TabTransformerとは?表形式データをTransformerで扱う仕組みと使いどころ
TabTransformerとは?表形式データをTransformerで扱う仕組みと使いどころ AIの初心者 TabTransformerという言葉を見ました。画像や文章ではなく、表のデータにもTransformerを使うのですか? AI専...
記事数:(567)
 アルゴリズム
アルゴリズム  アルゴリズム
アルゴリズム  学習
学習  学習
学習  学習
学習  学習
学習  学習
学習  アルゴリズム
アルゴリズム  学習
学習 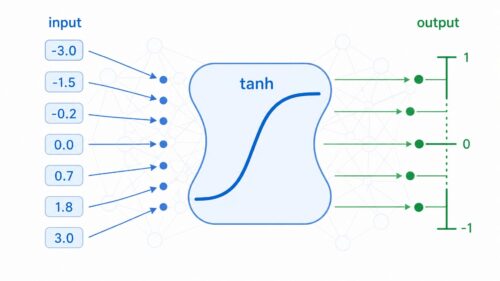 アルゴリズム
アルゴリズム 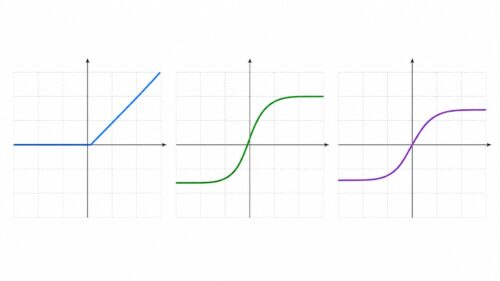 アルゴリズム
アルゴリズム 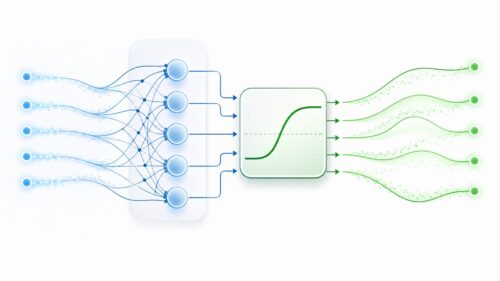 アルゴリズム
アルゴリズム  学習
学習  開発環境
開発環境  学習
学習  学習
学習  アルゴリズム
アルゴリズム  AIサービス
AIサービス  学習
学習  AIサービス
AIサービス  アルゴリズム
アルゴリズム  アルゴリズム
アルゴリズム