Transformerとは?仕組み・注意機構・活用例を初心者向けに解説
近頃、言葉を扱うコンピュータ技術が急速に発展し、様々な新しい仕組みが生まれています。特に、二〇一七年に発表された「変形器」という仕組みは、これまでの限界を大きく超え、言葉の処理方法に革命を起こしました。
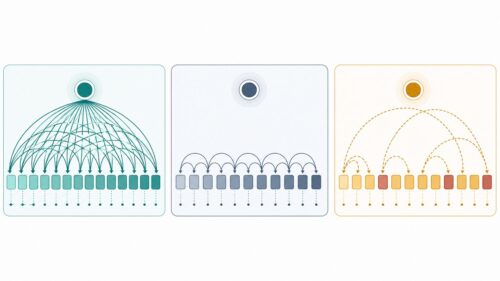
以前は、「繰り返し型神経網」や「畳み込み型神経網」といった仕組みが主流でした。しかし、これらの仕組みでは、長い文章を扱う際に膨大な計算が必要となり、複数の処理を同時に行うのが難しいという問題がありました。「変形器」は、この問題を解決するために、全く新しい設計思想を採用しました。それが、「注意機構」と呼ばれる仕組みです。
「注意機構」とは、文章中の各単語が、他のどの単語と関連が深いかを自動的に判断する仕組みです。例えば、「私は猫が好きです」という文章では、「好き」という単語は「猫」と強く関連し、「私」とはやや関連が薄いと判断されます。従来の仕組みでは、文章を前から順番に処理していくため、離れた単語の関係を捉えるのが苦手でした。一方、「注意機構」は、文章全体を一度に見渡すことができるため、離れた単語の関係も正確に捉えることができます。
この「注意機構」の導入により、「変形器」は、長い文章の処理を効率的に行うことができるようになりました。また、複数の処理を同時に行うことも可能になったため、学習速度も大幅に向上しました。これらの利点から、「変形器」は、機械翻訳、文章要約、質問応答など、様々な自然言語処理のタスクで高い性能を発揮し、今日の言葉処理技術の基盤となっています。まさに、言葉の処理技術における転換点と言えるでしょう。