分類問題:機械学習の基本

AIの初心者
先生、写真を見てそれが犬か猫か判断するのも分類問題ですか?

AI専門家
そうだね。犬か猫かを判断するということは、写真の動物を「犬」と「猫」という二つの種類に分けていることになる。だから、分類問題と言えるよ。
AIの初心者
種類を分けるのが分類問題なんですね。写真の動物が犬の種類でチワワなのか、それとも柴犬なのかを判断するのも分類問題ですか?
AI専門家
その通り!これも「チワワ」「柴犬」など、いくつかの種類に分けていることになるから、分類問題だね。分類問題では、写真やデータを見て、それがどの種類に当てはまるのかをAIに学習させるんだ。
分類問題とは。
「人工知能」に関わる言葉である「分類問題」について説明します。例えば、動物の写真のような、いくつかの種類(連続していない値)に当てはまるものを予測する問題のことを「分類問題」と言います。
分類問題とは

分類問題は、ものごとを決められた種類に仕分けする問題です。ものごとの特徴をつかんで、どの種類に当てはまるかを判断します。身近な例では、果物を種類ごとに分ける作業が挙げられます。りんご、みかん、バナナをそれぞれのかごに入れるのは、まさに分類問題を解いていることになります。
機械学習の世界では、この分類問題をコンピュータに解かせるための方法が盛んに研究されています。コンピュータに大量のデータを見せて、それぞれのデータの特徴を学習させます。たとえば、たくさんのりんご、みかん、バナナの画像を見せることで、それぞれの果物の形や色、模様などの特徴をコンピュータに覚えさせます。この学習が終わると、コンピュータは新しい果物の画像を見せられても、それがどの果物なのかを高い確度で当てられるようになります。
学習には様々な方法があり、それぞれに得意不得意があります。決定木と呼ばれる方法は、まるで樹形図のように条件分岐を繰り返して分類を行います。一方、サポートベクトルマシンと呼ばれる方法は、データの境界線をうまく引くことで分類を行います。また、最近注目を集めている深層学習は、人間の脳の仕組みを模倣した複雑な計算で、より高度な分類を可能にします。
分類問題は、様々な分野で活用されています。迷惑メールの自動振り分けや、手書き文字の認識、医療画像診断など、私たちの生活を支える多くの技術に分類問題が関わっています。例えば、迷惑メールの振り分けでは、メールの本文や送信元情報などの特徴から、迷惑メールかどうかをコンピュータが自動的に判断します。手書き文字の認識では、文字の画像から、それがどの文字なのかをコンピュータが判別します。医療画像診断では、レントゲン写真やCT画像などの画像データから、病気の有無や種類をコンピュータが補助的に判断します。このように、分類問題は現代社会の様々な場面で役立っています。
| 概要 | 例 | 機械学習での応用 | 学習方法 | 活用例 |
|---|---|---|---|---|
| ものごとを決められた種類に仕分けする問題 | りんご、みかん、バナナをそれぞれのかごに入れる | コンピュータに大量のデータを見せて、データの特徴を学習させ、新しいデータがどの種類に属するかを予測させる | 決定木、サポートベクトルマシン、深層学習など | 迷惑メールの自動振り分け、手書き文字の認識、医療画像診断 |
分類問題の種類

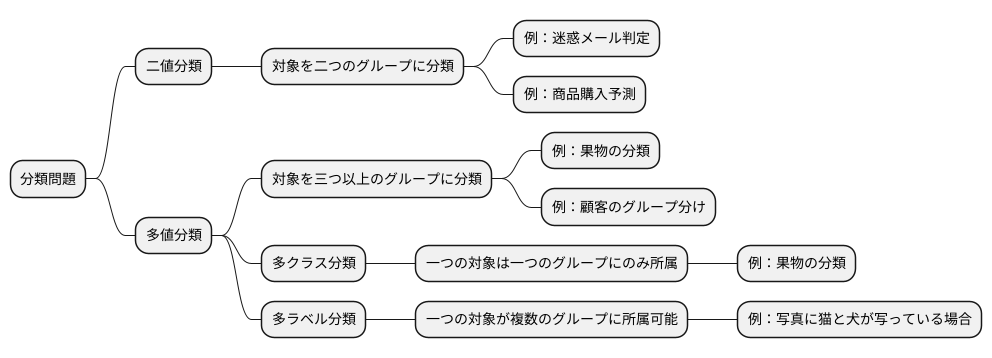
ものをグループ分けする作業、つまり分類問題は、様々な種類があり、大きく二種類に分けられます。一つは二値分類、もう一つは多値分類です。
二値分類とは、対象を二つのグループのどちらかに振り分ける問題です。身近な例では、受信した電子メールが迷惑メールかそうでないかを判断する作業が挙げられます。迷惑メールか、そうでないか、白黒はっきりさせる必要があります。他にも、商品の購入履歴から、顧客が特定の商品を購入するかどうかを予測する、といった場面でも使われます。
一方、多値分類は、三つ以上のグループに分類する問題です。例えば、果物を種類ごとに仕分ける作業を考えてみましょう。りんご、みかん、バナナなど、様々な種類の果物をそれぞれのグループに正しく分類していく必要があります。他にも、顧客を年齢層や購買傾向に応じてグループ分けするといったマーケティング分野でも活用されています。
さらに、多値分類の中には、多クラス分類と多ラベル分類という区別もあります。多クラス分類では、一つの対象は必ず一つのグループにのみ所属します。果物の分類でいえば、一つの果物は必ずりんごか、みかんか、バナナか、いずれか一つの種類に分類されます。しかし、多ラベル分類では、一つの対象が複数のグループに所属することが可能です。例えば、一枚の写真に猫と犬が写っている場合を考えてみましょう。この写真は「猫」のグループと「犬」のグループ、両方に所属することになります。このように、分類問題は様々な種類があり、扱うデータや解決したい問題に応じて、適切な方法を選ぶことが重要です。
分類問題のアルゴリズム

ものの種類分け問題を解くための色々なやり方が考えられています。よく使われるやり方として、決定木、サポートベクターマシン、ロジスティック回帰、近いもの探し法などがあります。これらのやり方には、それぞれ良さや悪さがあるので、扱うものに合わせて最適なやり方を選ぶことが大切です。決定木は、木の形を使ってものを分類するやり方です。木の枝分かれによって、段階的にものを分けていくことで、最終的にどの種類に属するのかを判断します。このやり方は、人が見て分かりやすいという利点があります。まるで家系図のように、どの特徴が分類に重要なのかを視覚的に理解できるので、説明がしやすくなります。サポートベクターマシンは、ものをより複雑な空間上に配置し、最適な境界面で分類するやり方です。このやり方は、高い正答率が期待できます。複雑な空間を使うことで、一見分類が難しそうなものも、うまく切り分けることができます。ロジスティック回帰は、ものがそれぞれの種類に属する割合を予想するやり方です。割合に基づいて分類できるので、どの種類に属するのかだけでなく、その確からしさも知ることができます。近いもの探し法は、もの同士の近さを測り、最も近い決まった数のものの多数決で分類するやり方です。このやり方は、簡単に使えるという利点があります。複雑な計算が必要ないので、手軽に分類問題を解きたい場合に便利です。このように、それぞれのやり方には、向き不向きがあります。ものの性質や問題の種類に合わせて、適切なやり方を選ぶことで、より良い結果を得ることができます。
| 分類方法 | 説明 | メリット |
|---|---|---|
| 決定木 | 木の形を使ってものを分類。段階的に分けていく。 | 人が見て分かりやすい。説明しやすい。 |
| サポートベクターマシン | 複雑な空間上に配置し、最適な境界面で分類。 | 高い正答率。 |
| ロジスティック回帰 | ものがそれぞれの種類に属する割合を予想。 | 割合に基づいて分類。確からしさも分かる。 |
| 近いもの探し法 | もの同士の近さを測り、最も近いものの多数決で分類。 | 簡単に使える。手軽。 |
分類問題の評価指標

ものの分け方を決める問題を解くための答え合わせの方法にはいろいろあり、それぞれに合った方法を使うことが大切です。よく使われる方法には、正解率、適合率、再現率、F値などがあります。
正解率は、全体の中でどれだけ正しく分けられたかを示す割合です。例えば、100個の果物の中にりんごが30個、みかんが70個あり、それを分類する問題で、90個を正しく分類できた場合、正解率は90%となります。
適合率は、りんごだと判断したものの中で、実際にりんごだった割合を示します。例えば、35個をりんごだと判断し、そのうち30個がりんごだった場合、適合率は30/35、つまり約86%です。
再現率は、実際にあるりんごのうち、どれだけりんごだと判断できたかの割合を示します。例えばりんごは全部で30個あり、そのうち27個をりんごだと判断できた場合、再現率は27/30、つまり90%です。
F値は、適合率と再現率を両方とも考慮した値です。適合率だけが高い場合や、再現率だけが高い場合は、偏った結果になってしまう可能性があります。F値を使うことで、適合率と再現率のバランスをみて、より正確に分類の正しさを評価できます。
これらの方法は、問題によって使い分ける必要があります。例えば、病気の診断のように、病気の人を見逃したくない場合は、再現率を重視します。病気でない人を病気だと判断してしまうことは問題ですが、病気の人を病気でないと判断してしまうのはより深刻な問題です。なので、実際には病気である人を、可能な限り病気であると判断できることが重要になります。
反対に、迷惑メールの分類のように、普通のメールを迷惑メールだと判断したくない場合は、適合率を重視します。迷惑メールを見逃すことは問題ですが、大事なメールを迷惑メールとして分類してしまうのはもっと問題です。なので、迷惑メールだと判断したものが、本当に迷惑メールである割合が高い方が良いのです。
| 指標 | 説明 | 例 | 重視するケース |
|---|---|---|---|
| 正解率 | 全体の中でどれだけ正しく分けられたかの割合 | りんご30個、みかん70個、計100個の果物を分類。90個正解 => 正解率90% | – |
| 適合率 | りんごだと判断したものの中で、実際にりんごだった割合 | 35個をりんごだと判断、うち30個がりんご => 適合率 30/35 (約86%) | 迷惑メールの分類(普通のメールを迷惑メールと誤判定したくない) |
| 再現率 | 実際にあるりんごのうち、どれだけりんごだと判断できたかの割合 | りんご30個中、27個をりんごと判断 => 再現率 27/30 (90%) | 病気の診断(病気の人を見逃したくない) |
| F値 | 適合率と再現率を両方考慮した値 | – | 適合率と再現率のバランスを取りたい場合 |
分類問題の応用

分類問題は、物事をいくつかの種類に分ける問題であり、様々な分野で広く活用されています。私たちの身近なところから高度な専門分野まで、多くの応用例が存在します。画像認識の分野では、写真に写っているものが何であるかを判断するのに使われています。例えば、自動運転技術では、カメラで捉えた映像から歩行者や信号、他の車両などを識別することで、安全な運転を支援しています。また、スマートフォンで撮影した写真から、写っている人物を自動でグループ分けするといった機能にも、この技術が役立っています。
音声認識の分野でも、分類問題は重要な役割を担っています。音声データを文字に変換する際に、それぞれの声を音の最小単位に分類することで、正確な文字起こしを可能にしています。音声アシスタントや音声入力キーボードなど、音声技術を用いた様々なサービスでこの技術が活用されています。
文章を扱う自然言語処理の分野では、文章の感情を読み解いたり、迷惑メールを自動で判別したりする際に、分類問題が用いられています。例えば、商品の口コミを分析して、肯定的な意見と否定的な意見に分類することで、商品の評判を把握することができます。また、大量のメールの中から迷惑メールを自動的に振り分けることで、私たちの時間を節約することに繋がっています。
さらに、医療の分野では、病気の診断や治療方針の決定を支援するために、分類問題が活用されています。レントゲン写真やCT画像から病変を見つけたり、患者の症状から適切な治療法を選択したりする際に、この技術が役立っています。金融の分野では、融資の審査や不正行為の検知などにも利用されています。顧客の信用度を評価したり、不正な取引を識別したりすることで、安全な金融取引を支えています。このように、分類問題は現代社会の様々な場面で活躍しており、私たちの生活をより便利で豊かなものにしています。
| 分野 | 分類問題の応用例 |
|---|---|
| 画像認識 | – 写真に写っているものの判断(自動運転での歩行者、信号、車両の識別など) – スマートフォンでの写真の自動グループ分け |
| 音声認識 | – 音声データの文字変換(音声の最小単位への分類による正確な文字起こし) – 音声アシスタント、音声入力キーボード |
| 自然言語処理 | – 文章の感情分析(肯定的・否定的意見の分類) – 迷惑メールの自動判別 |
| 医療 | – 病気の診断支援(レントゲン写真、CT画像からの病変発見) – 治療方針決定支援(症状からの適切な治療法選択) |
| 金融 | – 融資審査(顧客の信用度評価) – 不正行為の検知(不正な取引の識別) |
分類問題の課題

ものの種類を見分ける問題は、機械学習の中でも比較的簡単な問題ですが、いくつかの難しい点もあります。まず、扱う情報の内容が大切です。見分けるための道具は、学ぶための情報の良し悪しに大きく左右されます。学ぶための情報に誤りや偏りがあると、道具の性能が下がってしまうことがあります。ですから、学ぶための情報をきちんと整え、不要なものを取り除くことが重要になります。
次に、情報量の多さへの対応も難しい点です。写真や文章といった情報量の多い種類を見分けるのは、計算に時間がかかります。そのため、情報量を減らす工夫が必要です。たとえば、たくさんの情報の中から、本当に必要な情報だけを選び出すことで、計算の負担を軽くすることができます。
さらに、種類ごとの数のバランスも問題になります。不正を見つける場合のように、ある特定の種類の情報がとても少ない場合があります。この場合、道具は数が少ない種類を学ぶのが難しくなります。数が少ない種類を見分けられない道具になってしまいます。このような時は、情報が少ない種類を多くしたり、多い種類を少なくしたりして、数のバランスを調整する必要があります。数のバランスがとれていれば、道具はすべての種類を平等に学ぶことができます。
最後に、情報の複雑さも課題です。現実世界の問題は、単純な分類では解決できないことが多く、複数の要素が絡み合っている場合がほとんどです。例えば、医療診断では、患者の症状、検査結果、既往歴など、様々な情報を総合的に判断する必要があります。このような複雑な問題に対応するためには、より高度な分類手法が必要となります。
これらの難しい点を一つずつ解決していくことで、より性能の良い種類を見分ける道具を作ることができるようになります。
| 問題点 | 詳細 | 対策 |
|---|---|---|
| 情報の質 | 学習データの誤りや偏りは性能低下につながる | 学習データを適切に整理し、不要なものを取り除く |
| 情報量 | 写真や文章など情報量が多いと計算に時間がかかる | 重要な情報だけを選び出し、情報量を減らす |
| 種類の数のバランス | 特定の種類のデータが少ないと、その種類を学習するのが難しい | 少ない種類のデータを増やす、多い種類のデータを減らすなどしてバランスを調整する |
| 情報の複雑さ | 現実世界の問題は単純な分類では解決できないことが多い | より高度な分類手法を用いる |