アルゴリズム
アルゴリズム 自動生成で高精度を実現:NASNet
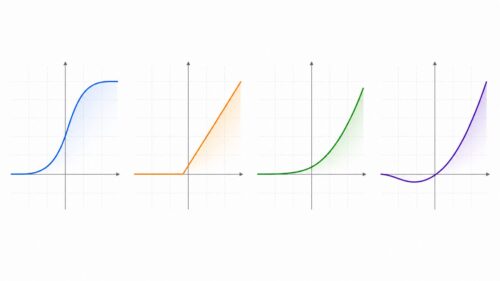
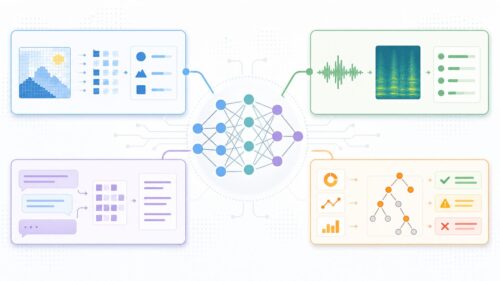
人工知能による設計とは、人の手を介さずに機械が自ら学習し、設計を行う技術のことです。この革新的な技術によって、これまで人間が担ってきた設計作業を自動化できるようになりました。具体的には「神経構造探索網」(NASNet)という手法が用いられています。これは「自動機械学習」(AutoML)という、画期的な手法の一つです。
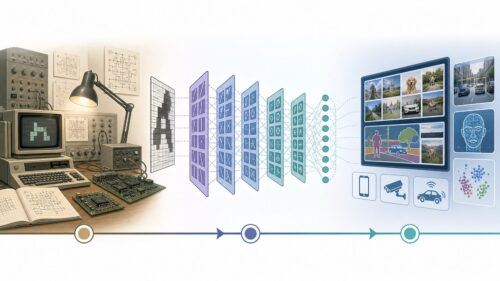
従来、神経回路網の構造は、専門知識を持つ技術者が設計していました。この作業は高度な専門知識と経験に加え、多くの時間と労力を必要とするものでした。しかしNASNetの登場により、この複雑な設計作業を機械が自動で実行できるようになりました。NASNetは、膨大な量のデータから最適な神経回路網の構造を自動的に探し出し、学習します。そして、人の手による設計よりも優れた性能を持つ神経回路網を作り出すことに成功しました。
この成果は、人工知能が単なる計算処理だけでなく、創造的な作業である設計においても大きな力を発揮できることを示しています。人工知能による設計は、機械学習の枠組みを超えて、様々な分野への応用が期待されています。例えば、建築物の設計や、工業製品の設計など、従来は人間の専門家が担ってきた複雑な設計作業を自動化できる可能性を秘めています。また、人工知能による設計は、人間には思いつかないような斬新な設計を生み出す可能性も秘めており、今後の技術革新を大きく加速させることが期待されます。これまで時間と労力をかけて行われてきた設計作業を効率化できるだけでなく、より高性能で革新的な設計を生み出すことで、様々な産業分野に大きな変革をもたらす可能性を秘めているのです。