アルゴリズム
アルゴリズム LSTM:長期記憶を掴むAI
人間の脳のように、情報を長い間覚えておく仕組みを人工的に作り出したものが、エル・エス・ティー・エム(長期短期記憶)と呼ばれる技術です。これは、人工知能の分野で画期的な進歩をもたらしました。
以前からある、情報の繋がりを学習する仕組み(再帰型ニューラルネットワーク)は、短い間の記憶を扱うのは得意でしたが、長い間の関係性を学ぶのは苦手でした。例えば、文章の最初の方に出てきた言葉を、文章の最後の方で使う場合、以前の仕組みではうまく繋げることができませんでした。エル・エス・ティー・エムはこの問題を解決するために、特別な記憶装置を組み込みました。
この記憶装置は、まるで人間の脳のように、情報を覚えておき、必要な時に思い出したり、不要な時は忘れたりすることができます。この仕組みのおかげで、エル・エス・ティー・エムは長い間の情報を適切に扱うことができるようになりました。例えば、文章の最初の方で出てきた単語を、文章の最後の方で使う場合でも、エル・エス・ティー・エムはきちんとその単語を覚えており、文の意味を理解するのに役立てることができます。
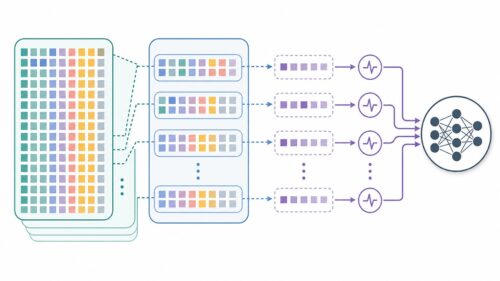
この記憶装置は、情報の出し入れ口となる3つの扉を持っています。1つ目の扉は、新しい情報を記憶装置に入れるための扉です。2つ目の扉は、記憶装置の中の情報を必要な時に取り出すための扉です。3つ目の扉は、記憶装置の中の不要な情報を消すための扉です。これらの扉は、それぞれが状況に応じて開いたり閉じたりすることで、適切な情報を記憶したり、忘れたりすることができます。
この技術は、言葉の翻訳や音声の認識、文章の作成など、様々な場面で利用されています。以前の技術では、長い文章を理解するのが難しかったのですが、エル・エス・ティー・エムを使うことで、より複雑な言葉の理解が可能になりました。また、エル・エス・ティー・エムは、時間の流れに沿って変化するデータの分析にも役立ちます。過去のデータから未来を予測する必要がある場合、エル・エス・ティー・エムは長い間の傾向を捉え、より正確な予測をすることができます。例えば、お金の市場の予測や天気の予測、商品の需要予測など、様々な分野でエル・エス・ティー・エムは活用されています。エル・エス・ティー・エムの登場は、人工知能の進化における大きな一歩であり、これからの更なる発展が期待されます。