AIサービス
AIサービス 深層学習:未来を拓く人工知能技術
深層学習とは、人間の脳の仕組みを真似た学習方法をコンピュータにさせる技術です。人工知能の分野で近年著しい進歩を見せており、機械学習という大きな枠組みの中の一つに位置付けられます。
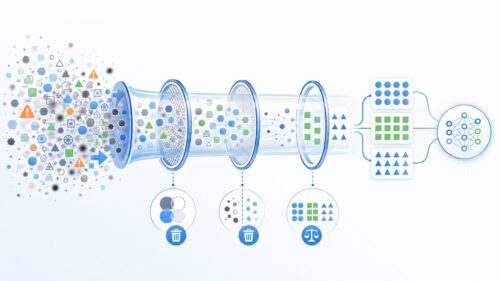
人間の脳には、神経細胞と呼ばれるものが複雑につながり合った神経回路が存在します。深層学習では、この神経回路を模倣した「ニューラルネットワーク」という仕組みを使います。このニューラルネットワークは、幾重にも層が重なった構造をしています。ちょうど、何層にも重ねられたミルフィーユのようなイメージです。この層の多さが「深層」と呼ばれる所以です。
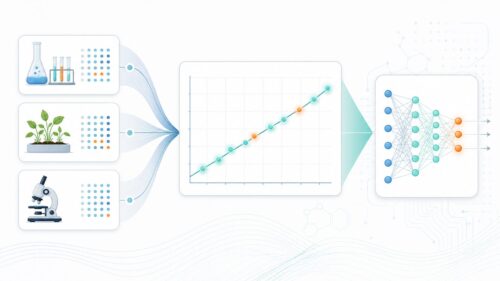
コンピュータはこの多層構造を利用して、大量のデータから複雑なパターンや特徴を見つけ出すことができます。たとえば、たくさんの猫の画像をコンピュータに与えると、コンピュータは自ら「猫の特徴」を学習します。耳の形、目の形、ひげ、毛並みなど、様々な特徴を捉え、最終的に「これは猫だ」と判断できるようになるのです。
従来の機械学習では、人間がコンピュータに「猫の特徴」を教え込む必要がありました。たとえば、「とがった耳」「丸い目」といった具合です。しかし、深層学習では、コンピュータが自ら特徴を見つけるため、人間の手間が省けるだけでなく、より複雑な問題にも対応できるようになりました。
深層学習は、画像を見分ける、音声を聞き取る、言葉を理解するといった様々な分野で活用されています。例えば、写真のどこに人が写っているかを自動的に判断したり、人間の声を文字に変換したり、外国語を翻訳したりといったことが可能になります。深層学習は多くのデータと高い計算能力を必要としますが、その精度は人間に匹敵、あるいは人間を超えるほどになってきています。まさに、未来を担う技術と言えるでしょう。