
鞍点とは?機械学習で学習が停滞する理由と対策

AIの初心者
「鞍点」って、馬の鞍のような形をしているからそう呼ばれているのですか?

AI専門家
その通りです。ある方向から見ると谷底のように低く、別の方向から見ると山頂のように高く見える点なので、馬の鞍にたとえて「鞍点」と呼ばれます。
AIの初心者
形のイメージは分かりました。AIの学習では、なぜそれが問題になるのでしょうか?
AI専門家
機械学習では、誤差が小さくなる方向へパラメータを動かします。鞍点では傾きが小さく見えるため、まだ良い解が別方向にあるのに、学習が進みにくくなることがあるのです。
鞍点とは。
鞍点とは、ある方向では最小値のように見え、別の方向では最大値のように見える点です。機械学習では、誤差関数を小さくする途中で鞍点に近づくと、勾配がほぼゼロになり、学習が止まったように見えることがあります。この記事では、鞍点の意味、勾配降下法で問題になる理由、発生原因、代表的な対策を初心者にも追いやすい順番で整理します。

鞍点とは?機械学習で問題になる理由
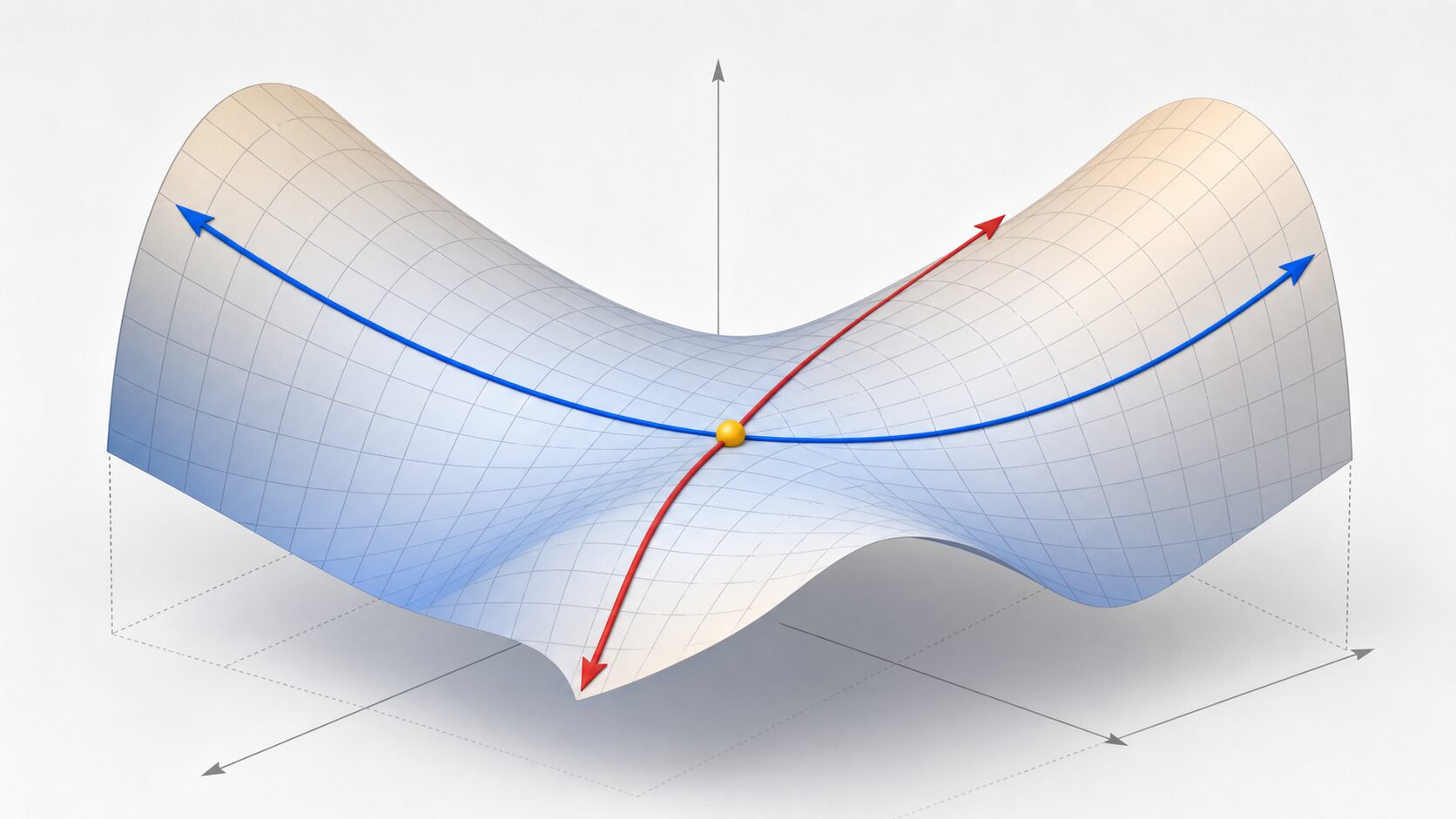
鞍点は、数学や最適化で使われる用語です。名前の通り、馬の鞍の中央のような形を思い浮かべると理解しやすくなります。前後方向に見ると中央は低くへこんでいますが、左右方向に見ると中央は高く盛り上がっています。つまり、同じ点なのに、見る方向によって谷底にも山頂にも見えるのが鞍点です。
機械学習では、モデルの予測と正解のずれを表す誤差関数を小さくするように学習します。ところが、誤差関数の形が複雑になると、真の最小値ではない場所でも傾きが小さくなることがあります。勾配降下法のように傾きを頼りに進む方法では、このような場所で更新が弱くなり、学習が停滞しやすくなります。
そのため鞍点は、単なる数学用語ではなく、深層学習の最適化を理解するうえで重要な概念です。特にパラメータ数が多いニューラルネットワークでは、誤差関数が高次元で複雑になり、鞍点や平坦な領域の影響を受けやすくなります。
鞍点とは何か:谷底と山頂が同居する点

鞍点を直感的に言えば、一方向ではこれ以上低くならないように見え、別方向ではこれ以上高くならないように見える点です。平面上の点ではなく、曲面の上にある点として考えると分かりやすくなります。
例えば、山道の鞍部を考えてみましょう。尾根に沿って進むと、その場所は周囲より低い通過点に見えます。一方で、谷から尾根へ向かって見ると、その場所は周囲より高い地点に見えます。このように、方向によって性質が変わる点が鞍点です。
機械学習の誤差関数でも同じことが起こります。あるパラメータ方向に動かすと誤差が増え、別の方向に動かすと誤差が減る場合、その点は最適解ではありません。しかし、局所的には傾きが小さく見えるため、勾配だけを頼りにしていると進むべき方向を見つけにくくなります。
| 見方 | 鞍点で起こること |
|---|---|
| 谷方向 | 周囲より低く見え、極小値に近い点のように見える |
| 山方向 | 周囲より高く見え、極大値に近い点のように見える |
| 最適化の視点 | 真の最小値ではないのに、勾配が小さくなりやすい |
数式で見る鞍点と勾配の意味
鞍点の代表例として、次のような関数を考えることがあります。
\(f(x, y) = x^2 – y^2\)この関数では、点 \((0, 0)\) の周辺を見ると、\(x\) 方向には下に凸の谷のように振る舞い、\(y\) 方向には上に凸の山のように振る舞います。点 \((0, 0)\) では勾配がゼロになりますが、そこは関数全体の最小値ではありません。
機械学習では、パラメータを \(\theta\)、損失関数を \(L(\theta)\) と置き、勾配降下法ではおおまかに次のように更新します。
\(\theta_{t+1} = \theta_t – \eta g_t\)ここで \(g_t\) は現在の勾配、\(\eta\) は学習率です。勾配 \(g_t\) が非常に小さいと、更新量 \(\eta g_t\) も小さくなります。鞍点付近ではこの更新量が小さくなり、学習がほとんど進んでいないように見えることがあります。
ただし、勾配が小さい場所がすべて鞍点とは限りません。真の極小値、学習率の設定ミス、データのスケール問題、活性化関数の影響などでも、更新が弱くなることがあります。鞍点はその代表的な原因の一つとして理解するとよいでしょう。
機械学習で鞍点が問題になる理由
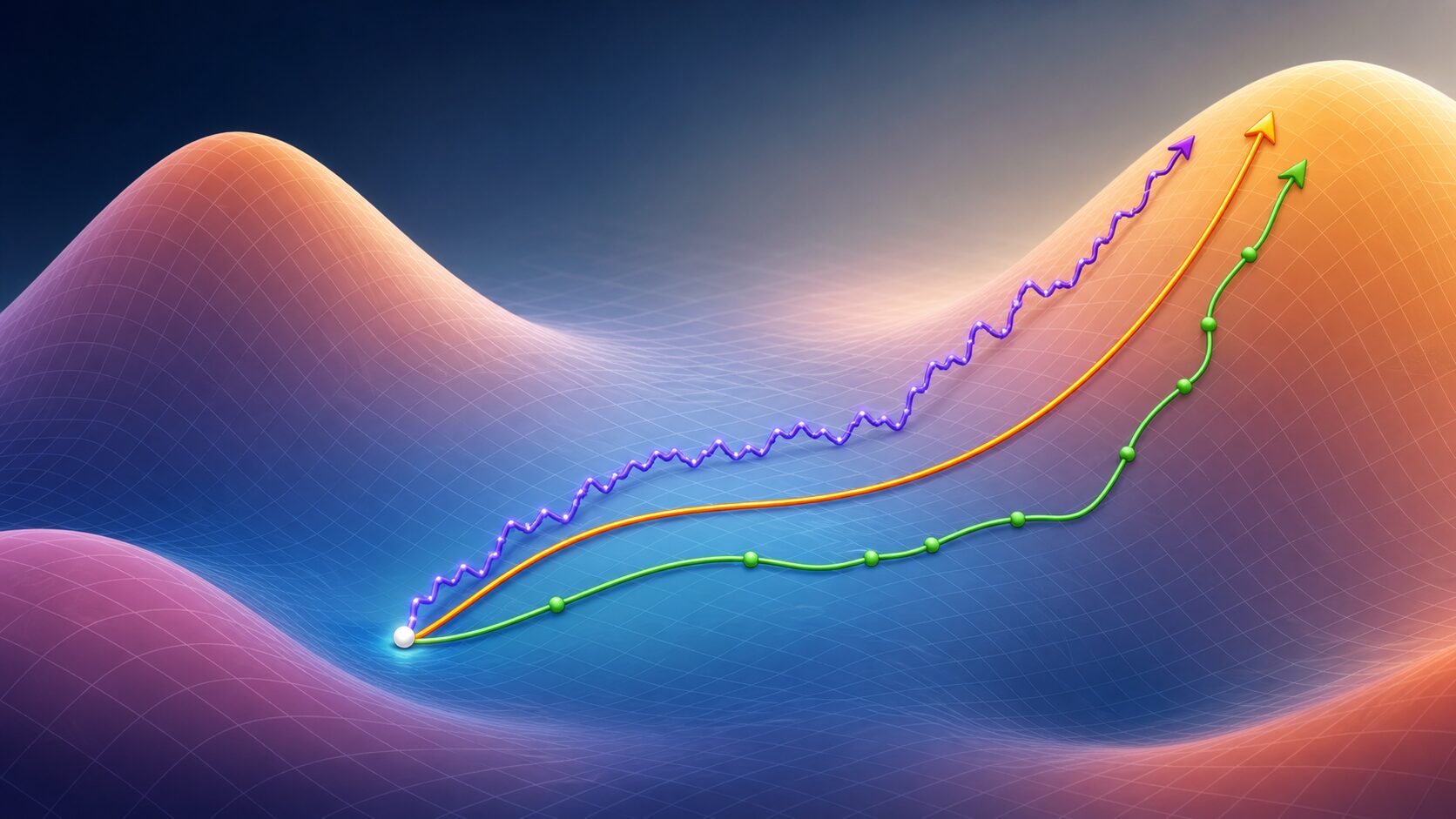
機械学習、とくに深層学習では、多数のパラメータを少しずつ調整して誤差を下げます。このとき、誤差関数の形は単純な谷ではなく、山、谷、平坦な場所が入り混じった複雑な地形のようになります。
勾配降下法は、現在地の傾きを見て「誤差が下がりそうな方向」へ進む方法です。したがって、傾きがはっきりしている場所では更新が進みやすい一方、鞍点や平坦な領域では方向を判断しにくくなります。結果として、モデルがまだ十分に良くなっていないのに、学習の進みが遅くなることがあります。
実務では、鞍点そのものに完全に止まるというより、鞍点の周辺にある平坦な領域で長く足踏みするイメージの方が近い場合もあります。損失は少しずつ下がっているものの改善が非常に遅い、検証精度が伸びない、学習率を変えると急に改善する、といった現象として表れることがあります。
鞍点が発生しやすい原因

鞍点が発生しやすい大きな理由は、モデルが高次元で複雑だからです。深層学習モデルには重みやバイアスなど膨大なパラメータがあり、それぞれの方向に誤差が増えるか減るかを考える必要があります。次元が増えるほど、ある方向では下がり、別の方向では上がるという組み合わせが生じやすくなります。
データの性質も影響します。入力特徴量のスケールがばらばらだったり、データ分布が偏っていたりすると、特定の方向だけ更新が強く、別の方向では更新が弱くなることがあります。その結果、誤差曲面が細長い谷や平坦な場所を含む形になり、最適化が難しくなります。
さらに、初期値、活性化関数、正則化、バッチサイズ、学習率スケジュールなども学習の進み方に関係します。鞍点は単独で発生するというより、モデルの構造、データ、最適化手法が組み合わさって現れる停滞要因として捉えるのが現実的です。
鞍点への主な対策
鞍点による停滞を避けるには、勾配をそのまま使うだけでなく、学習に揺らぎや勢い、パラメータごとの調整を加える方法が有効です。代表的な対策として、SGD、Momentum、RMSprop、Adam などがあります。
SGD は、すべてのデータではなく一部のミニバッチを使って勾配を計算します。このランダム性により、完全に同じ方向へ進み続けるのではなく、鞍点付近から抜け出すきっかけが生まれることがあります。
Momentum は、過去の勾配を蓄積して「勢い」を持たせる方法です。平坦な場所でも、直前まで進んできた方向の情報を使って更新できるため、鞍点や浅い谷を抜けやすくなります。RMSprop や Adam は、勾配の大きさに応じてパラメータごとの学習率を調整し、更新の偏りを抑えるために使われます。
| 手法 | 鞍点対策としての考え方 |
|---|---|
| SGD | ミニバッチのランダム性で停滞から抜け出すきっかけを作る |
| Momentum | 過去の勾配を利用し、平坦な場所でも進む勢いを保つ |
| RMSprop | 勾配の大きさに応じて学習率を調整し、更新の偏りを抑える |
| Adam | Momentum と適応的な学習率調整を組み合わせて効率よく更新する |
ただし、これらの手法を使えば必ず解決するわけではありません。学習率が大きすぎれば発散し、小さすぎれば停滞します。特徴量の標準化、重み初期化、バッチサイズ、正則化、学習率スケジュールも合わせて確認することが重要です。
極小値・停滞領域との違い
鞍点を理解するときは、極小値や平坦な停滞領域との違いも押さえておくと混乱しにくくなります。極小値は、周囲と比べて値が低い点です。真の最小値ではない場合もありますが、少なくとも近くの範囲では谷底といえます。
一方、鞍点は方向によって性質が変わります。ある方向では低い点に見えますが、別の方向へ進めばさらに値を下げられる可能性があります。平坦な停滞領域は、広い範囲で勾配が小さく、どちらへ進んでも変化が分かりにくい領域です。
| 概念 | 特徴 | 学習への影響 |
|---|---|---|
| 極小値 | 近くの範囲では周囲より低い点 | そこで安定しやすいが、全体最小とは限らない |
| 鞍点 | 方向によって谷にも山にも見える点 | 真の最小値ではないのに勾配が小さくなりやすい |
| 停滞領域 | 広い範囲で変化が小さい平坦な場所 | 損失の改善が遅く、学習時間が長くなりやすい |
学習時に確認したい注意点
学習が進まないときに、すぐ鞍点だけを原因と決めつけるのは避けましょう。実際には、学習率が不適切、入力データのスケールがそろっていない、損失関数とタスクが合っていない、バッチサイズが大きすぎる、モデル容量が不足している、といった別の原因もよくあります。
まずは、損失の推移、学習率、訓練データと検証データの差、勾配ノルム、入力の前処理を確認します。損失がまったく下がらないのか、非常に遅く下がっているのかでも判断は変わります。鞍点や平坦な領域が疑われる場合は、学習率スケジュールの見直し、最適化手法の変更、初期値の変更、正規化層の導入などを試すとよいでしょう。
また、深層学習では「鞍点を完全になくす」ことよりも、停滞を短くして十分に良い解へ到達することが重要です。実務では、理論上の最小値よりも、検証データで安定した性能が出るかどうかを重視して判断します。
今後の展望
鞍点問題は、深層学習の最適化を考えるうえで今後も重要なテーマです。大規模モデルではパラメータ数が非常に多く、誤差曲面の形を人間が直接理解することは困難です。そのため、停滞を検知する手法、より安定した最適化アルゴリズム、初期化や正規化の改善が引き続き研究されています。
また、学習を速くするだけでなく、再現性や安定性を高める観点でも鞍点や平坦な領域の理解は役立ちます。どのようなモデル構造やデータ条件で学習が停滞しやすいのかを把握できれば、実験設計やハイパーパラメータ調整の効率も上がります。
今後は、最適化手法そのものの改善に加え、モデル設計、データ前処理、学習監視を組み合わせて、鞍点に左右されにくい学習プロセスを作ることがますます重要になるでしょう。
まとめ
鞍点とは、ある方向では谷底、別の方向では山頂のように見える点です。機械学習では、誤差関数を最小化する途中で鞍点や平坦な領域に近づくと、勾配が小さくなり、学習が停滞しやすくなります。
対策としては、SGD のランダム性、Momentum の勢い、Adam や RMSprop の適応的な学習率調整がよく使われます。ただし、鞍点だけでなく、学習率、初期値、データのスケール、モデル構造も学習停滞の原因になり得ます。鞍点を理解することは、深層学習の最適化をより現実的に見るための重要な一歩です。
更新履歴
| 日付 | 内容 |
|---|---|
| 2025年2月2日 | 初回公開 |
| 2026年6月20日 | 勾配降下法との関係と対策手法の比較を補強 |