 アルゴリズム
アルゴリズム 交差エントロピーとは?意味・計算・損失関数としての使い方をわかりやすく解説
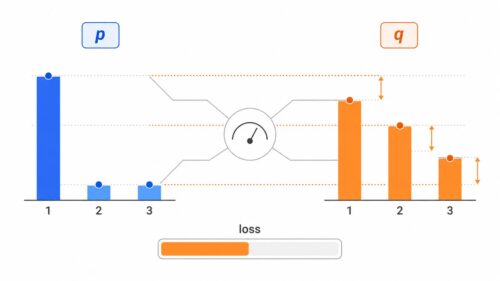
交差エントロピーは、機械学習、とりわけ分類問題において、予測の良し悪しを測るための重要な指標です。真の答えと、機械学習モデルが予測した答えとの間の隔たりを数値で表すことで、モデルの性能を測ります。
具体的には、この隔たりを計算するために、真の答えを表す確率分布と、モデルが予測した確率分布を用います。真の答えが「確実」ならば確率は1、そうでなければ0といった値になります。一方、モデルは「確実」といった予測はせず、ある程度の確信度をもって予測を行います。例えば、ある画像が「犬」である確率を0.8、「猫」である確率を0.2と予測するかもしれません。
交差エントロピーは、真の確率と予測確率の対数を取り、それらを掛け合わせたものを全ての可能な答えについて足し合わせ、最後に負の符号をつけた値です。数式で表現すると少し複雑ですが、重要なのはこの値が小さいほど、モデルの予測が真の答えに近いということです。
例えば、画像認識で犬の画像を猫と間違えて分類した場合、交差エントロピーの値は大きくなります。これは、モデルの予測が真の答えから大きく外れていることを示しています。逆に、正しく犬と分類できた場合、交差エントロピーの値は小さくなります。これは、モデルが「犬」であるという高い確信度で予測し、真の答えとも一致しているためです。
このように、交差エントロピーはモデルの学習において、最適な設定を見つけるための道しるべとなります。交差エントロピーを小さくするようにモデルを調整することで、より正確な予測ができるモデルを作り上げることができるのです。