 アルゴリズム
アルゴリズム Swish関数とは?活性化関数の仕組み・ReLUとの違い・使いどころを解説
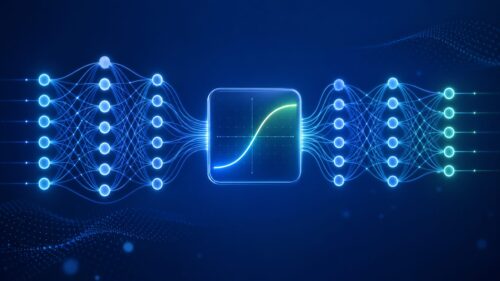
人の脳の神経細胞の働きを真似た仕組みであるニューラルネットワークは、人工知能の重要な部分を担っています。このネットワークは、たくさんのノード(ニューロン)が複雑につながり合った構造をしています。これらのノードの間で情報がやり取りされる時に、活性化関数が重要な役割を担います。活性化関数は、入力された信号を受け取り、出力信号に変換する役割を担っています。ちょうど、情報の伝達を管理する門番のような役割です。
活性化関数は、入力信号がある値を超えた場合のみ、情報を次のノードに伝えることで、ネットワーク全体の学習の効率を高めます。もし活性化関数がなければ、ネットワークは単純な変換の繰り返しに過ぎず、複雑な模様を学ぶことはできません。例えば、たくさんの数字が書かれた画像から、特定の数字だけを認識するといった複雑な学習を行うには、活性化関数は欠かせません。
活性化関数の種類は様々で、それぞれに特徴があります。段階関数は、入力値が0より大きければ1を、そうでなければ0を出力する単純な関数です。他にも、滑らかに変化するシグモイド関数や、より学習効率の高いReLU関数など、様々な活性化関数が使われています。
つまり活性化関数は、ニューラルネットワークが複雑な問題を解くために、なくてはならない重要な要素なのです。適切な活性化関数を選ぶことで、ネットワークの学習能力を向上させ、より高度な人工知能を実現することが可能になります。言い換えれば、活性化関数はニューラルネットワークの学習能力を左右する重要な鍵と言えるでしょう。