アルゴリズム
アルゴリズム Atrous畳み込みとは?穴あき畳み込みの仕組みと使いどころを解説
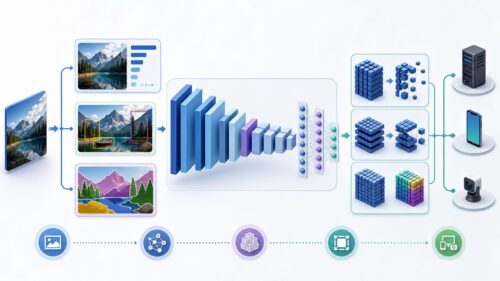
絵や写真などの画像を機械で扱う技術において、拡張畳み込みは重要な役割を果たします。これは、網目状の計算機部品(フィルター)を画像の上で滑らせながら、画像の特徴を捉える方法です。
通常の畳み込みでは、フィルターの網目は隙間なく詰まっており、画像の狭い範囲しか一度に見ることができません。まるで虫眼鏡で一部分を拡大して見ているようなものです。これに対して、拡張畳み込みはフィルターの網目に隙間を作ることで、一度に広い範囲を見渡せるように工夫されています。
この隙間の大きさを調整することで、見える範囲の広さを変えることができます。隙間の大きさを表す数値を「割合」と呼びます。割合が1であれば、通常の畳み込みと同じように、網目の隙間は無く、狭い範囲しか見ることができません。割合が2になると、網目の要素の間に1つ分の隙間ができます。割合が3になると、2つ分の隙間ができます。このように、割合の数値が大きくなるにつれて、見える範囲は広がっていきます。
フィルターの実際の大きさを変えずに、見える範囲を広げられることが、拡張畳み込みの大きな利点です。これは、広い範囲の情報を取り入れつつ、細かい部分も見逃さないようにする上で、とても役立ちます。
例えば、写真の風景の中に小さく写っている鳥を見つけたい場合、通常の畳み込みでは鳥を見つけるのが難しいかもしれません。しかし、拡張畳み込みを使えば、広い範囲を見渡せるので、小さな鳥も見つけることができます。また、鳥の種類を特定するために、くちばしや羽の色といった細かい特徴も同時に捉えることができます。このように、拡張畳み込みは、画像の中から必要な情報を見つけ出すための強力な道具なのです。