料を使って模型の性能を確かめます。この作業を、各組が一回ずつ検証用資料になるように繰り返すことで、全ての資料を検証に使い、模型の性能を様々な角度から評価します。
交差検証には様々な種類があります。例えば、単純な方法として、資料を均等に分割して検証する「単純分割交差検証」があります。また、資料数が少ない場合に有効な「一つ抜き交差検証」では、一つの資料を検証用にして残りを学習用にし、これを全ての資料に対して行います。さらに、「層化交差検証」は、各組の資料の分布が全体と同じになるように分割し、偏りを減らしてより正確な評価を行う方法です。どの方法を選ぶかは、持っている資料の量や計算に使える資源、模型の種類によって適切なものを選ぶ必要があります。
交差検証を適切に行うことで、より信頼できる模型を作ることができ、現実世界の問題解決に役立てることができます。例えば、医療分野では病気の診断支援、製造業では製品の品質管理、金融分野では不正検知など、様々な分野で活用されています。交差検証によって模型の精度と信頼性を高めることは、これらの分野での成果向上に大きく貢献します。
適切な交差検証は、高精度で信頼性のある模型を作るための土台となり、機械学習の可能性を最大限に引き出す鍵となります。機械学習に携わる人にとって、交差検証はなくてはならない道具と言えるでしょう。
| 交差検証の目的 | 交差検証の方法 | 交差検証の種類 | 交差検証の利点 | 交差検証の応用分野 |
|---|---|---|---|---|
| 模型の評価、未知の資料への対応力の正確な見積もり | 学習資料をいくつかの組に分け、一つの組を検証用、残りを学習用として模型を作り、検証用で性能を確かめる。これを各組が一回ずつ検証用になるように繰り返す。 | 単純分割交差検証、一つ抜き交差検証、層化交差検証 | 信頼できる模型作成、現実世界の問題解決に役立つ | 医療(病気の診断支援)、製造業(製品の品質管理)、金融(不正検知)など |