 アルゴリズム
アルゴリズム 相関係数の基礎知識:正の相関・負の相関・無相関の見分け方
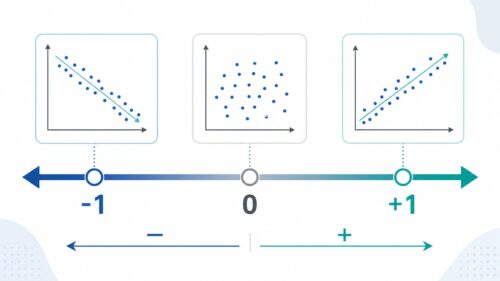
相関係数とは、二つのものの関係の強さを数字で表す方法です。この数字は、-1から1までの範囲で表されます。
1に近いほど、二つのものは同じように変化する関係にあります。例えば、都市の人口とアイスクリームの売上高を考えてみましょう。もし相関係数が1に近い場合、人口が多い都市ではアイスクリームの売上高も高い傾向があり、人口が少ない都市では売上高も低い傾向があることを示しています。つまり、人口が増えると売上高も増え、人口が減ると売上高も減る、同じ方向に変化する関係「正の相関」を示しているのです。
逆に、-1に近いほど、二つのものは反対に変化する関係にあります。運動時間と体重を例に考えてみましょう。もし相関係数が-1に近い場合、運動時間が長い人ほど体重は軽く、運動時間が短い人ほど体重は重い傾向があることを示しています。つまり、運動時間が増えると体重は減り、運動時間が減ると体重は増える、反対方向に変化する関係「負の相関」を示しているのです。
もし相関係数が0に近い場合、二つのものの間にははっきりとした関係がないと考えられます。例えば、靴のサイズと好きな色には、おそらく関係がないでしょう。靴のサイズが大きい人が必ずしも特定の色を好きというわけではないですし、その逆もまた然りです。このような場合は、相関係数は0に近くなります。
相関係数は、様々な分野で活用されています。経済学、社会学、医学など、二つのものの関係性を調べる必要がある場面で、相関係数は重要な役割を果たしています。ただし、相関係数はあくまで二つのものの関係の強さを示すだけで、因果関係(原因と結果の関係)を示すものではないことに注意が必要です。人口とアイスクリームの売上高の例では、人口が多いことがアイスクリームの売上高が高い直接の原因とは限りません。他の要因、例えば気温や所得水準なども影響している可能性があります。相関係数を解釈する際には、このような点に注意することが重要です。