 画像生成
画像生成 画像変換技術Pix2Pixとは?意味・仕組み・活用例をわかりやすく解説
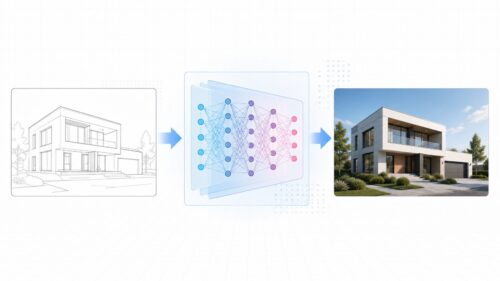
画像変換とは、一枚の画像を基にして、別の種類の画像を作り出す技術のことです。具体的な例を挙げると、白黒写真に色を付けて鮮やかなカラー写真にしたり、単純な線画をまるで写真のようにリアルな質感を持つ絵画に変換したり、昼間の明るい景色を夜の静かな風景に変えたりすることが可能です。このような変換は、以前は高度な技術と手間が必要でしたが、近年の人工知能技術の目覚ましい発展によって、誰でも手軽に利用できるようになってきています。
この技術は、娯楽分野だけに限らず、医療や自動運転といった幅広い分野での活用が期待されています。医療分野では、例えばレントゲン写真に写っている患部を分かりやすく強調することで、医師の診断を支援するのに役立ちます。従来は見落としやすかった小さな病変も、画像変換によって視認性を高めることで、早期発見・早期治療につながる可能性があります。また、自動運転技術においては、夜間の暗い画像を昼間の明るい画像に変換することで、夜間走行時の視認性を向上させることができます。暗い場所での認識能力が向上すれば、事故の発生率を減らし、より安全な運転を実現できるでしょう。このように、画像変換技術は私たちの暮らしをより豊かに、そしてより安全にする大きな可能性を秘めています。まるで魔法のような技術ですが、人工知能という名の技術によって実現されているのです。