 AIサービス
AIサービス ベクトルストアとは?意味・仕組み・活用例をわかりやすく解説
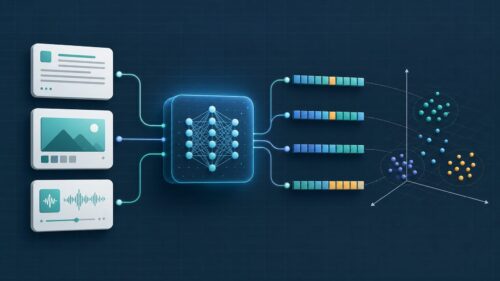
ベクトルストアとは、近年の情報技術の進歩、特に生成系人工知能や自然言語処理といった分野で、なくてはならない技術です。この技術は「ベクトルデータベース」の中核を成し、大量の情報を検索や分析に適した形で保存し、管理するための仕組みを提供します。文章や画像、音声など、様々な種類の情報を数値の列である「ベクトル」に変換して保存する点が、この技術の大きな特徴です。
具体的には、ベクトルは [0.47, -0.12, 0.26, 0.89, -0.71, ...] のように、複数の数値が並んだ形で表現されます。それぞれの数値は、保存された情報の様々な特徴を捉えています。例えば、文章の場合、単語の意味や文脈、感情などが数値に反映されます。画像の場合には、色や形、模様といった視覚的特徴が数値化されます。音声であれば、音の高さや強さ、リズムなどが数値に変換されます。このように情報をベクトル化することで、数値の組み合わせから情報同士の類似性や関連性を把握することが可能になります。
例えば、「りんご」と「みかん」のように意味が近い言葉は、ベクトル空間上で互いに近い場所に配置されます。同様に、「犬」と「猫」も近い位置に配置されるでしょう。一方、「りんご」と「自動車」のように意味がかけ離れた言葉は、ベクトル空間上で遠い場所に位置することになります。このように、ベクトルストアは意味に基づいた情報の活用を可能にするため、従来のデータベースでは難しかった高度な検索や分析を実現できます。例えば、類似した画像の検索や、ある文章に関連する文書の抽出、顧客の好みを反映した商品の推薦など、様々な応用が期待されています。これにより、膨大な情報の中から必要な情報を見つけ出す効率が飛躍的に向上し、私たちの生活はより便利で豊かになるでしょう。
