学習
学習 機械学習における繰り返し学習とは?イテレーションの意味と重要性を解説
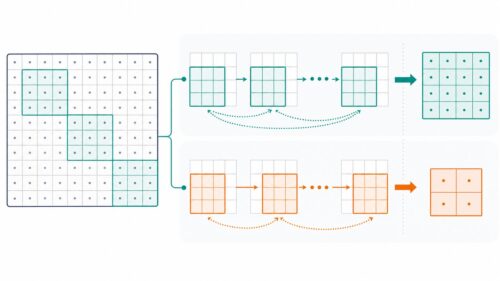
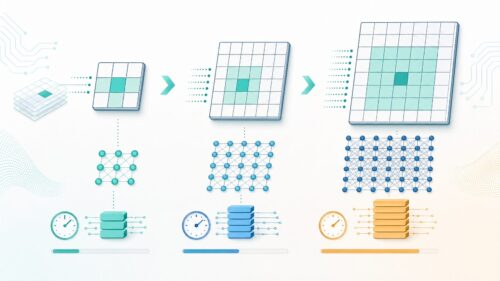
機械学習とは、多くの情報から規則性や法則を見つけ出す技術であり、今の世の中で広く使われています。この技術の中心となる考えの一つに「繰り返し学習」というものがあります。これは「イテレーション」とも呼ばれ、学習の工程を何度も繰り返すことで、予測の正確さを高める方法です。
たとえば、犬と猫を見分ける機械を作るとしましょう。最初に、たくさんの犬と猫の写真と、それぞれが犬か猫かの情報を与えます。機械は、写真の特徴(耳の形、鼻の形、毛の色など)と、犬か猫かという情報を結びつける規則を学習します。しかし、最初のうちは、この規則はあまり正確ではありません。そこで、繰り返し学習の出番です。機械は、自分の作った規則で写真を見て、犬か猫かを予測します。そして、その予測が正解かどうかを確認し、間違っていた場合は規則を修正します。この予測と修正を何度も繰り返すことで、規則はどんどん正確になり、犬と猫を見分ける能力が高まっていきます。
このように、繰り返し学習は、機械学習において非常に重要な役割を担っています。一度に完璧な規則を作ることは難しいため、試行錯誤を繰り返すことで、徐々に精度を高めていく必要があるのです。繰り返し学習は、まるで職人が技術を磨くように、機械が学習し成長していく過程と言えるでしょう。繰り返し学習を行う回数や、一回ごとの修正の大きさなどは、学習の目的に合わせて調整する必要があります。適切な設定を行うことで、より効果的に機械学習モデルの性能を高めることが可能になります。