アルゴリズム
アルゴリズム ロジスティック回帰入門
統計や機械学習の世界で、ある出来事が起こる見込みを計算する時に、ロジスティック回帰という方法がよく使われます。これは、色々な要因を元に、例えば、お客さんが商品を買う見込みや、病気を診断する見込みなどを予測するのに役立ちます。
ロジスティック回帰は、いくつかの入力データと、予測したい事柄との関係を、数式で表します。入力データは、説明するもの、つまり説明変数と呼ばれます。そして、予測したい事柄は、目的変数と呼ばれます。具体的には、説明変数を組み合わせて計算した結果を、特別な関数に通すことで、見込みの値を計算します。この特別な関数は、ロジスティック関数と呼ばれ、計算結果は必ず0から1の範囲におさまります。この0から1の範囲は、ちょうど見込みとして解釈できる範囲です。例えば、0は全く起こらない、1は必ず起こる、0.5は五分五分の見込みを表します。
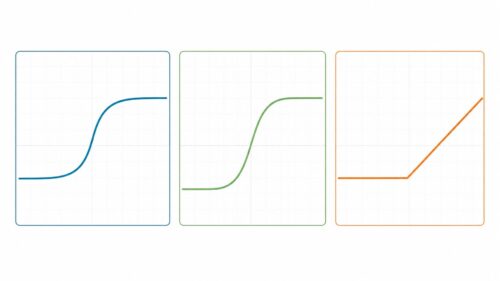
ロジスティック関数の特徴は、S字のような曲線を描くことです。入力データの値が小さいうちは、見込みもゆっくりと上がっていきます。そして、ある点を境に、見込みが急激に上昇し、その後は再びゆっくりと1に近づいていきます。このS字型の曲線のおかげで、ロジスティック回帰は、現実世界でよく見られる、急激な変化や緩やかな変化をうまく捉えることができます。
つまり、ロジスティック回帰は、様々な要因を考慮に入れて、ある事柄の起こる見込みを、0から1の数字で予測する、便利な方法です。この方法は、色々な分野で、データに基づいた判断を助けてくれます。