学習
学習 大域最適解とは?局所最適解との違いと機械学習での考え方
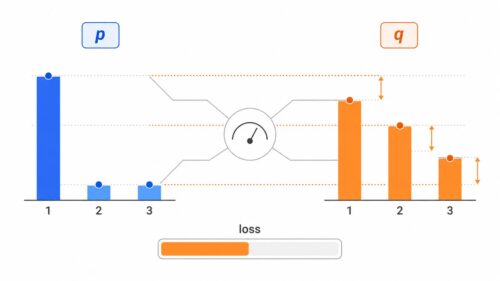
機械学習では、学習の目的は最適な型を見つけることです。この型は、様々な情報を最も良く表すことができる形をしています。最適な型を探す過程で、私達は「最適解」と呼ばれる数値の組み合わせを探し当てます。この最適解には、大きく分けて二つの種類があります。
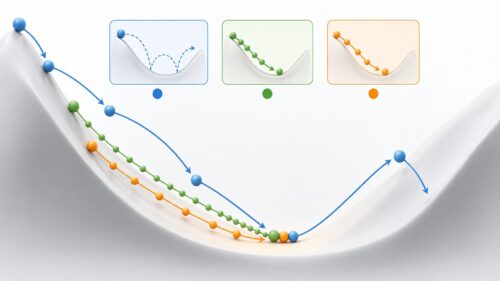
一つ目は「局所最適解」です。山の頂上を想像してみてください。もし、私達が山の斜面の途中に立っていて、そこから見える範囲で最も高い場所を探すとします。すると、その地点が頂上のように見えるかもしれません。しかし、山の全体像を見渡すと、さらに高い頂上が存在する可能性があります。局所最適解とは、まさにこのような状態です。ある狭い範囲で見ると最適に見えますが、全体で見ると、もっと良い解が存在するかもしれないのです。例えば、ある商品の値段を決める際に、過去の販売データの一部だけを見て最適な価格を決めると、局所最適解に陥る可能性があります。他の時期のデータや、競合商品の価格なども考慮することで、より良い価格設定、つまりより良い解が見つかるかもしれません。
二つ目は「大域最適解」です。これは、山の全体像を見て、本当に一番高い頂上を見つけた状態です。つまり、これ以上良い解は存在しない、真の最適解です。全ての情報を考慮し、あらゆる可能性を検討した結果、最も良いと判断される解です。先ほどの商品の値段の例で言えば、あらゆるデータを分析し、あらゆる可能性を検討した結果、最も利益が見込める価格が、大域最適解となります。機械学習の最終目標は、まさにこの大域最適解を見つけることです。しかし、大域最適解を見つけることは、非常に難しい問題です。複雑な地形を想像してみてください。数え切れないほどの山や谷があり、その中で一番高い山を見つけるのは容易ではありません。同様に、複雑なデータやモデルでは、大域最適解を見つけるのは至難の業です。様々な工夫や探求が必要となります。