 アルゴリズム
アルゴリズム CTCとは?音声認識の仕組みと接続時系列分類をわかりやすく解説
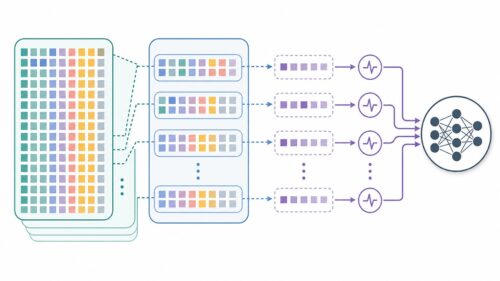
音声認識は、人間と計算機が言葉を介してやり取りする方法を大きく変えました。この技術の中心にあるのが、音の情報を文字の情報に変換する複雑な処理です。音の情報は連続的な波として捉えられますが、文字の情報は一つ一つが独立した記号の列です。この連続と離散という、性質の異なる情報を繋ぐために考案されたのが、つながる時系列分類(CTC)と呼ばれる方法です。
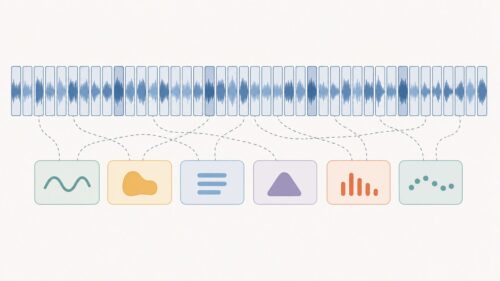
たとえば、「こんにちは」と話したとします。このとき、マイクは空気の振動を捉え、連続的な電気信号に変換します。この電気信号は、時間的に変化する波形として記録されます。一方、「こんにちは」という文字列は、ひらがなという記号が5つ並んだものです。音声認識では、この連続的な波形から、離散的な記号列を正しく取り出す必要があります。
音声を文字に変換する際、音と文字の対応が完全に一致するとは限りません。「こんにちは」を話す速度や間の取り方は人それぞれであり、同じ言葉でも波形の長さは変わります。また、無音部分やノイズも含まれます。従来の方法では、音のデータと文字のデータをあらかじめ同じ長さに揃える必要がありました。しかし、CTCを用いることで、この長さの違いを吸収し、より柔軟に音声認識を行うことができます。
CTCは、音のデータの中に含まれる様々な可能性を考慮し、最も確からしい文字の並びを推定します。たとえば、「こ」という音に対応する部分の波形が少し長くなったとしても、CTCはそれを「こ」と正しく認識することができます。これは、CTCが音のデータと文字のデータの対応関係を学習し、時間的なずれを許容できるためです。このように、CTCは音声認識における重要な技術であり、人間と計算機がより自然に言葉を介してやり取りできる未来を切り開いています。