AIサービス
AIサービス NEC生成AIで変わる未来
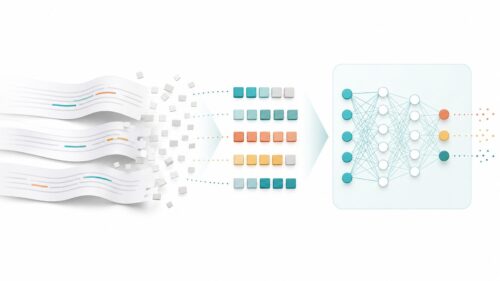
生成人工知能という言葉をご存知でしょうか。これは、文章や画像、音声、プログラムのひな形など、様々な種類の情報を新しく作り出すことができる人工知能のことを指します。これまでの従来型の人工知能は、すでにある情報から規則性を見つけ出し、分類や予測を行うことに主眼が置かれていました。しかし、生成人工知能は、学習した情報を基にして、全く新しい、独創的な情報を作り出すことができます。
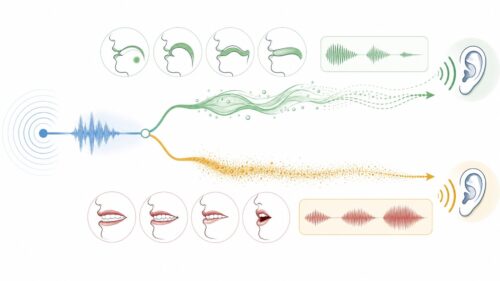
この革新的な技術は、私たちの暮らしや仕事の様々な場面で、大きな変化をもたらすと期待されています。例えば、文章作成の補助、新しいデザインの作成、作曲、そして科学研究など、創造性を必要とする分野において、人間の創造性を支援し、生産性を向上させる強力な道具となるでしょう。
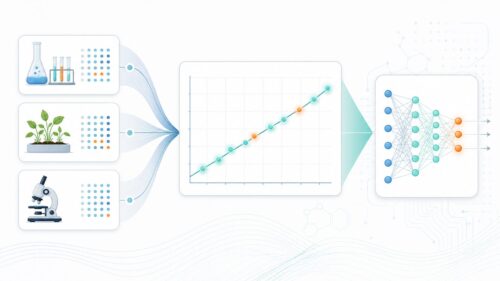
具体的には、作家が小説を執筆する際に、登場人物の性格や物語の展開を生成人工知能に提案してもらうことができます。また、デザイナーが新しい商品のデザインを考える際に、生成人工知能に様々なデザイン案を生成してもらうことも可能です。音楽家も、生成人工知能を使って新しいメロディーやリズムを生み出すことができます。さらに、科学者は、生成人工知能を使って新しい物質の構造や特性を予測することもできるでしょう。
加えて、膨大な量の情報の分析や複雑な模擬実験などを自動化することで、仕事の効率化や新たな発見にも貢献すると考えられています。例えば、企業は生成人工知能を使って顧客の購買行動を分析し、より効果的な販売戦略を立てることができます。また、研究者は生成人工知能を使って複雑な気象現象を模擬し、将来の気候変動を予測することもできるでしょう。このように、生成人工知能は、様々な分野で私たちの生活をより豊かに、そしてより便利にしてくれる可能性を秘めています。まさに未来を形作る技術と言えるでしょう。