 学習
学習 学習率とは?最適化の鍵になる理由と決め方をわかりやすく解説
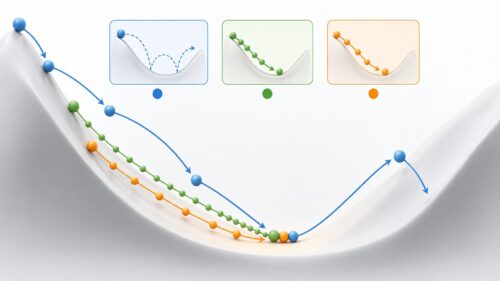
機械学習では、多くの場合、膨大なデータの中から最適な答えを見つけ出す必要があります。これを、複雑な地形をもつ山の頂上から麓の最も低い地点、つまり最適な解を見つけることに例えることができます。この山の斜面を下るように最適な解を探し出す方法の一つに、勾配降下法があります。勾配降下法は、現在の地点から見て最も急な斜面を少しずつ下っていく方法です。
この勾配降下法において、「学習率」は、一歩進む距離、つまり歩幅を調整する重要な役割を担います。学習率が大きすぎると、一歩が大きすぎて最適な解を通り過ぎてしまい、麓にたどり着くどころか、山を登り返してしまうかもしれません。逆に、学習率が小さすぎると、一歩が小さすぎて、なかなか麓にたどり着けません。麓にたどり着くまでに非常に時間がかかってしまうでしょう。
適切な学習率を設定することは、効率的に最適な解を見つけるために不可欠です。最適な学習率は、扱う問題の性質やデータの複雑さによって異なります。一般的には、最初は大きめの学習率を設定し、徐々に小さくしていく方法が用いられます。これは、最初は大きな歩幅で麓のあたりを目指し、近づいてきたら歩幅を小さくして、最適な解を慎重に探るイメージです。
学習率の調整は、機械学習モデルの性能を大きく左右する重要な要素と言えるでしょう。適切な学習率を見つけることで、より早く、より正確に最適な解にたどり着くことができ、モデルの精度向上に繋がります。そのため、様々な学習率を試してみて、モデルの性能を評価しながら、最適な学習率を探索する必要があります。最適な学習率は、機械学習モデルの性能を最大限に引き出すための鍵となるのです。