アルゴリズム
アルゴリズム 画像処理におけるカーネル幅の役割
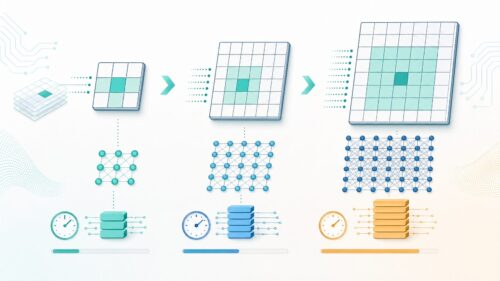
写真の加工や情報の取り出しなど、画像を扱う技術は幅広く使われています。その中で、畳み込み処理は欠かせない技術の一つです。この処理は、写真の一部に小さな升目(フィルタ)を当てはめて計算することで、写真のぼかしや輪郭の強調など様々な効果を生み出します。このフィルタの大きさをカーネル幅と呼びます。カーネル幅の値によって処理結果が大きく変わるため、適切な値を選ぶことが重要です。
畳み込み処理を想像してみてください。一枚の写真全体に、小さな虫眼鏡を動かしながら見ている様子を思い浮かべてください。この虫眼鏡がフィルタにあたり、虫眼鏡で見える範囲がカーネル幅に対応します。もし虫眼鏡の範囲が狭ければ(カーネル幅が小さければ)、写真の細かい部分、例えば小さなシワや点々までくっきりと見えます。逆に虫眼鏡の範囲が広ければ(カーネル幅が大きければ)、細かい部分はぼやけて、全体的な明るさや色の変化が分かります。
カーネル幅が小さい場合は、写真の細かい部分に反応しやすいため、輪郭を強調したり、小さな傷を検出するのに役立ちます。しかし、写真全体にノイズ(ざらつき)が多い場合は、そのノイズも強調されてしまうため、注意が必要です。一方、カーネル幅が大きい場合は、写真全体の傾向を捉えやすいため、ぼかし効果を加えたり、ノイズを軽減するのに適しています。しかし、細かい情報は失われやすいため、輪郭がぼやけてしまう可能性があります。
このように、カーネル幅は画像処理の結果に大きな影響を与えます。そのため、目的とする処理に合わせて適切な値を選ぶことが大切です。例えば、写真のノイズを取り除きたい場合は、カーネル幅を大きく設定します。逆に、写真の輪郭を強調したい場合は、カーネル幅を小さく設定します。最適なカーネル幅は、処理対象の写真の内容や求める効果によって変わるため、試行錯誤しながら見つける必要があります。