Q学習:試行錯誤で学ぶAI

AIの初心者
先生、「Q学習」って難しそうだけど、簡単に言うとどんなものですか?

AI専門家
そうだね、簡単に言うと、コンピュータが試行錯誤しながら、どの行動をとるのが一番良いかを学習する方法の一つだよ。 ゲームで例えると、どのボタンを押したら高い得点になるかを、何度もプレイしながら覚えていくようなイメージだね。
AIの初心者
なるほど。ゲームのプレイに似ているんですね!でも、どうやって一番良い行動を見つけるんですか?
AI専門家
いい質問だね。Q学習では「Qテーブル」というものを使って、それぞれの場面でどの行動をするとどれくらい良いかを記録していくんだ。そして、行動の結果に応じて、その記録を更新していくことで、だんだん一番良い行動がわかるようになっていくんだよ。
Q学習とは。
「人工知能」に関する言葉である「ク学習」について説明します。ク学習は、試行錯誤を通じて学習する手法の一つです。ク学習では、それぞれの状況における行動の価値を記録した表(ク表)を持っています。行動の結果として得られた報酬や、将来の報酬をどのくらい重視するかを表す割引率などを用いて、予測と実際とのずれ(TD誤差)をできるだけ小さくするように学習し、ク表の値を更新していきます。
はじめに

機械に学習させる方法は実に様々ですが、その中で試行錯誤を通して学習する強化学習という方法が近年注目を集めています。この学習方法は、まるで迷路の中でゴールを目指すネズミのように、機械自身が様々な行動を試しながら、より良い結果に繋がる行動を自ら学習していくというものです。
強化学習の中でも、Q学習という手法は特に代表的なものの一つです。Q学習では、「エージェント」と呼ばれる学習する主体が、周りの環境と作用し合いながら、どのような行動をとるのが最も良いのかを学習していきます。例えば、迷路の中のネズミをエージェントと見立てると、迷路全体が環境となります。ネズミは、様々な通路を試し、行き止まりにぶつかったり、チーズを見つけたりしながら、どの道を選べばチーズにたどり着けるのかを学習していきます。
Q学習の核心は、「Q値」と呼ばれる数値にあります。このQ値は、特定の状態において、特定の行動をとった場合に、将来どれだけの報酬が得られるかを予測した値です。ネズミの例で言えば、ある分岐点で右に進むのと左に進むのとでは、どちらがチーズに近いのか、という予測値をそれぞれの行動に対して持っていることになります。ネズミは、過去の経験からこのQ値を更新し続け、より精度の高い予測を立てられるように学習していきます。
Q学習の利点は、環境の全体像が分からなくても学習を進められるという点にあります。ネズミは迷路全体の形を知らなくても、それぞれの分岐点で最適な行動を選ぶことで、最終的にチーズにたどり着くことができます。これは、複雑な状況でも、試行錯誤を通して最適な行動を学習できるというQ学習の強みを表しています。このように、Q学習は様々な場面で応用が期待される、強力な学習手法と言えるでしょう。
| 強化学習の種類 | 説明 | 用語 | 利点 |
|---|---|---|---|
| Q学習 | 試行錯誤を通して学習する。例:迷路のネズミ | エージェント:学習主体 環境:エージェントが行動する場所 Q値:特定の状態で特定の行動をとった場合の将来の報酬予測値 |
環境の全体像が分からなくても学習可能 |
Q学習の仕組み

「学習する機械」を作るための方法の一つに、Q学習というものがあります。この学習方法は、ゲームをするように、機械に試行錯誤を通して目的を達成させる方法です。
Q学習の肝となるのが、Q表と呼ばれる表です。この表は、機械が置かれた状況と、その状況で取れる行動に対して、それぞれの行動の良さを数値で示したものです。この数値をQ値と呼びます。Q値が高いほど、その行動が良い行動であると判断されます。
例えば、ロボットが迷路を進む場面を考えてみましょう。ロボットの位置が「状況」であり、「前へ進む」「右へ曲がる」「左へ曲がる」といった行動が考えられます。Q表には、ロボットがそれぞれの位置で、それぞれの行動を取った時のQ値が記録されます。
Q学習では、ロボットが実際に行動し、その結果として報酬を得るたびに、Q表の値を更新します。例えば、ロボットが「前へ進む」行動を選び、ゴールに近づいた場合は、報酬としてプラスの値が与えられます。逆に、壁にぶつかった場合は、マイナスの値が与えられます。
ロボットは、得られた報酬と、次の状況で取れる行動の中で最も高いQ値を使って、現在の状況と行動に対するQ値を更新します。具体的には、現在のQ値に、得られた報酬と次の状況での最大のQ値を考慮した値を加えます。この計算を繰り返すことで、ロボットはより良い行動を選択できるようになり、最終的には迷路のゴールにたどり着けるようになります。
このように、Q学習は、機械に試行錯誤をさせ、その結果に応じてQ表を更新することで、最適な行動を学習させる方法です。まるで人間が経験を通して学習していく過程に似ています。Q学習は、ゲームだけでなく、ロボット制御や自動運転など、様々な分野で応用されています。
| 状況 | 行動 | Q値 |
|---|---|---|
| ロボットが迷路のある地点にいる | 前へ進む | 数値 (例: 10) |
| ロボットが迷路のある地点にいる | 右へ曲がる | 数値 (例: -5) |
| ロボットが迷路のある地点にいる | 左へ曲がる | 数値 (例: 2) |
| … | … | … |
Q値は、ロボットがその状況でその行動を取った時の良さを示す数値です。高いほど良い行動とされます。報酬(ゴールに近づく、壁にぶつかるなど)に応じてQ値が更新され、ロボットは学習していきます。
Qテーブルの役割

知能機械の学習において、過去の経験を活かすための重要な仕組みの一つに「行動価値表」というものがあります。これは、まるで知能機械が持つ知識の宝箱のようなものです。この宝箱の中には、様々な状況と行動の組み合わせに対して、それぞれどの程度の価値があるのかという情報が蓄えられています。この価値のことを「行動価値」と呼び、行動価値が高いほど、その状況でその行動をとることが良い結果に繋がると考えられます。
知能機械は、様々な状況に置かれ、様々な行動を試みます。それぞれの行動の後には、結果として報酬が得られます。例えば、迷路を進む知能機械にとって、ゴールに辿り着けば高い報酬が、壁にぶつかってしまえば低い報酬が与えられます。知能機械は、この報酬をもとに行動価値を更新していきます。良い結果に繋がった行動の価値は上がり、悪い結果に繋がった行動の価値は下がります。
この行動価値を記録しているのが、まさに「行動価値表」です。この表は、状況と行動の組み合わせごとに、対応する行動価値を数値で示しています。知能機械は、新しい状況に置かれたとき、この表を参照して、どの行動をとるべきかを判断します。行動価値が最も高い行動を選ぶことで、過去の経験を活かし、最適な行動をとることが期待されます。
知能機械は、行動価値表を常に更新し続けています。新しい経験を積むたびに、行動価値の見直しが行われます。これにより、知能機械は環境の変化に適応し、より賢い行動をとることができるようになります。行動価値表は、知能機械が学習し、成長していく上で欠かせない存在と言えるでしょう。
| 項目 | 説明 |
|---|---|
| 行動価値表 | 知能機械が持つ、状況と行動の組み合わせに対する価値を記録した表 |
| 行動価値 | 特定の状況で特定の行動をとることの価値。高いほど良い結果に繋がると考えられる。 |
| 報酬 | 行動の結果として得られる値。ゴール到達など良い結果には高い報酬、壁に衝突など悪い結果には低い報酬が与えられる。 |
| 行動価値の更新 | 得られた報酬に基づいて行動価値表の内容を更新するプロセス。良い結果の行動は価値が上がり、悪い結果の行動は価値が下がる。 |
| 行動決定 | 新しい状況で、行動価値表を参照し、最も価値の高い行動を選択する。 |
| 学習と成長 | 新しい経験を積むたびに、行動価値表を更新することで、環境の変化に適応し、より賢い行動をとれるようになる。 |
学習の進め方

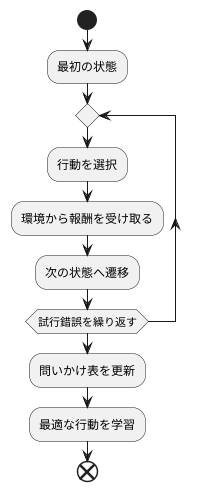
物事を学ぶ方法の一つに、問いかけ学習というものがあります。これは、繰り返し試行錯誤することで学ぶ方法です。例えるなら、迷路を解く場面を想像してみてください。迷路に入った人は、最初の場所からスタートし、分かれ道に差し掛かるたびに進む道を選びます。正しい道を選べば出口に近づき、間違えれば遠回りしたり、同じ場所に戻ったりします。問いかけ学習でも同じように、学習する主体は、まず最初の状態から始まります。そして、どのような行動をとるかを選び、その結果として環境から良いこと、つまり報酬を受け取ります。そして、次の状態へと移ります。迷路の例でいうと、出口に近づくことが報酬に当たります。
この一連の流れ、つまり行動を選び、報酬を受け取り、次の状態に移るというサイクルを何度も繰り返すことで、学習する主体は、どの状態においてどの行動をとるべきかを記録した表を更新していきます。この表は、問いかけ表と呼ばれ、いわば迷路の地図のようなものです。学習の初期段階では、学習する主体はまだ迷路の構造を理解していないため、行動はランダムに選ばれがちで、報酬も少ないでしょう。これは、迷路に入ったばかりの人が、出口までの道筋が分からず、手探りで進む様子に似ています。しかし、学習が進むにつれて、問いかけ表の内容が充実してきます。つまり、迷路の地図が完成に近づいていくということです。すると、学習する主体は問いかけ表に基づいてより良い行動を選べるようになり、受け取る報酬も増えていきます。これは、迷路の構造を理解した人が、最短ルートで出口を目指せるようになる様子と似ています。このように、問いかけ学習とは、試行錯誤を繰り返しながら、徐々に最適な行動を学んでいく学習方法です。
活用事例

「キュー学習」と呼ばれる技術は、様々な分野で役立っています。この技術は、試行錯誤を通じて最適な行動を学ぶことができるため、様々な場面で応用されています。
例えば、ゲームの世界では、キャラクターの知能を向上させるために活用されています。従来のゲームでは、あらかじめ決められた行動しかできませんでしたが、キュー学習を使うことで、キャラクターが自ら学習し、状況に応じて最適な行動を選択できるようになります。敵の攻撃を避けたり、アイテムを効率的に集めたりするなど、より高度な行動が可能になるため、ゲームの面白さが格段に向上します。
また、ロボットの制御にもキュー学習は応用されています。ロボットは、これまで人間がプログラムした通りにしか動けませんでしたが、キュー学習を導入することで、環境の変化に合わせて自ら行動を学習できるようになります。例えば、障害物を避けたり、目的物まで最短ルートで移動したりするなど、複雑なタスクをこなせるようになります。これにより、工場での自動化作業や災害現場での救助活動など、様々な分野での活躍が期待されています。
さらに、自動運転技術の開発においても、キュー学習は重要な役割を果たしています。道路状況や交通状況を学習することで、安全で効率的な運転を可能にします。信号や標識を認識するだけでなく、他の車両の動きや歩行者の行動を予測しながら、最適なルートを選択し、スムーズな運転を実現します。将来自動運転車が普及すれば、交通事故の減少や渋滞の緩和など、私たちの生活に大きな変化をもたらすでしょう。
このように、キュー学習は、様々な分野で応用され、私たちの生活をより豊かに便利にする技術として注目されています。今後ますます発展していくことで、さらに多くの分野で活用され、社会に大きな貢献をすることが期待されます。
| 分野 | キュー学習の活用例 | 効果 |
|---|---|---|
| ゲーム | キャラクターの知能向上、状況に応じた最適な行動選択 | ゲームの面白さ向上、高度な行動が可能に |
| ロボット制御 | 環境の変化に合わせた行動学習、障害物回避、目的物への最短ルート移動 | 工場の自動化、災害現場での救助活動など |
| 自動運転 | 道路状況や交通状況の学習、安全で効率的な運転 | 交通事故の減少、渋滞の緩和 |
まとめ

試行と失敗を繰り返しながら学ぶ学習方法、それが強化学習です。この強化学習の中でも、Q学習は特に注目すべき手法と言えるでしょう。Q学習は、まるで宝探しをするように、どのような行動をとれば最も良い結果を得られるかを学習していきます。その宝探しの地図となるのが、Qテーブルと呼ばれるものです。この表には、様々な状況と行動の組み合わせに対して、それぞれどの程度の価値があるのかが記録されています。
Q学習では、まず行動を起こし、その結果として報酬または罰が与えられます。そして、その結果を踏まえてQテーブルの値を更新していきます。良い結果が得られた行動は価値が高まり、悪い結果に繋がった行動は価値が下がります。この更新を繰り返すことで、Qテーブルは徐々に最適な行動を示す地図へと進化していくのです。
ゲームやロボット制御など、Q学習は様々な分野で応用されています。例えば、ゲームでは、キャラクターをどのように動かせば高い得点を得られるかを学習するために利用できます。ロボット制御では、ロボットがどのように動けば目的を達成できるかを学習するために活用できます。このように、Q学習は人工知能技術の発展に大きく貢献している重要な学習方法と言えるでしょう。
Q学習は、常に変化する状況の中で最適な行動を学習できるという点で非常に優れています。また、比較的単純な仕組みであるため、理解しやすく、実装も容易です。今後、さらに研究が進めば、より複雑な問題にも対応できるようになり、人工知能技術の進化をさらに加速させる可能性を秘めています。Q学習について学ぶことは、人工知能技術の未来を理解する上で、大きな助けとなるでしょう。この解説が、皆様のQ学習への理解を深めるための一助となれば幸いです。
| 項目 | 説明 |
|---|---|
| 強化学習 | 試行錯誤を通じて学習する方法 |
| Q学習 | 強化学習の一種で、行動の価値を学習する手法 |
| Qテーブル | 状況と行動の組み合わせに対する価値を記録した表 |
| 学習プロセス | 行動→結果(報酬/罰)→Qテーブル更新 |
| 応用例 | ゲーム、ロボット制御など |
| メリット | 変化する状況への対応、単純な仕組み、実装が容易 |
| 将来性 | より複雑な問題への対応 |