AI活用
AI活用 パターン認識:コンピュータの眼
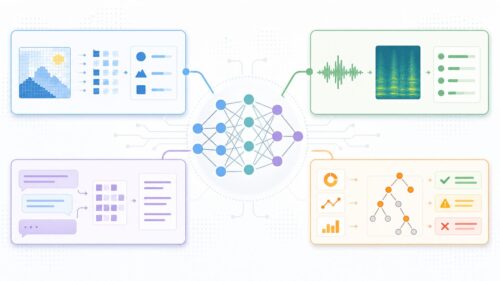
近年、計算機がまるで人のように物事を理解し、判断する技術が急速に発展しています。中でも、目に見えるものや耳に聞こえる音を人のように認識する技術は、大変な注目を集めています。この技術の土台となるのが「模様認識」です。模様認識とは、複雑に入り混じった情報の中から、ある規則や意味を持つものを見つけ出す作業のことを指します。
たとえば、写真に写っている大勢の人の中から特定の顔を見分ける顔認証システムや、雑踏の中でも特定の人物の声を聞き分ける音声認識システムなどは、この模様認識の技術を応用したものです。模様認識の仕組みは、まず認識したい対象の様々な特徴を計算機に学習させ、それをもとに未知のデータの中から似た特徴を持つものを探し出すというものです。
写真の認識を例に考えてみましょう。計算機に「猫」を認識させたい場合、たくさんの猫の写真を読み込ませ、猫の輪郭、毛並み、耳の形、目の色といった様々な特徴を学習させます。そして、新しい写真が与えられた時、学習した特徴と照らし合わせ、猫の特徴を持つ部分を認識し、「これは猫の写真だ」と判断します。このように、模様認識は膨大なデータの中から特定の模様を見つけ出すことで、計算機がまるで人のようにものを見たり、音を聞き分けたりすることを可能にしているのです。
この模様認識の技術は、すでに私たちの暮らしの様々な場面で活用され始めています。車の自動運転システムでは、周囲の状況を認識し、安全な運転を支援していますし、スマートフォンでも、音声認識によって文字を入力したり、顔認証で画面ロックを解除したりすることができます。今後、模様認識技術はさらに進化し、私たちの生活をより便利で豊かなものにしていくと期待されています。