学習
学習 誤差逆伝播法:学習の要
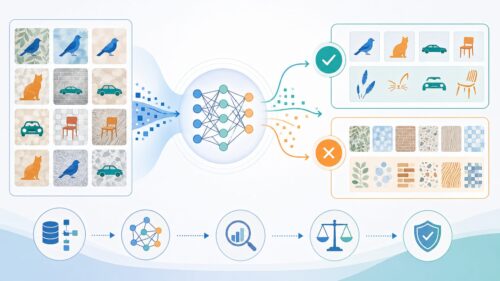
人工知能の世界、とりわけ深層学習と呼ばれる分野では、学習という行為が極めて重要です。これは、私たち人間が経験を通して知識や技能を身につけていく過程とよく似ています。人間が様々な経験を通じて学ぶように、人工知能も大量のデータから学習し、その精度を高めていきます。
この学習過程において中心的な役割を担う技術の一つに、誤差逆伝播法と呼ばれるものがあります。この手法は、いわば人工知能にとっての先生のような存在です。人工知能が出した答えを評価し、正解とのずれ、つまり誤差を計算します。そして、その誤差を基に、人工知能内部の様々な設定値を細かく調整していくのです。
具体的には、人工知能が出力した結果と正解との差を誤差として捉え、この誤差が小さくなるように、出力結果に影響を与える様々な要素を修正します。この修正は、出力層から入力層に向かって、連鎖的に行われます。ちょうど、川の上流から下流へと水が流れるように、誤差情報が入力層に向かって伝播していく様子から、「誤差逆伝播法」と名付けられました。
この誤差逆伝播法のおかげで、人工知能は徐々に正しい答えを導き出す能力を身につけていくのです。まるで、繰り返し練習することでスポーツの技術が上達していくように、人工知能も誤差逆伝播法を通して学習を繰り返すことで、より正確な判断や予測を行うことができるようになります。この学習プロセスは、人工知能が様々な分野で活躍するための基礎となる、非常に重要なものと言えるでしょう。