学習
学習 機械学習時代の到来
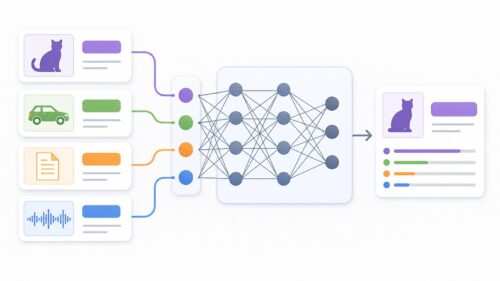
近ごろの技術革新で、おびただしい量の資料が集まるようになりました。例えるなら、広大な図書館に書物が山積みになっている様子を想像してみてください。この莫大な資料の山は、まるで知恵の宝庫であり、人工知能の成長を大きく促す力となっています。人工知能は、この山のような資料を読み解き、そこに隠された知識や規則を見つけ出すことを学びます。まるで名探偵のように、複雑に絡み合った糸を一つ一つ解きほぐし、事件の真相に迫っていくのです。この学ぶ行為こそが、機械学習と呼ばれる技術の核心であり、人工知能を賢くする秘訣なのです。
以前の人工知能は、人間が作った規則に従って動いていました。これは、まるで設計図通りに動く機械のようなものでした。しかし、機械学習では、資料から規則を自ら作り出すことができます。まるで職人が、木材から美しい家具を創造するように、人工知能は資料から新たな知恵を生み出すのです。これにより、人間が細かく指示を出さなくても、人工知能は自ら考え、行動できるようになりました。複雑な問題や大量の資料を扱う場合でも、人間よりも効率的に、そして効果的な解決策を見つけ出せるようになったのです。
この莫大な資料と機械学習の組み合わせは、様々な分野で革新的な変化を起こしています。例えば、医療の分野では、病気の早期発見や新薬の開発に役立っています。また、製造業では、不良品の発生を抑えたり、生産効率を高めたりするために活用されています。さらに、私たちの日常生活においても、より便利なサービスや商品が生まれるきっかけとなっています。まるで魔法の杖のように、私たちの生活をより豊かに、そして便利に変えていく力を持っているのです。