学習
学習 ブートストラップサンプリングで精度向上
機械学習という技術は、まるで職人が経験から技術を磨くように、与えられた情報から規則性やパターンを見つけ出すことを得意としています。しかし、良い職人になるには豊富な経験が必要なように、機械学習でも大量の情報が必要です。もし経験が不足していたら、職人は特定の状況にしか対応できない、偏った技術しか持てないかもしれません。機械学習でも同じことが起こり、限られた情報だけで学習すると、特定のデータに過剰に適応し、未知の情報に対応できない、いわゆる「過学習」という状態に陥ってしまいます。
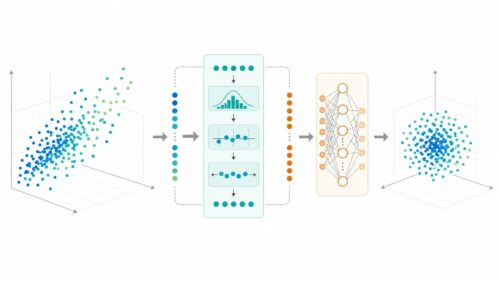
このような問題に対処するため、限られた情報をうまく活用する技術が求められています。その中で、「ブートストラップサンプリング」という手法は、少ない情報から多くの学びを得るための、まるで魔法のような技術と言えるでしょう。これは、元々持っている情報を何度も繰り返し活用することで、あたかも多くの情報を持っているかのような効果を生み出す方法です。具体的には、持っている情報の中から、重複を許してランダムに情報を抜き出し、新しい学習用のデータを作ります。これを何度も繰り返すことで、様々なバリエーションの学習データが作られます。
ブートストラップサンプリングを使う利点は、少ない情報でも、その情報に含まれる様々な特徴を捉え、偏りを減らすことができる点です。一部分だけの情報に囚われず、全体的な傾向を掴むことができるので、新しい情報に対しても、より正確な予測を行うことが可能になります。これは、職人が様々な経験を積むことで、どんな状況にも対応できるようになるのと似ています。
特に情報量が限られている場合、この手法は大きな効果を発揮します。ブートストラップサンプリングは、様々な機械学習の方法と組み合わせて使うことができ、限られた情報からでも頑健で信頼性の高い予測モデルを作るための、強力な道具と言えるでしょう。