AI活用
AI活用 本番環境でのモデル運用:成功への鍵
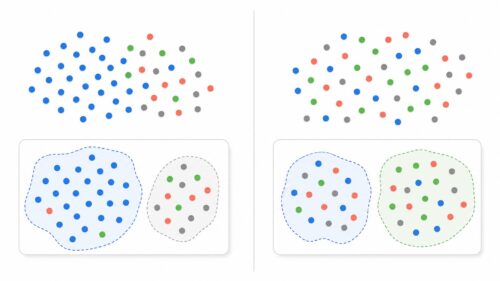
機械学習の模型を組み上げて、学習を終え、いよいよ実際に使えるようにして動き始めます。この段階で最も大切なのは、模型の動き方を注意深く見守ることです。なぜなら、実際に使う場面では、模型を作るときに用いた資料とは違う、現実世界からの資料が模型に入り込むため、思いもよらない動きを見せることがあるからです。
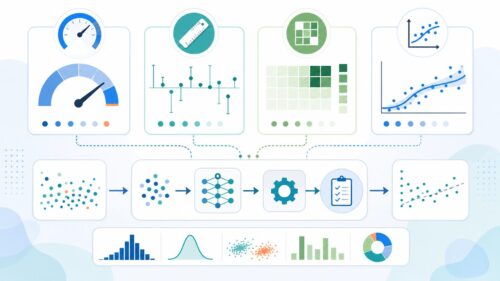
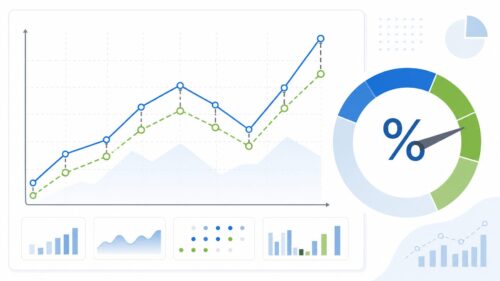
模型を作るときには考えていなかった資料のばらつきの変化や、周りの環境の変化によって、模型の正確さは下がるかもしれません。このような変化を早く見つけて、適切な対策を立てるには、模型の正確さをはじめとする様々な目安を続けて見守ることが欠かせません。たとえば、変な値を見つけたり、予想した値の確からしさを評価したり、様々な角度から模型の動き方を見守ることで、問題が起きたときに素早く対応できます。
また、見守る仕組みを作ることだけでなく、起きた問題への対応の手順をあらかじめ決めておくことも大切です。こうすることで、問題が起きたときの混乱を防ぎ、素早く適切な対応を実現できます。たとえば、模型の正確さが一定の基準を下回った場合、すぐに担当者に知らせる仕組みを作っておくなどが考えられます。また、再学習が必要な場合の具体的な手順や、緊急の修正プログラムを適用するための手順なども、前もって決めておくべきです。
続けて見守り、素早く対応することこそが、模型を安定して動かすための大切な要素となります。変化の激しい現代においては、一度作った模型をそのまま放置するのではなく、常にその状態を把握し、必要に応じて改善していくことが重要です。これにより、常に最適な状態で模型を運用し、その価値を最大限に引き出すことができるのです。