アルゴリズム
アルゴリズム 標準化とは?データ分析で使う意味・計算方法・正規化との違いを解説
情報をきちんと整えることは、たくさんの情報を扱う上でとても大切な作業です。この作業の一つに標準化というものがあります。標準化は、様々な種類の情報を同じように扱えるようにするための工夫です。
例えば、色々な人の体の大きさを比べるとします。ある人は身長で測り、別の人は体重で測っていては、比べようがありません。標準化は、このようなバラバラな情報を同じ尺度に変換する作業に似ています。
データ分析では、年齢や収入など、様々な種類の情報を扱います。これらの情報は、それぞれ数値の範囲や単位が異なります。例えば、年齢は0歳から100歳くらいまで、収入は数百万円から数億円までと、大きな差があります。このようなデータをそのまま分析に使うと、数値の大きい情報の影響が強くなりすぎて、小さい情報の影響が見えにくくなってしまうことがあります。収入の大きな変動に隠れて、年齢による変化が分かりにくくなる、といった具合です。
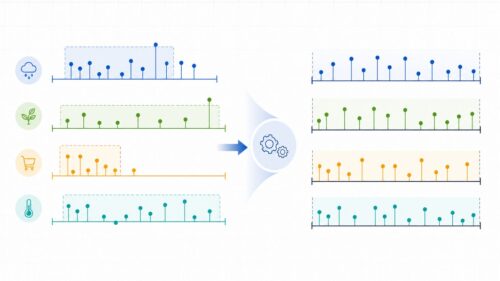
標準化は、この問題を解決する有効な手段です。標準化では、全てのデータを平均0、ばらつき1に変換します。
このように変換することで、年齢や収入といった異なる種類の情報も、同じ土俵で比べることができるようになります。例えるなら、異なる通貨を共通の通貨に換算するようなものです。
標準化は、特に機械学習で重要な役割を果たします。機械学習では、大量のデータからパターンや規則性を自動的に学習しますが、データの尺度や範囲がバラバラだと、学習がうまくいかないことがあります。標準化によってデータを整えることで、機械学習の効率を高め、より正確な結果を得ることができるようになります。
つまり、標準化は、たくさんの情報を扱う際に、それぞれの情報の特性を揃え、分析をスムーズに進めるための重要な下準備と言えるでしょう。