アルゴリズム
アルゴリズム 多層パーセプトロン入門
人間の脳の神経回路の仕組みを真似た計算モデルである、ニューラルネットワークの一種に多層パーセプトロンがあります。これは、ちょうど層が重なったような構造をしています。一番最初の層を入力層、最後の層を出力層と呼び、その間にある層を隠れ層と呼びます。
それぞれの層は、結び目のような役割を果たすノードと呼ばれる単位で構成されており、これらのノードは互いに繋がって情報を伝達します。入力層に入力された情報は、これらのノード間の繋がりを介して隠れ層へと伝わり、そこで何らかの処理が行われます。隠れ層は、入力された情報を処理し、より抽象的な特徴を抽出する役割を担います。そして最終的に、出力層から結果が出力されます。
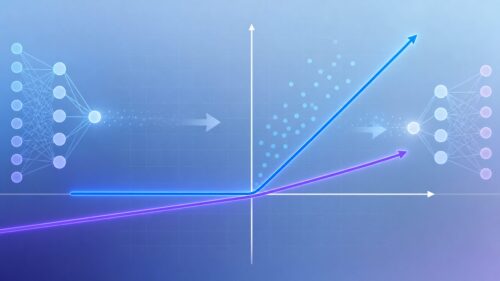
多層パーセプトロンと単純パーセプトロンの違いは、この隠れ層の有無にあります。単純パーセプトロンは入力層と出力層のみで構成されるため、直線で区切れるような単純な問題しか扱うことができません。しかし、多層パーセプトロンでは、隠れ層の存在により、曲線で区切られるような複雑な問題も扱えるようになります。これは、ちょうど複雑に絡み合った糸を解きほぐすように、複雑な情報を整理し、分析することを可能にします。
この複雑な問題を扱えるという特性は、現実世界の問題を解決する上で非常に重要です。例えば、写真に写っているものが何であるかを判断する画像認識や、人間の声を理解する音声認識、そして私たちが日常的に使っている言葉をコンピュータに理解させる自然言語処理など、様々な分野で応用されています。多層パーセプトロンは、まさに現代社会を支える技術の一つと言えるでしょう。