学習
学習 最適なモデル選び:情報量規準の活用
機械学習では、目的に合った適切な予測模型を選ぶことがとても大切です。精度の良い予測模型を作ろうとするあまり、特定の訓練データにだけ過剰に適応した、いわゆる「過学習」の状態に陥ることがあります。過学習とは、訓練データにぴったり合いすぎて、新しいデータに対する予測精度が落ちてしまう現象です。
例えるなら、試験対策で過去問ばかりを解き、解答を丸暗記したとします。過去問と同じ問題が出れば満点を取れるかもしれませんが、少し違う問題や応用問題には対応できません。これと同じように、過学習した予測模型は、訓練データでは高い精度を示しますが、未知のデータでは期待通りの性能を発揮しません。
過学習を避けるには、予測精度だけでなく、模型の複雑さも考える必要があります。複雑な模型は、たくさんの調整可能な要素を持っています。これは、複雑な関数を使ってデータを表現できることを意味しますが、同時に、データの中に含まれる本来意味のない細かな変動(雑音)まで学習してしまう危険性も高まります。雑音まで学習してしまうと、真のデータの規則性を捉えられなくなり、未知のデータへの対応力が低下します。
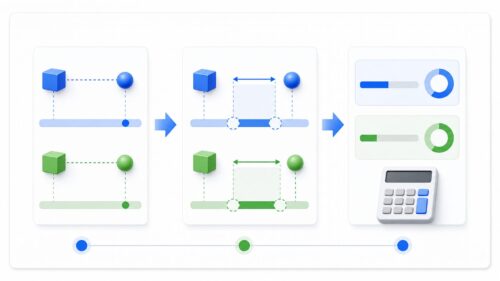
適切な模型を選ぶには、精度と複雑さのバランスを取ることが重要です。例えば、交差検証という手法を用いて、複数の模型の性能を比較し、最も汎化性能の高い模型を選びます。汎化性能とは、未知のデータに対する予測性能のことです。また、正則化という手法を用いて、模型の複雑さを調整することも有効です。正則化は、模型の複雑さにペナルティを科すことで、過学習を抑える効果があります。
このように、様々な手法を駆使して、過学習を防ぎ、最適な模型を選択することが、機械学習では求められます。