AIサービス
AIサービス おすすめ機能の仕組みとは?意味・活用例・注意点をわかりやすく解説
インターネット上で物を買ったり、動画を見たりする時に、「あなたへのおすすめ」と表示されるのを見たことがある人は多いはずです。これを可能にしているのがおすすめ機能、言い換えれば推薦エンジンです。この技術は、たくさんの商品や情報の中から、一人ひとりの利用者の好みに合うものを選び出し、見せることで、より快適なインターネット体験を実現しています。
例えば、インターネット上の販売サイトで以前買った物と似た物や、一緒に買われることが多い関連商品を表示します。また、動画配信サービスでは、過去の視聴履歴に基づいたおすすめ作品を紹介するなど、様々な場面で使われています。
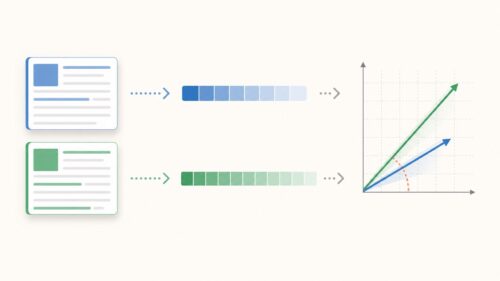
このおすすめ機能は、大きく分けて二つの方法で実現されています。一つ目は、利用者の行動履歴に基づいておすすめするやり方です。例えば、過去にどんな商品を買ったか、どんな動画を見たかといった情報から、利用者の好みを推測し、似た商品や関連性の高い商品、作品などを提示します。
二つ目は、他の利用者との類似性に基づいておすすめする方法です。例えば、あなたと似たような商品を買っている他の利用者が他にどんな商品を買っているかという情報から、あなたにも気に入りそうな商品を予測して表示します。
このように、おすすめ機能は複雑な計算を裏側で行いながら、一人ひとりに合った情報を届けることで、インターネット上での買い物をより楽しく、便利な物にしてくれています。膨大な情報の中から自分に合った物を見つけ出す手間を省き、新しい発見をもたらしてくれるおすすめ機能は、まさに現代のインターネットサービスには欠かせない物と言えるでしょう。