機械学習と汎化性能とは?意味・過学習との関係・高め方を解説

AIの初心者
「汎化性能」ってよく聞くんですけど、具体的には何を表す言葉なんですか?

AI専門家
汎化性能とは、学習したデータだけでなく、初めて見るデータにも適切に対応できる能力のことだよ。たとえば多くの猫の写真で学習したAIが、まだ見たことのない猫の写真も「猫」と判断できるか、という力だね。
AIの初心者
学習したものを覚えているだけでは足りなくて、新しいデータにも対応できるかが大事なんですね。
AI専門家
その通り。機械学習モデルは実際の環境で使うために作るものだから、訓練時とまったく同じデータだけに強くても不十分なんだ。だから汎化性能は、モデルの実用性を判断するうえでとても重要になるよ。
汎化性能とは。
機械学習における汎化性能とは、モデルが学習に使っていない未知のデータに対しても、正しく予測や分類を行える能力のことです。汎化性能を理解するには、訓練データとテストデータを分ける理由、過学習が起こる仕組み、モデルを評価するときの注意点をあわせて押さえる必要があります。
汎化性能とは何か
汎化性能とは、学習した機械学習モデルが、初めて見るデータにも適切に対応できる能力です。別の言い方をすると、訓練データの丸暗記ではなく、データに共通する本質的な特徴を学び取れているかを表します。
たとえば、犬の画像をたくさん見せてモデルを学習させたとします。学習後、モデルがまだ見たことのない犬の画像に対しても「犬」と判断できれば、汎化性能が高い状態です。一方で、訓練時に見た画像とほとんど同じものだけを犬と判断し、角度や毛色が少し変わると誤ってしまうなら、汎化性能は低いと考えられます。
この違いは、モデルが「画像そのもの」を覚えたのか、「犬らしさを構成する特徴」を学んだのかの違いです。耳、鼻、輪郭、体の形、背景に左右されにくい特徴などをうまく捉えられれば、未知のデータにも対応しやすくなります。
| 観点 | 意味 |
|---|---|
| 汎化性能が高い状態 | 学習に使っていない新しいデータにも、安定して正しい予測や分類ができる。 |
| 汎化性能が低い状態 | 訓練データには強いが、未知のデータでは誤りやすい。 |
| 評価で見るポイント | 訓練データではなく、学習に使っていないデータでどれだけ性能を保てるか。 |
なぜ機械学習で汎化性能が重要なのか
機械学習の目的は、手元のデータに対してだけ良い結果を出すことではありません。実際には、将来入力される新しいデータ、別の環境で集められたデータ、少し条件が変わったデータに対して予測や判断を行います。そのため、実運用で役立つモデルかどうかは、未知のデータにどれだけ強いかで決まります。
医療分野の診断支援を例にすると、モデルは過去の患者データから病気の傾向を学びます。しかし、実際に使われる場面では、年齢、生活習慣、検査値の組み合わせが訓練時とまったく同じ患者ばかりではありません。新しい患者のデータにも適切に対応できなければ、診断支援として信頼しにくくなります。
自動運転でも同じです。天候、道路状況、歩行者の動き、他の車の挙動は常に変化します。特定の晴れた道路だけで高精度に動くモデルより、雨天や夜間、予期しない状況でも判断を大きく崩さないモデルのほうが実用的です。
| 分野 | 汎化性能が必要な理由 |
|---|---|
| 医療 | 初めて見る患者の検査値や症状にも、過去データから得た知識を応用する必要がある。 |
| 自動運転 | 天候や交通状況が変わっても、安全な判断を続ける必要がある。 |
| 需要予測 | 過去と完全には同じでない季節要因、流行、外部環境の変化に対応する必要がある。 |
訓練データとテストデータで汎化性能を測る
汎化性能を正しく測るには、学習に使う訓練データと、評価に使うテストデータを分けることが欠かせません。これは、教科書の例題で練習したあと、別の問題で理解度を確認するのに似ています。
訓練データは、モデルが規則性や特徴を学ぶためのデータです。モデルは訓練データを使って、入力と正解の関係、数値の傾向、画像や文章の特徴などを学習します。一方、テストデータは、学習が終わったモデルの性能を確認するために使うデータです。テストデータは学習に使わないため、未知データへの対応力を測る材料になります。
もしテストデータを訓練に混ぜてしまうと、モデルはすでに知っている問題で高得点を取っているだけかもしれません。この場合、表示される精度は高くても、実際の汎化性能を正しく表していない可能性があります。特に初心者は、訓練データでの精度だけを見て「良いモデル」と判断しないよう注意が必要です。
| データの種類 | 役割 | 注意点 |
|---|---|---|
| 訓練データ | モデルに特徴や規則性を学ばせる。 | ここでの精度だけでは汎化性能は判断できない。 |
| 検証データ | 学習中の設定調整やモデル選択に使う。 | 何度も調整に使うため、最終評価用とは分けるのが望ましい。 |
| テストデータ | 最終的な未知データへの対応力を確認する。 | 学習や細かな調整に使わない。 |
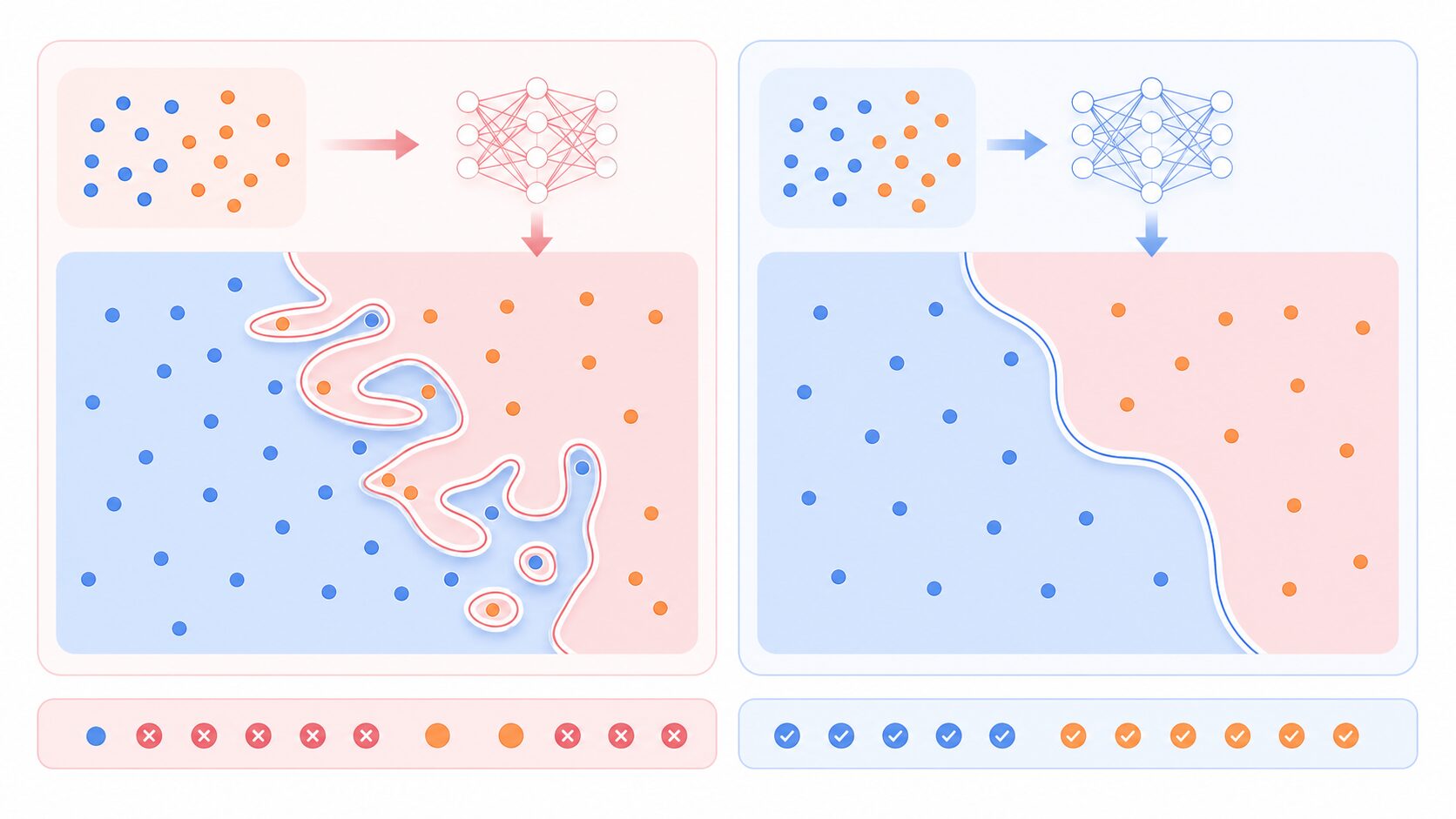
過学習が汎化性能を下げる理由
汎化性能を考えるときに避けて通れないのが、過学習です。過学習とは、モデルが訓練データに過剰に適応し、細かな偶然やノイズまで覚えてしまう状態を指します。訓練データでは高い精度を出せるのに、新しいデータでは性能が落ちる場合、過学習が疑われます。
人間の学習に例えるなら、教科書の例題を一字一句丸暗記している状態です。同じ問題なら答えられますが、少し表現が変わった応用問題には対応しにくくなります。機械学習でも、モデルが本質的なパターンではなく訓練データ固有の細部を覚えると、未知データへの対応力が弱くなります。
過学習を防ぐ代表的な方法には、正則化、交差検証、データの見直し、モデルの複雑さの調整があります。正則化はモデルが複雑になりすぎるのを抑える考え方で、交差検証はデータの分け方を変えながら性能を確かめる方法です。どちらも、訓練データだけに都合のよいモデルになっていないかを確認するために役立ちます。
| 状態 | 訓練データでの性能 | 未知データでの性能 |
|---|---|---|
| 適切に学習できている | 高い | 大きく崩れにくい |
| 過学習している | 非常に高い | 低くなりやすい |
| 学習不足 | 低い | 低い |
汎化性能を高めるための基本手順
汎化性能は、単にモデルを大きくしたり、学習回数を増やしたりすれば高まるものではありません。データの質、モデルの選び方、評価方法、設定値の調整を組み合わせて改善していく必要があります。
まず重要なのは、データの前処理です。不要な情報を取り除く、欠損値を扱う、外れ値を確認する、入力形式をそろえるといった作業によって、モデルが学びやすい状態を作ります。データに誤りや偏りが多いと、どれだけ高度なモデルを使っても汎化性能は安定しにくくなります。
次に、目的に合ったモデルを選びます。画像分類、数値予測、文章分類、時系列予測では、適したモデルや評価指標が異なります。たとえば分類問題では正解率だけでなく、適合率や再現率を確認したほうがよい場合があります。特に見逃しが重大な問題では、全体の正解率が高くても十分とは限りません。
さらに、検証データを使って設定値を調整し、必要に応じて正則化や交差検証を取り入れます。学習結果を見ながら改善を繰り返すことで、訓練データにだけ強いモデルではなく、実際の環境でも使いやすいモデルに近づけられます。
| 取り組み | 目的 |
|---|---|
| データの前処理 | ノイズや欠損を整理し、モデルが学びやすい入力にする。 |
| 適切なデータ分割 | 訓練、検証、テストの役割を分けて、評価の信頼性を保つ。 |
| 正則化 | モデルの複雑さを抑え、訓練データへの過剰適応を防ぐ。 |
| 交差検証 | データの分け方に依存しすぎない性能確認を行う。 |
| 評価指標の使い分け | 正解率だけでなく、課題に合った指標でモデルを判断する。 |
まとめ
汎化性能とは、機械学習モデルが初めて見るデータにも対応できる能力です。訓練データで良い結果を出すだけでは不十分で、テストデータや実運用に近いデータでも性能を保てるかが重要になります。
汎化性能を理解するうえでは、訓練データとテストデータを分ける理由、過学習が起こる仕組み、正則化や交差検証の役割を押さえることが大切です。モデルの実用性は、学習済みデータへの強さではなく、未知のデータに対する安定した判断力によって評価されます。
機械学習を学ぶときは、精度の数値だけを見るのではなく、その精度がどのデータで測られたものなのかを確認しましょう。そこを意識できると、汎化性能の高いモデルを作るための考え方が身につきやすくなります。
更新履歴
| 日付 | 内容 |
|---|---|
| 2025年2月2日 | 初回公開 |
| 2026年5月21日 | 過学習やデータ分割との関係を補い、評価の流れを追いやすく更新 |