学習
学習 交差検証でモデルの精度を確かめる
機械学習の分野では、作った予測模型がどれほど使えるものなのかを確かめることがとても大切です。この確かめ方の一つに、交差検証と呼ばれるやり方があります。交差検証を使う一番の目的は、限られた学習データを最大限に活用して、模型の汎化性能を正しく評価することです。汎化性能とは、未知のデータに対しても、模型がどれほど正しく予測できるかを示す能力のことです。
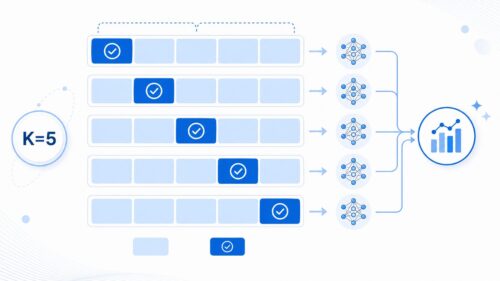
交差検証は、持っている学習データをいくつかのグループに分け、順番にそれぞれのグループを検証用のデータとして使い、残りのグループを学習用のデータとして模型を作る、という手順で行います。例えば、データを五つのグループに均等に分けたとしましょう。まず、最初のグループを検証用データ、残りの四つのグループを学習用データとして模型を作ります。次に、二番目のグループを検証用データ、それ以外の四つのグループを学習用データとして、また模型を作ります。これを五回繰り返すと、全てのグループが一度ずつ検証用データとして使われることになります。
このようにして作った五つの模型の性能を平均することで、特定のデータの分け方による偏りを減らし、より確かな評価結果を得ることができるのです。例えば、たまたま学習用データに特徴的なデータが多く含まれていた場合、そのデータに特化した模型ができてしまう可能性があります。しかし、交差検証を行うことで、そのような偏りを抑え、様々なデータで模型の性能を検証することができるため、未知のデータに対してもきちんと予測できる、より信頼性の高い模型を作ることができるのです。つまり、交差検証は、限られたデータから、より多くのことを学び取り、より優れた模型を作るための、有効な手段と言えるでしょう。