 学習
学習 教師あり学習とは?意味・仕組み・活用例を初心者向けに解説
機械学習は、データから規則性やパターンを自動的に見つけ出す技術であり、様々な分野で応用されています。大きく分けて三つの種類に分類され、それぞれ異なる目的と手法を持っています。
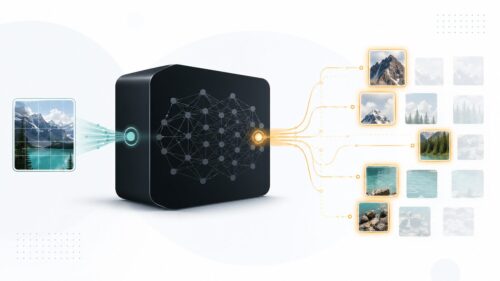
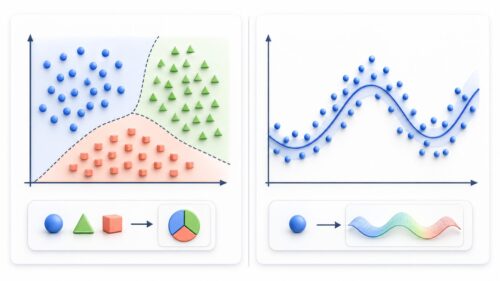
一つ目は、教師あり学習です。教師あり学習は、まるで先生に教わる生徒のように、正解となるデータ(教師データ)を与えられて学習を進めます。例えば、画像に写っているものが「猫」か「犬」かを判断する問題では、予め「猫」の画像には「猫」、「犬」の画像には「犬」というラベルを付けて学習させます。たくさんのラベル付きデータを読み込むことで、機械は画像の特徴とラベルの関係性を学習し、新しい画像を見せられた際に、それが「猫」か「犬」かを正しく判断できるようになります。このように、教師あり学習は、入力データと出力データの関係を学習し、未知の入力データに対して適切な出力データを予測することを目的としています。
二つ目は、教師なし学習です。教師なし学習では、正解となるデータは与えられません。まるで宝探しのようで、データの山の中から隠された宝、すなわちデータの構造や特徴を自ら探し出すことが目的となります。例えば、顧客の購買履歴データから顧客をグループ分けする際に、あらかじめグループの正解は分かりません。しかし、購買履歴の類似性に基づいて顧客をグループ分けすることで、それぞれのグループの特徴を把握し、効果的な販売戦略を立てることができます。このように、教師なし学習は、データの背後にある隠れた構造やパターンを発見することを目的としています。
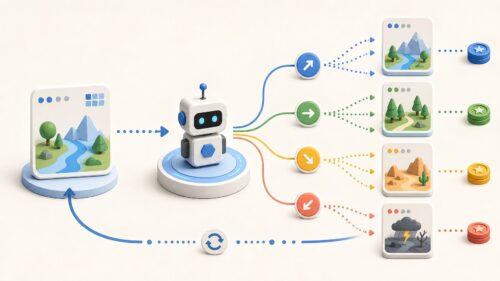
三つ目は、強化学習です。強化学習は、試行錯誤を通じて、目的とする行動を学習する方法です。ゲームで高得点を目指すことを想像してみてください。最初はランダムな行動をとりますが、成功した行動には報酬が与えられ、失敗した行動には罰が与えられます。これを繰り返すことで、機械は報酬を最大化する行動を学習していきます。ロボットの制御やゲームAIなどに活用されており、試行錯誤を通して最適な行動戦略を学習することを目的としています。
このように、機械学習は様々な手法があり、解決したい問題に応じて適切な手法を選択することが重要です。