次元の呪い:高次元データの罠

AIの初心者
「次元の呪い」って、一体どういうことですか?難しそうでよくわからないです…

AI専門家
そうですね。「次元の呪い」は少し難しい概念ですね。簡単に言うと、AIのモデルを作る際に、入力データの特徴量が増えれば増えるほど、必要なデータの量が爆発的に増えてしまう現象のことです。例えば、顔認識AIで考えてみましょう。目の大きさ、鼻の高さ、口の幅など、特徴量を増やせば増やすほど、AIは顔を正確に認識できるようになります。しかし、その分、AIに学習させるための顔写真の枚数が膨大に必要になるのです。
AIの初心者
なるほど。特徴量が増えると、必要なデータも増えるんですね。でも、どうして爆発的に増えてしまうんですか?
AI専門家
良い質問ですね。特徴量が増えると、データが存在する空間の次元数が増えます。そして、高次元空間では、データ同士がまばらに存在する傾向があります。つまり、データがスカスカな状態になるため、AIが正確に学習するには、より多くのデータが必要になるのです。これを「次元の呪い」と言います。
次元の呪いとは。
人工知能の分野で、「次元の呪い」と呼ばれる問題があります。これは、学習に使うデータの特徴が増えるほど、正確な予測モデルを作るのに必要なデータ量が爆発的に増えてしまう現象のことです。例えば、顔認識で考えると、目の大きさ、鼻の高さ、口の幅など、顔の特徴をたくさん使えば使うほど、正確に顔を認識できるようになります。しかし、特徴を増やすほど、それぞれの組み合わせを網羅するために、膨大な数の顔写真が必要になってきます。この、特徴の数が多くなることによって起こるデータ量の急激な増加を「次元の呪い」と呼びます。
次元の呪いとは

機械学習では、様々な情報をもとに予測を行います。これらの情報のひとつひとつを次元と呼びます。例えば、家の値段を予測する際には、家の広さ、築年数、駅からの距離といった情報が次元となります。これらの情報が多いほど、より正確な予測ができると考えるのは自然な発想です。しかし、現実はそう簡単ではありません。次元の数が増えるほど、正確な予測に必要なデータ量が膨大に増えてしまうのです。この現象こそが、次元の呪いと呼ばれています。
例を挙げると、広さのみを考慮する場合、100平方メートルごとに区切れば、ある程度の精度で価格帯を予測できるかもしれません。しかし、築年数も考慮するとなると、10年ごとに区切り、広さと築年数の組み合わせごとにデータを用意する必要があります。さらに駅からの距離も加えると、1キロメートルごとに区切り、三つの情報の組み合わせごとにデータが必要になります。このように次元が増えるごとに、必要なデータ量は掛け算式に増えていくのです。
高次元空間では、データはまばらに存在するとイメージしてみてください。限られた数のデータでは、広大な空間を埋め尽くすことはできません。そのため、データとデータの間の空白部分が大きくなり、正確な予測をするのが難しくなります。地図上に家が数軒しかない状態で、他の場所の価格を予測するのは困難です。より多くの家、つまりデータがあれば、精度の高い予測が可能になるでしょう。
次元の呪いは、機械学習において重要な課題です。高次元データを用いる際には、この呪いを意識し、適切な対処法を検討する必要があります。例えば、本当に必要な次元を取捨選択する、あるいは次元を減らす工夫をするなど、様々な方法があります。限られたデータから最大の効果を得るためには、次元の呪いを理解し、適切な対策を講じることが不可欠なのです。
| 次元の呪いとは | 説明 | 問題点 | 例 |
|---|---|---|---|
| 次元数の増加に伴うデータ量の爆発的増加 | 予測に用いる情報(次元)が増えるほど、正確な予測に必要なデータ量が膨大になる現象 | データ量が不足すると、正確な予測が困難になる | 家の価格予測:広さのみ→100平方メートルごと 広さ+築年数→10年ごと×100平方メートルごと 広さ+築年数+駅からの距離→1kmごと×10年ごと×100平方メートルごと |
| 高次元空間におけるデータのまばら性 | 高次元空間では、データがまばらに存在するため、データ間の空白部分が大きくなる | データがまばらだと、正確な予測が難しくなる | 地図上に家が数軒しかない状態で、他の場所の価格を予測するのは困難 |
| 機械学習における重要課題 | 次元の呪いは、機械学習において重要な課題であり、適切な対処が必要 | 対処しないと、予測精度が低下する | 本当に必要な次元を取捨選択する、次元を減らす工夫をする |
高次元空間の特殊性

私たちが普段生活しているのは、縦、横、高さの三つの尺度を持つ三次元の空間です。しかし、扱う情報の種類が増えると、もっと多くの尺度が必要になることがあります。これを高次元空間と呼びます。高次元空間には、私たちの直感とは異なる不思議な性質があります。高次元空間のもっとも特徴的な性質の一つは、データがほとんど空間の縁に集まってしまうことです。まるで風船の表面にインクを塗ったように、データは中心から離れた場所に散らばるのです。これは、次元が増えるほど空間の体積が中心から急速に大きくなるために起こります。
もう一つの不思議な性質は、データ同士の距離がほとんど同じになってしまうことです。三次元空間では、データ同士の位置関係は様々で、近いものもあれば遠いものもあります。しかし、高次元空間では、データが空間の縁に集まるため、中心からの距離がほぼ等しくなってしまいます。これは、ものさしで測った距離がどれも同じくらいになってしまうようなものです。このような状況では、データの類似性や違いを捉えることが難しくなります。
これらの高次元空間の特殊な性質は、「次元の呪い」と呼ばれる問題を引き起こします。機械学習は、大量のデータからパターンを学び、未知のデータについて予測を行います。しかし、高次元空間では、データがまばらに存在し、距離の概念があいまいになるため、機械学習はうまく機能しません。まるで、霧の深い場所で宝探しをするようなもので、手がかりを見つけにくく、迷子になってしまうのです。具体的には、学習データに過剰に適合してしまい、新しいデータに対してはうまく予測できない「過学習」と呼ばれる状態に陥りやすくなります。また、せっかく学習したパターンが新しいデータにも通用しない「汎化性能の低下」といった問題も発生します。高次元データを扱う際には、これらの問題に注意深く対処する必要があります。
| 高次元空間の性質 | 影響 |
|---|---|
| データが空間の縁に集まる | データ同士の距離がほぼ同じになる |
| データ同士の距離がほぼ同じになる | データの類似性や違いを捉えにくくなる |
| 次元の呪い | 機械学習がうまく機能しない(過学習、汎化性能の低下) |
次元の呪いへの対策

たくさんの情報を持つデータは、一見すると良いもののように思えます。しかし、情報が多すぎると、かえって問題が生じることがあります。これを「次元の呪い」と呼びます。データの持つ情報の量、つまり次元数が大きくなると、データ同士の距離が遠くなり、データの密度が薄くなってしまうのです。これは、広大な宇宙に星がまばらに存在している様子に似ています。このような状態では、データの特徴を捉えにくくなり、正確な予測を行うことが難しくなります。次元の呪いに対抗するためには、いくつかの方法があります。
まず、データの次元数を減らす方法があります。これは「次元削減」と呼ばれ、不要な情報を削ぎ落とし、重要な情報だけを残す手法です。例えば、「主成分分析」という手法は、データの中に隠れている重要な情報を見つけて、それを新たな軸としてデータを表すことで次元を減らします。元のデータが持つ情報のほとんどを保持したまま、少ない次元で表現できるため、データの特徴を捉えやすくすることができます。
次に、本当に必要な情報だけを選び出す方法があります。これは「特徴量選択」と呼ばれ、予測に役立つ重要な情報だけを選び、それ以外の情報を捨てる手法です。例えば、気温や湿度、風速などの情報から明日の天気を予測する場合、過去の天気データの中から特に関係の深い情報だけを選び出して使うことで、予測の精度を高めることができます。これらの手法を用いることで、次元の呪いを回避し、限られたデータからでも有効な知識を引き出すことが可能になります。
さらに、扱うデータの性質に合った適切な予測方法を選ぶことも大切です。高次元データに適した方法を選ぶことで、次元の呪いの影響を減らすことができます。例えば、「サポートベクトルマシン」などの手法は、高次元データに対しても比較的うまく働くことが知られています。
このように、次元の呪いへの対策は、データ分析において非常に重要な要素です。適切な方法を選ぶことで、高次元データからでも正確な予測を行い、隠れた知識を発見することが可能になります。
| 問題点 | 次元の呪い |
|---|---|
| 説明 | データの次元数が増加すると、データ間の距離が遠くなり、データ密度が低下し、分析が困難になる現象。 |
| 対策 |
|
| 効果 | 次元の呪いを回避し、限られたデータから有効な知識を引き出すことが可能になる。高次元データからでも正確な予測を行い、隠れた知識を発見することが可能になる。 |
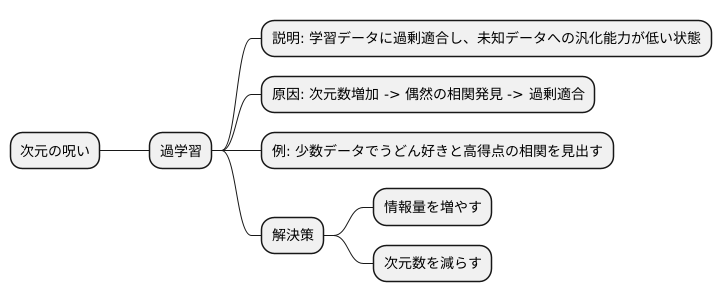
過学習との関連性

多くのものを取り扱おうとすると、かえってうまくいかないことがあります。これは機械学習の世界でも同じで、扱う情報の数が多すぎると思わぬ落とし穴に陥ることがあります。これを次元の呪いと呼びます。この次元の呪いは、過学習と呼ばれる問題を引き起こす大きな原因の一つです。
過学習とは、学習に使った情報にぴったり合いすぎてしまい、新しい情報に対してはうまく対応できなくなる現象です。まるで、特定の問題の解き方だけを暗記してしまい、少し問題が変わると解けなくなってしまう生徒のようです。高次元、つまり扱う情報の種類が多いほど、限られた情報から複雑な規則を見つけ出そうとすると、この過学習が起こりやすくなります。これは、情報の種類が多いほど、情報同士の関連性を見つけることが難しくなり、たまたま見つけた関連性が実はただの偶然だったということが起こりやすいためです。
例えば、10人の生徒のテストの点数と好きな食べ物から、点数を予測するモデルを作るとします。限られた10人のデータでは、たまたまうどんが好きな生徒が高得点だったという関係が見つかるかもしれません。しかし、これは本当にうどんが好きだから点数が高いという関係ではなく、単なる偶然かもしれません。もしこのモデルがうどん好きが高得点だと学習してしまうと、うどんが好きなだけで高得点と予測してしまい、実際にはそうではない生徒の点数を正しく予測できなくなります。これが過学習です。
情報の種類が多いほど、このような偶然の関連性を見つけてしまう確率が高くなります。つまり、次元の呪いによって過学習のリスクが高まるのです。この過学習を避けるためには、扱う情報の種類を適切に絞ったり、より多くの学習情報を使ったりすることが重要です。そうすることで、偶然の関連性に惑わされず、真の関係性を捉えた、新しい情報にもうまく対応できるモデルを作ることができます。
データ量の重要性

学習に使う情報の量、つまりデータ量は、情報の分析において極めて重要です。特に、たくさんの特徴量(情報の側面)を扱う場合、データ量が不足すると「次元の呪い」と呼ばれる問題が発生します。これは、特徴量の数が多くなるにつれて、データが存在する空間が加速度的に広がり、同じ量のデータでは空間を埋め尽くすことができなくなる現象です。結果として、学習に使う情報同士の距離が離れすぎてしまい、正確な関係性や規則性を掴むのが難しくなります。
この問題を解決するためには、広がった空間を十分に埋め尽くせるだけの豊富なデータ量が必要です。データ量が多ければ多いほど、情報同士の距離が縮まり、隠れた関係性や規則性を見つけやすくなります。例えば、果物の特徴を「色」と「大きさ」だけで判断しようとすると、リンゴとイチゴを区別するのは難しいかもしれません。しかし、「甘さ」や「香り」、「形」といった特徴量を増やし、さらに多くの種類の果物のデータを加えることで、それぞれの果物の特徴をより正確に把握し、分類できるようになります。
しかし、現実の世界では、必要な量の情報を集めるのは簡単ではありません。費用や時間、技術的な制約など、様々な要因がデータ収集を阻みます。そこで、限られた情報からでも効果的に学習を進めるための工夫が求められます。例えば、本当に必要な特徴量だけを選び出す「特徴量選択」や、特徴量の数を減らす「次元削減」といった手法は、データ量不足を補う有効な手段です。また、「データ拡張」という手法を用いて、既存のデータに少し手を加えることでデータ量を擬似的に増やす方法も存在します。
さらに、データの質にも注意を払う必要があります。誤った情報や偏りのある情報は、学習を妨げ、次元の呪いの影響を悪化させる可能性があります。高品質な情報を集め、適切な方法で情報を整理・加工することで、より正確で信頼性の高い結果を得ることができます。つまり、データの量だけでなく、質にも気を配ることが重要なのです。
| 問題点 | 原因 | 解決策 |
|---|---|---|
| 次元の呪い:特徴量が多いとデータ空間が広がり、データ量が不足し、正確な関係性や規則性を掴めなくなる。 | データ量不足。特徴量の増加に対してデータ量が比例していない。 |
|
| データ収集の難しさ | 費用、時間、技術的な制約 | 上記「次元の呪い」の解決策に加え、データの質にも注意を払う |
| データの質の悪さ | 誤った情報や偏りのある情報 | 高品質な情報を集め、適切な方法で整理・加工する |
まとめ

多くの情報を取り扱う機械学習では、「次元の呪い」という問題に直面することがあります。これは、扱う情報の種類が増えるほど、必要な情報の量は驚くほど多くなり、学習が難しくなる現象です。情報の種類が増えるということは、データの次元が増えることを意味します。例えば、リンゴの値段を予測するのに、重さだけを考えると一次元です。これに色や産地を加えると、二次元、三次元と次元が増えていきます。次元が増えると、より多くの情報で物事を捉えられるため、一見良いことに思えます。
しかし、高次元データは、思わぬ落とし穴を潜ませています。必要なデータ量は、次元の数に応じて、爆発的に増えます。二次元であれば平面を覆うのに必要なデータ量はそれほど多くはありませんが、三次元、四次元、と次元が増えるごとに、空間を埋めるのに必要なデータ量は膨大になっていきます。しかも、高次元空間には、私たちが普段扱う三次元空間とは異なる特殊な性質があります。例えば、高次元空間では、データは空間の端に偏って存在するようになります。このような性質も、学習を難しくする要因となります。
次元の呪いは、学習における「過学習」という問題にも深く関わっています。過学習とは、限られた学習データに過剰に適応しすぎてしまい、未知のデータに対してうまく予測できない状態のことです。高次元空間では、データがまばらに存在するため、限られたデータに合わせ込みやすくなり、過学習が起こりやすくなります。
では、次元の呪いに対抗するにはどうすれば良いのでしょうか?有効な手段の一つは、次元を減らすことです。関連性の高い情報をまとめて新しい情報を作ったり、重要でない情報を削除することで、次元を減らし、必要なデータ量を減らすことができます。また、適切な学習方法を選ぶことも大切です。高次元データに適した学習方法を用いることで、過学習を防ぎ、精度の高い予測モデルを作ることができます。さらに、データ量を増やすことも効果的です。データ量を増やすことで、まばらな高次元空間をより密に埋め、より正確な学習を行うことができます。次元の呪いを理解し、適切な対策を講じることで、高精度な予測モデルを構築し、機械学習の力を最大限に引き出すことが可能になります。
| 問題点 | 説明 | 対策 |
|---|---|---|
| 次元の呪い | 情報の種類(次元)が増えるほど、必要なデータ量が爆発的に増加し、学習が難しくなる現象。高次元空間の特殊な性質も学習を困難にする。 | 次元削減、適切な学習方法の選択、データ量の増加 |
| 過学習 | 限られた学習データに過剰に適応しすぎて、未知のデータに対して予測できない状態。高次元空間ではデータがまばらなため、過学習が起こりやすい。 | 次元削減、適切な学習方法の選択、データ量の増加 |