AI活用
AI活用 エッジAIで変わる未来
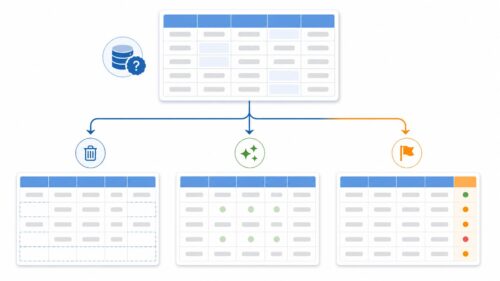
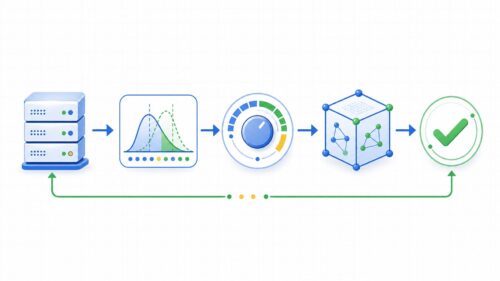
近年、機械の知能は目覚しい発展を見せており、私たちの暮らしに大きな変化をもたらしています。その中で、特に注目を集めているのが「末端機械知能」です。末端機械知能とは、一体どのような技術なのでしょうか。この言葉は、「末端」と「機械知能」という二つの言葉からできています。「末端」とは、端っこのことで、データが生み出される場所に最も近い機器のことを指します。例えば、携帯電話や家電、工場の機械などが挙げられます。これらの機器は、これまで集めたデータを中央にある大きな計算機に送って、分析や処理をさせていました。一方、「機械知能」とは、人間の知能を機械で実現しようとする技術のことです。つまり、末端機械知能とは、データが生み出されるその場で、機械知能による分析や処理を行う技術のことなのです。これまでのように、データを中央の計算機に送る必要がないため、通信にかかる時間や費用を節約できます。また、中央の計算機に負荷がかかりすぎるのを防ぐこともできます。さらに、インターネットに接続されていない場所でも、機械知能による処理を行うことができます。例えば、インターネットに接続されていない工場の機械でも、末端機械知能を使えば、故障の予兆を検知したり、生産効率を向上させたりすることが可能になります。このような利点から、末端機械知能は、様々な分野で活用が期待されています。今後、私たちの生活をより豊かに、より便利にしてくれる技術として、ますます発展していくことでしょう。