
大域最適解とは?局所最適解との違いと機械学習での考え方

AIの初心者
「大域最適解」ってどういう意味ですか?最適解と何が違うのか、少し難しく感じます。

AI専門家
大域最適解は、探している範囲全体で最も良い解のことだよ。谷がいくつもある地形なら、全体で一番深い谷底にあたる場所だね。
AIの初心者
近くの谷底に着いたとしても、もっと深い谷が別の場所にあるかもしれない、ということですか?
AI専門家
その通り。機械学習では学習率や初期値、探索方法を工夫して、近くの良い解だけで満足しないように調整していくんだ。
大域最適解とは。
大域最適解とは、ある問題で考えられる範囲全体の中で、最も良いと判断される解のことです。機械学習では、モデルの予測誤差や損失をできるだけ小さくするパラメータを探すときに、この考え方が使われます。
大域最適解とは何か

大域最適解は、探索範囲全体で見たときに最も良い解です。「大域」は全体の範囲、「最適解」は目的に対して最も望ましい答えを意味します。機械学習では、多くの場合、モデルの損失を最小にするパラメータの組み合わせを探すため、大域最適解は「全体で最も損失が小さい点」と考えると理解しやすくなります。
例えば、商品価格を決める問題を考えます。ある期間の売上だけを見れば、特定の価格が最も良く見えるかもしれません。しかし、季節、競合、広告、在庫、顧客層まで含めて全体を見直すと、別の価格のほうが利益を大きくできる可能性があります。このように、限られた範囲ではなく、問題全体で最も良い解を探す考え方が大域最適解です。
機械学習で扱うモデルは、重みやバイアスなど多数のパラメータを持ちます。その組み合わせごとに損失の値が変わるため、最適化は広い地形から一番低い場所を探す作業に似ています。ただし、実際のモデルではその地形を目で見ることはできません。計算を通じて、より良い方向を少しずつ探っていきます。
局所最適解との違い

大域最適解と合わせて理解したいのが、局所最適解です。局所最適解は、近い範囲だけで見ると最適に見える解を指します。地形でいえば、目の前の谷底に到達した状態です。その谷底の周辺ではこれ以上低い場所が見つからないため、一見すると十分に良い解に見えます。
しかし、地形全体を見渡すと、離れた場所にもっと深い谷底があるかもしれません。このとき、目の前の谷底は局所最適解であり、全体で最も深い谷底が大域最適解です。両者の違いは「どの範囲で最適と判断しているか」にあります。
| 種類 | 意味 | 注意点 |
|---|---|---|
| 局所最適解 | 近い範囲では最も良い解 | 全体ではより良い解が残っている可能性がある |
| 大域最適解 | 探索範囲全体で最も良い解 | 複雑な問題では見つけるのが難しい |
| 準最適解 | 厳密な最良ではないが実用上十分な解 | 計算時間やコストとのバランスで選ばれる |
初心者が混乱しやすい点は、「最適」と呼ばれていても、それが全体で最適とは限らないことです。機械学習の学習結果がある程度良く見えても、初期値や学習方法を変えると、さらに良い結果が得られる場合があります。
勾配降下法で最適解を探す仕組み

機械学習でよく使われる最適化手法に、勾配降下法があります。勾配降下法は、現在の位置から見て損失が小さくなる方向へパラメータを動かし、少しずつ良い解へ近づく方法です。山や谷の例でいえば、斜面の傾きを見ながら谷底へ下っていく動きに近いものです。
基本的な更新の考え方は、次のように表せます。
\(\theta_{t+1}=\theta_t-\eta \nabla L(\theta_t)\)ここで、θはモデルのパラメータ、Lは損失関数、ηは学習率です。勾配は損失が増える方向を示すため、勾配と反対方向へ動くことで損失を下げようとします。この式そのものを暗記する必要はありませんが、「今いる場所の傾きを見て、損失が小さくなる方向へ一歩進む」と理解しておくと、後の学習が楽になります。
ただし、勾配降下法は常に大域最適解へ到達するとは限りません。目的関数の形が単純で、谷がひとつだけなら比較的分かりやすいのですが、複雑なモデルでは谷がいくつも現れます。そのため、出発点や進み方によっては局所最適解に止まることがあります。
学習率が結果に与える影響

学習率は、勾配降下法で一度にどれだけ進むかを決める値です。学習率が小さすぎると学習は遅くなり、大きすぎると最適な場所を飛び越えて不安定になることがあります。坂道を下るときの歩幅を想像すると分かりやすいでしょう。
歩幅が小さすぎる場合、谷底へ近づくまでに非常に多くの更新が必要です。時間がかかるだけでなく、途中の浅い谷にとどまってしまうこともあります。逆に歩幅が大きすぎる場合、谷底を通り過ぎて反対側へ行ってしまい、損失が上下に振動することがあります。
| 学習率 | 起こりやすいこと | 実務上の見方 |
|---|---|---|
| 小さすぎる | 収束まで時間がかかる | 損失は下がるが進みが遅い |
| 大きすぎる | 谷底を飛び越えて不安定になる | 損失が増えたり振動したりする |
| 適切 | 安定して良い解へ近づく | 損失の推移を見ながら調整する |
学習率は「大きくすれば早く良くなる」という単純なものではありません。学習曲線を確認し、損失が安定して下がっているか、途中で発散していないかを見ながら調整します。実務では、学習率を途中で下げるスケジュールや、Adamのように更新幅を自動調整する手法もよく使われます。
初期値によって到達点が変わる理由
初期値とは、学習を始めるときのパラメータの出発点です。複雑な地形では、どこから下り始めるかによって、たどり着く谷底が変わることがあります。ある出発点からは浅い谷へ進み、別の出発点からはより深い谷へ進むかもしれません。
初期値は、局所最適解に陥るかどうかに影響する重要な要素です。同じモデル、同じデータ、同じ学習率でも、初期値が違うだけで最終的な性能が少し変わることがあります。そのため、複数の初期値で学習を試したり、初期化方法を工夫したりすることがあります。
深層学習では、パラメータ数が非常に多いため、厳密な意味で大域最適解を確認することは簡単ではありません。それでも、適切な初期化は学習の安定性に大きく関わります。最初から極端な値を置くと、勾配が大きくなりすぎたり小さくなりすぎたりして、学習が進みにくくなる場合があります。
大域最適解を見つけるのが難しい理由
大域最適解を見つけるのが難しい最大の理由は、探索範囲が広すぎることです。パラメータが少ない単純な問題なら、候補を比較しながら最良の値を探せる場合もあります。しかし、機械学習モデルではパラメータが何千、何万、あるいはそれ以上になることがあります。
パラメータの組み合わせが増えると、全ての候補を調べることは現実的ではありません。配送ルートの最適化でも、訪問先が増えるほど候補ルートは爆発的に増えます。機械学習でも同じように、全体を完全に調べる前に計算時間やメモリの制約にぶつかります。
さらに、目的関数の形が複雑だと、谷や平坦な場所が多数現れます。勾配がほとんど変わらない平坦な領域では進み方が分かりにくく、狭く曲がった谷では更新が不安定になることもあります。つまり、大域最適解を探す問題は、単に「一番良い場所を選ぶ」だけではなく、限られた情報と計算資源でどこまで良い場所に近づけるかという問題でもあります。
そのため実務では、必ずしも厳密な大域最適解だけを目指すわけではありません。十分に性能が高く、再現性があり、運用上の制約を満たす解であれば、準最適解として採用されることもあります。完璧な解を待ち続けるより、目的に対して十分に役立つ解を選ぶ判断が大切です。
より良い解に近づくための代表的な工夫
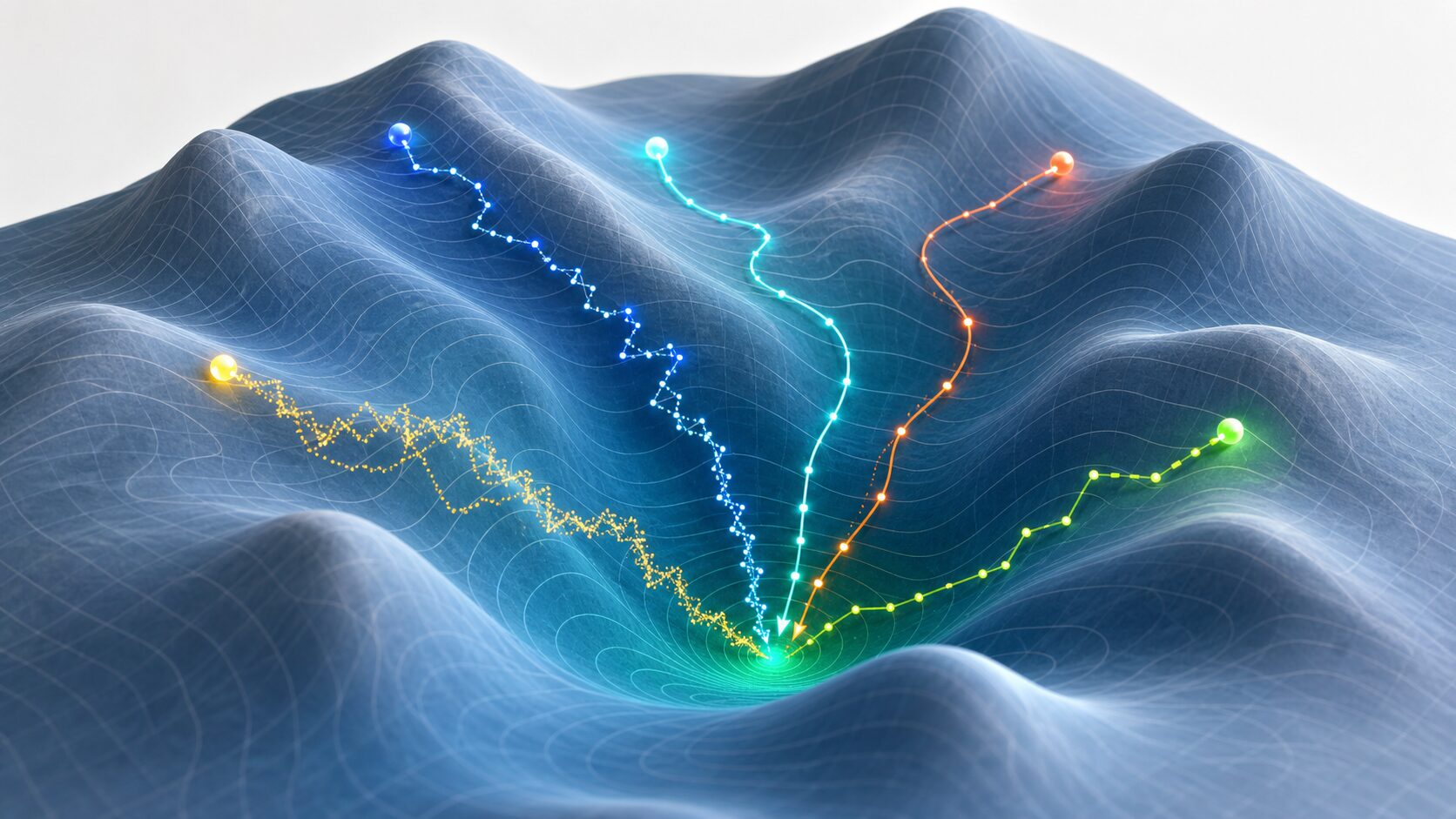
大域最適解へ近づくためには、探索方法を工夫します。勾配降下法だけでなく、確率的な要素を入れたり、過去の更新方向を活用したり、複数の候補を同時に試したりする方法があります。
確率的勾配降下法は、データ全体ではなく一部のデータを使って更新する方法です。更新に揺らぎが生まれるため、局所最適解から抜け出すきっかけになる場合があります。モーメンタム法は、過去の移動方向を考慮して更新する方法で、谷の中での無駄な振動を抑えながら進みやすくします。
遺伝的アルゴリズムや焼きなまし法のようなメタヒューリスティクスも、最適化問題で使われます。遺伝的アルゴリズムは複数の候補を進化させるように探索し、焼きなまし法は最初に大きな変化を許し、徐々に探索を細かくしていきます。これらは万能ではありませんが、勾配が使いにくい問題や、探索空間が複雑な問題で候補になります。
大切なのは、手法名を暗記することではありません。どの方法も、局所的に良い解で止まらず、より広い範囲から良い解を探すための工夫です。問題の性質、計算コスト、必要な精度に合わせて、現実的な探索方法を選ぶことが重要です。
まとめ
大域最適解とは、探索範囲全体で最も良い解です。機械学習では、損失を最小にするパラメータを探す文脈でよく使われます。一方、局所最適解は、近い範囲では最適に見えるものの、全体ではさらに良い解が残っている可能性がある状態です。
勾配降下法は、損失が小さくなる方向へ少しずつ進む基本的な最適化手法です。ただし、学習率や初期値の影響を受けるため、必ず大域最適解に到達するとは限りません。複雑なモデルでは、厳密な最良解を探すよりも、十分に良い解へ安定して近づくための工夫が重要になります。
大域最適解を理解すると、機械学習の学習がなぜ調整を必要とするのか、また「良いモデル」を作るために何を見ればよいのかが見えやすくなります。局所最適解、学習率、初期値、最適化手法をセットで押さえておくと、機械学習の基礎をより立体的に理解できます。
更新履歴
| 日付 | 内容 |
|---|---|
| 2025年2月2日 | 初回公開 |
| 2026年5月6日 | 局所解との比較、式の読み方、探索手法の補足を追加 |