学習
学習 学習データ:AIの成長を支える栄養素
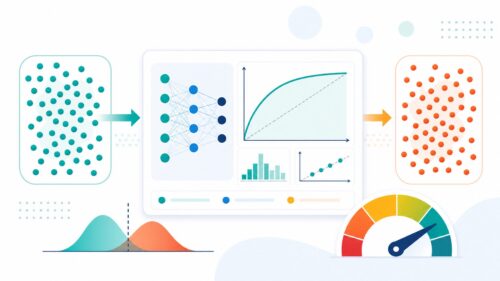
人工知能(じんこうちのう)は、自ら考える機械を作るための技術であり、近年様々な分野で活用が進んでいます。この人工知能を育てるためには、人間が教科書や例題を使って学習するように、大量の情報を与える必要があります。この情報を「学習データ」と呼びます。学習データは、人工知能が特定の作業を学ぶために使われる情報の集まりです。人間が様々な経験を通して知識や技能を身につけるように、人工知能も学習データから様々な規則やパターンを学び、予測や判断を行います。
学習データは、人工知能の成長を支える栄養のようなものです。例えば、写真を見て写っているものが何かを判断する人工知能を訓練するためには、大量の写真とその写真に写っているものが何であるかという情報が必要です。人工知能は、これらの情報から、写真の特定の特徴と写っているものの関係を学習します。この学習を通して、人工知能は未知の写真を見せられた際にも、写っているものを正しく判断できるようになります。
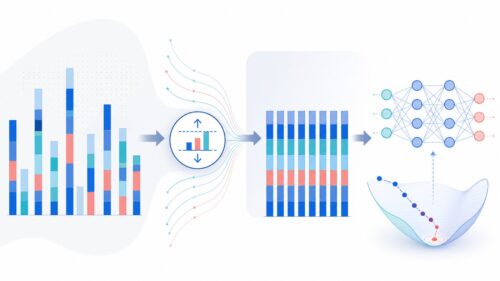
学習データの質と量は、人工知能の性能に大きな影響を与えます。質の高い学習データとは、正確で偏りのない情報で構成されたデータです。もし、学習データに誤りや偏りがあると、人工知能は間違ったことを学習してしまい、期待通りの性能を発揮できません。また、学習データの量も重要です。一般的に、学習データが多いほど、人工知能はより多くのパターンを学習でき、より精度の高い予測や判断を行うことができます。
人工知能の開発において、学習データの準備は非常に重要な工程です。大量のデータを収集し、整理し、人工知能が学習しやすい形に加工する必要があります。この作業には多くの時間と労力がかかりますが、質の高い人工知能を開発するためには欠かせない作業です。今後、人工知能技術の更なる発展に伴い、学習データの重要性はますます高まっていくでしょう。