音声認識のCTCとは?意味・仕組み・活用例をわかりやすく解説

AIの初心者
「CTC」って、音声認識ではどんな仕組みなんですか?

AI専門家
CTCは、音声の長さと文字の長さがぴったり合わないときでも、音の並びから正しい文字列を学習しやすくする技術だよ。「こんにちは」が少し伸びたり繰り返されたりしても、最終的に「こんにちは」と扱えるようにするんだ。
AIの初心者
音が伸びたり余計に出たりしても、どうして同じ言葉だと判断できるんですか?
AI専門家
各時刻で出そうな音や空白を確率で見て、繰り返しや無音を整理してから文字列にするからだよ。例えば「heello」や「he_llo」のような途中結果も、最終的には「hello」に対応する候補として扱えるんだ。
CTCとは。
CTCは「Connectionist Temporal Classification」の略で、日本語では「接続時系列分類」と呼ばれます。音声認識では、入力される音声フレームの数と、出力したい文字や音素の数が一致しないことがよくあります。CTCはこのずれを扱い、音声データから最も自然な文字列を直接学習・推定するための手法です。
CTCとは?音声認識で使われる接続時系列分類
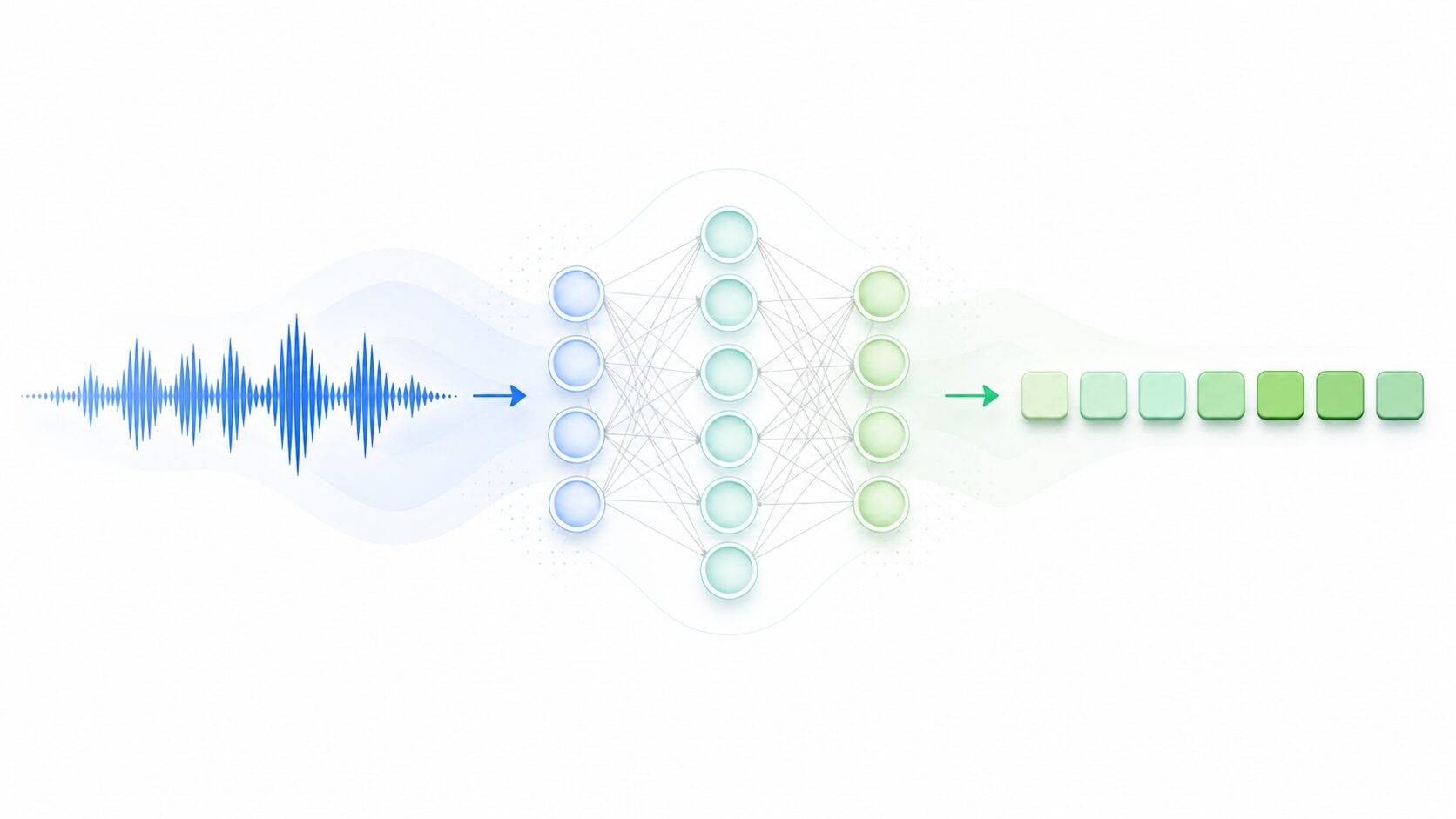
CTCは、音声認識や手書き文字認識のように、時間に沿って変化する入力データを、より短いラベル列へ変換したいときに使われます。音声認識でいえば、マイクから得られる波形や特徴量の列を入力し、最終的に「こんにちは」「hello」のような文字列を出力する処理です。
ここで難しいのは、入力と出力の長さが同じではない点です。音声は短い時間単位のフレームに分けて処理されるため、1秒の音声でも多数のフレームになります。一方、出力したい文字列は数文字から数十文字程度です。CTCは、このような長い入力系列と短い出力系列の対応関係を、細かい時刻ラベルなしで学習できるようにします。
従来は「この時間区間が『こ』、次の時間区間が『ん』」のように、音声と文字の対応位置をあらかじめそろえる作業が重要でした。しかし、実際の音声では発音の長さ、話す速さ、無音、雑音が毎回変わるため、この対応付けは簡単ではありません。CTCは、対応位置が分からない状態でも、あり得る並び方をまとめて考えることで学習を進めます。
なぜ音声認識では入力と出力の長さがずれるのか

音声は連続した波形です。機械学習モデルに入力するときは、波形を短い時間幅に区切り、各フレームから特徴量を取り出します。たとえば10ミリ秒ごとに特徴量を作ると、1秒の音声だけでも100個前後の入力になります。
一方で、「こんにちは」という出力は5文字です。つまり、100個近い入力フレームと5文字の出力を対応させる必要があります。さらに、人によって「こ」を少し長く発音したり、「ん」の前後に短い無音が入ったり、周囲の雑音で一部の音があいまいになったりします。
このため、音声認識では入力の時刻数と出力ラベル数が一致しないことが普通です。CTCが必要になるのは、このずれを前提にして学習できるからです。音が伸びて「こんんにちは」のように見える途中結果や、無音を含む「こ_んにちは」のような候補も、最終的な文字列に変換すると同じ正解として扱えます。
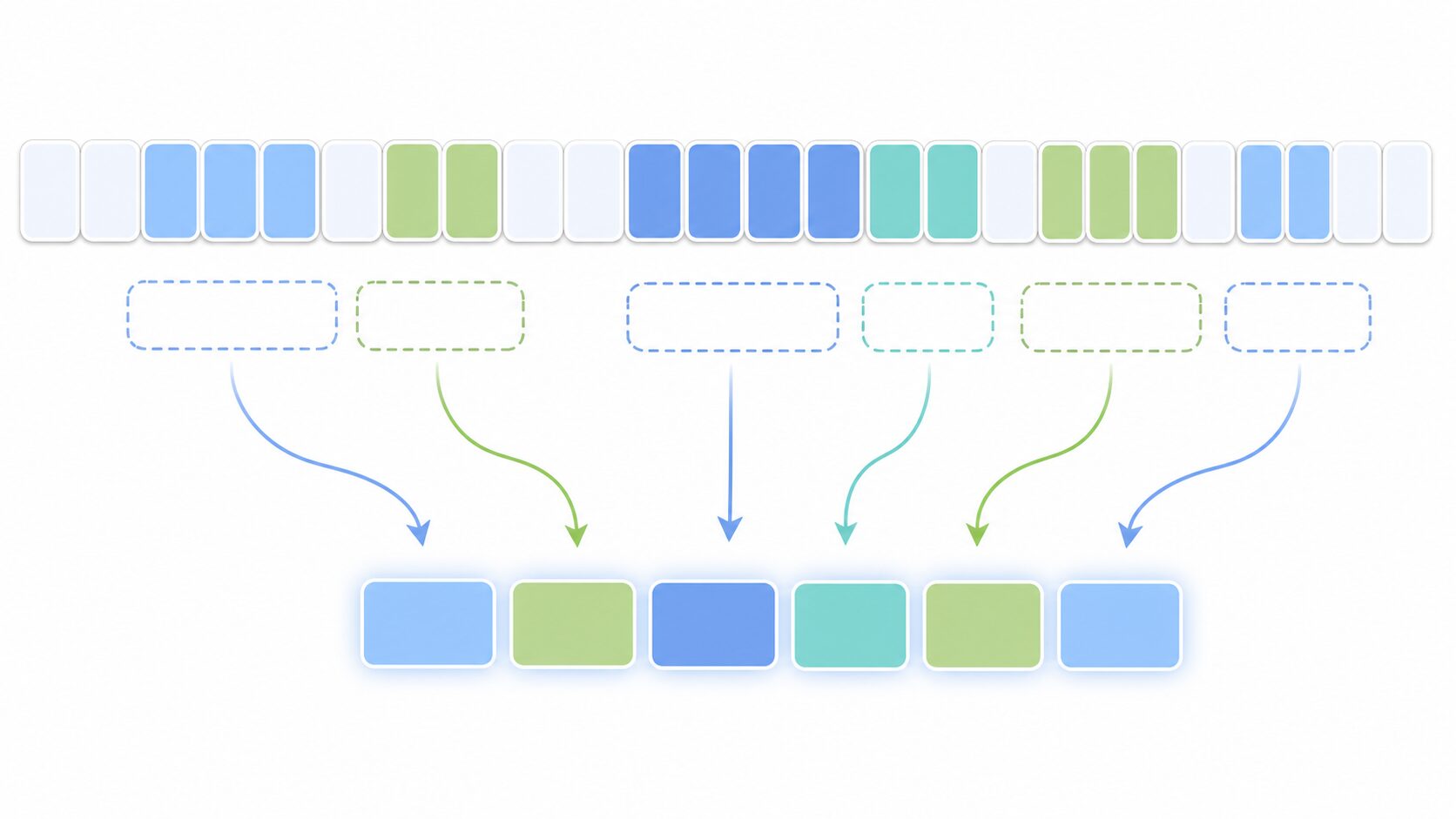
CTCの仕組み:フレーム、blank、同じ文字の統合
CTCでは、ニューラルネットワークが各フレームに対して「どの文字や音素が出そうか」を確率として出力します。この候補には通常の文字や音素だけでなく、blankと呼ばれる特別な記号が含まれます。blankは、スペース文字という意味ではなく、「この時刻では出力文字を確定しない」と考えるための記号です。
CTCの出力は、まず同じラベルの連続をまとめ、次にblankを取り除くことで最終的な文字列になります。たとえば、途中の候補が「h h _ e l l _ o」のようになっていても、連続する同じ記号やblankを整理すると「hello」に対応する候補として扱えます。
この考え方により、音が少し長く続いた場合でも、同じ文字が何度も出たような途中結果を一つの文字としてまとめられます。ただし、本当に同じ文字が連続する単語を扱うには注意が必要です。例えば英語の「letter」のように同じ文字が続く場合、blankを挟むことで「伸びた1文字」と「本当に2回出る文字」を区別しやすくします。
CTCの学習では、正解文字列に対応し得るすべての経路を考え、その確率の合計を大きくするようにモデルを調整します。概念的には、次のような確率を最大化します。
\(P(y|x)=\sum_{\pi \in B^{-1}(y)}P(\pi|x)\)ここで、xは入力音声、yは正解の文字列、πはblankや繰り返しを含む途中の経路、Bは途中経路を最終文字列へまとめる操作を表します。数式を完全に覚える必要はありませんが、正解にたどり着く複数の並び方をまとめて評価する点がCTCの中心です。
従来手法との違い
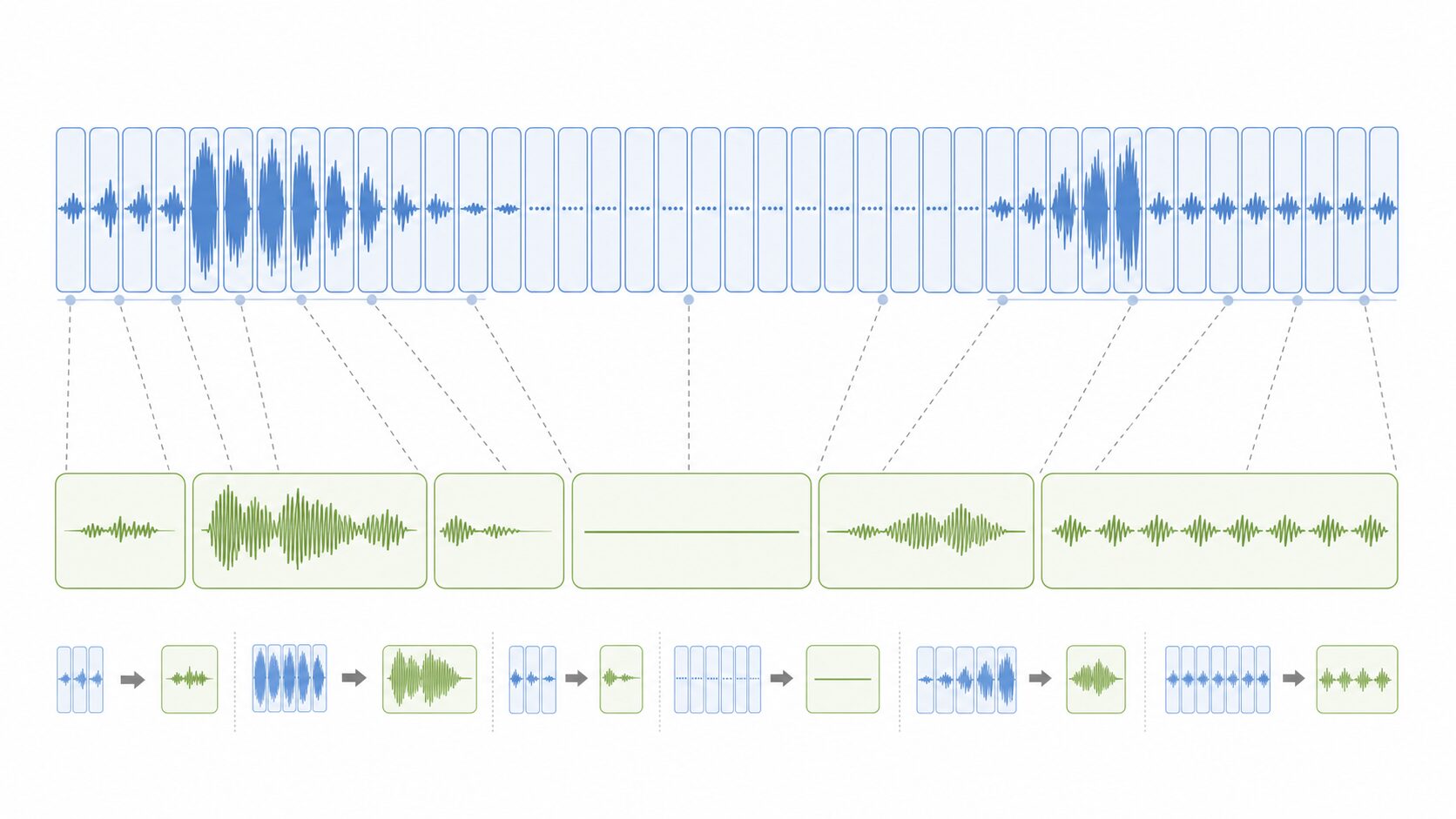
従来の音声認識では、音声を音素や短い単位に分割し、それぞれの区間とラベルを対応させる考え方が重要でした。たとえば「こんにちは」という音声に対して、どの区間が「こ」、どの区間が「ん」に対応するかを前処理で推定します。
しかし、この分割は発音の個人差やノイズに弱く、誤った区切りがそのまま認識結果に影響することがあります。手作業で正確な時刻ラベルを付ける場合も、コストが高く、データを大量に用意する妨げになります。
CTCでは、音声全体を入力し、最終的な文字列との対応をモデル側で学習します。そのため、音素ごとの厳密な時刻合わせを用意しなくても学習できる点が大きな違いです。
| 項目 | 従来手法 | CTC |
|---|---|---|
| 前処理 | 音素や単語単位への分割が必要になりやすい | 厳密な時刻ラベルなしで学習しやすい |
| 入力と出力 | 対応位置をそろえる工夫が必要 | 長さの不一致を前提に扱える |
| 誤差の影響 | 分割ミスが認識結果に波及しやすい | 複数の候補経路をまとめて評価できる |
| 向いている場面 | 区切りが明確なデータやルール設計がしやすい処理 | 音声、手書き文字など時系列の長さが変動する処理 |
音声認識でCTCを使う利点
CTCの第一の利点は、音声と文字の細かい対応位置を人間が指定しなくても学習しやすいことです。音声データと正しい文字起こしがあれば、モデルはどのフレームがどの文字に関係しそうかを確率的に学習できます。これにより、データ準備の負担を減らせます。
第二に、発音の長さや話す速度の違いに対応しやすい点があります。同じ「こんにちは」でも、ゆっくり話す人と速く話す人では音声フレームの数が変わります。CTCは入力の長さが変わっても、最終的な文字列へまとめる仕組みを持つため、このような変動を扱いやすくなります。
第三に、深層学習モデルと組み合わせやすい点です。音声特徴量を処理するニューラルネットワークの最後にCTC損失を置くことで、フレームごとの確率を学習できます。音声入力、音声検索、議事録作成、自動音声応答など、実用的な音声認識システムの基礎として使われてきました。
| 利点 | 内容 |
|---|---|
| 時刻ラベルの負担を減らせる | 音声のどの部分がどの文字かを細かく指定しなくても学習しやすい |
| 発音のばらつきに対応しやすい | 音の伸び、繰り返し、短い無音を候補経路として扱える |
| 深層学習と相性がよい | ニューラルネットワークの時系列出力を文字列へまとめる目的関数として使える |
CTCを学ぶときの注意点
CTCは便利な手法ですが、すべてを単独で解決するものではありません。CTCは音響的にあり得る文字列を推定する力を持ちますが、文として自然かどうか、専門用語として妥当かどうかは別の問題です。そのため、実際の音声認識では言語モデルや辞書、ビームサーチなどのデコーダと組み合わせることがあります。
また、blankの意味を「空白文字」と混同しないことも重要です。blankは出力しない時刻を表すための記号であり、文章中のスペースとは役割が違います。初心者がCTCを理解するときは、まず「フレームごとの候補を出す」「繰り返しをまとめる」「blankを消す」という流れで考えると整理しやすくなります。
さらに、CTCは入力と出力の順序が大きく入れ替わらない問題に向いています。音声は基本的に話した順に文字が現れるため相性がよい一方、入力の一部を大きく並べ替えて出力する必要があるタスクでは、別の系列変換モデルが適することもあります。
今後の展望と活用例
CTCは、音声入力や音声検索だけでなく、会議の自動文字起こし、コールセンターの応答支援、車載音声操作、字幕生成など、音声を文字に変換する多くの場面で重要な考え方を提供します。入力と出力の長さが一致しない系列データを扱えるため、手書き文字認識のような分野にも応用できます。
今後は、より少ないデータで学習する方法、ノイズ環境での認識精度向上、リアルタイム処理の高速化、言語モデルとの組み合わせが引き続き重要になります。特に実務では、CTCだけでなく、音声特徴量の作り方、モデル構造、デコーダ、後処理を合わせて設計することで認識品質が決まります。
その意味でCTCは、音声認識システム全体の中の一部でありながら、入力と出力のずれを扱う中心的な部品です。仕組みを理解しておくと、音声認識モデルの学習、評価、エラー分析を考えるときの見通しがよくなります。
まとめ
CTCは、音声認識で起こる「入力フレーム数と出力文字数が一致しない」という問題を扱うための手法です。音の伸び、繰り返し、無音区間を含む複数の候補経路を考え、最終的に同じ文字列へまとめられる経路をまとめて評価します。
従来手法と比べると、細かな音素分割や時刻ラベルの負担を減らしやすく、深層学習モデルと組み合わせて音声から文字列を直接学習しやすい点が特徴です。一方で、言語として自然な出力を得るには、言語モデルやデコーダとの組み合わせが必要になることもあります。
まずは、CTCを「音声の長いフレーム列を、blankと繰り返しの整理によって短い文字列へ変換する仕組み」と捉えると理解しやすくなります。音声認識の基礎を学ぶうえで、CTCは避けて通れない重要な概念です。
更新履歴
| 日付 | 内容 |
|---|---|
| 2025年2月1日 | 初回公開 |
| 2026年5月12日 | blankの役割と経路統合の考え方を補い、比較表を再整理 |