勾配消失問題とは?原因・影響・対策を初心者向けに解説

AIの初心者
「勾配消失問題」って、どういう意味ですか?深層学習でよく出てきますが、少し難しく感じます。

AI専門家
勾配消失問題とは、層が深いニューラルネットワークを学習させるときに、重みを更新するための勾配が入力側へ戻るほど小さくなり、学習が進みにくくなる現象です。高い場所から流した水が、途中で弱くなって麓まで届かないようなイメージです。
AIの初心者
なるほど。なぜ勾配は入力側へ戻るほど小さくなってしまうのですか?
AI専門家
ニューラルネットワークの学習では、出力側から入力側へ誤差を逆向きに伝えます。その途中で小さな値を何度も掛け合わせると、勾配が急速に0へ近づきます。すると入力に近い層ほどほとんど更新されず、深いモデルなのに十分な表現を学べなくなります。
深層学習では、層を深くすることで画像、音声、文章などの複雑な特徴を段階的に学習できます。しかし、層を増やせば必ず性能が上がるわけではありません。代表的な壁の一つが勾配消失問題です。
勾配消失問題を理解するには、「勾配」「誤差逆伝播」「活性化関数」の関係を押さえる必要があります。この記事では、勾配消失問題とは何か、なぜ起こるのか、深層学習にどのような影響を与えるのか、どのような対策が使われるのかを初心者向けに整理します。
勾配消失問題とは
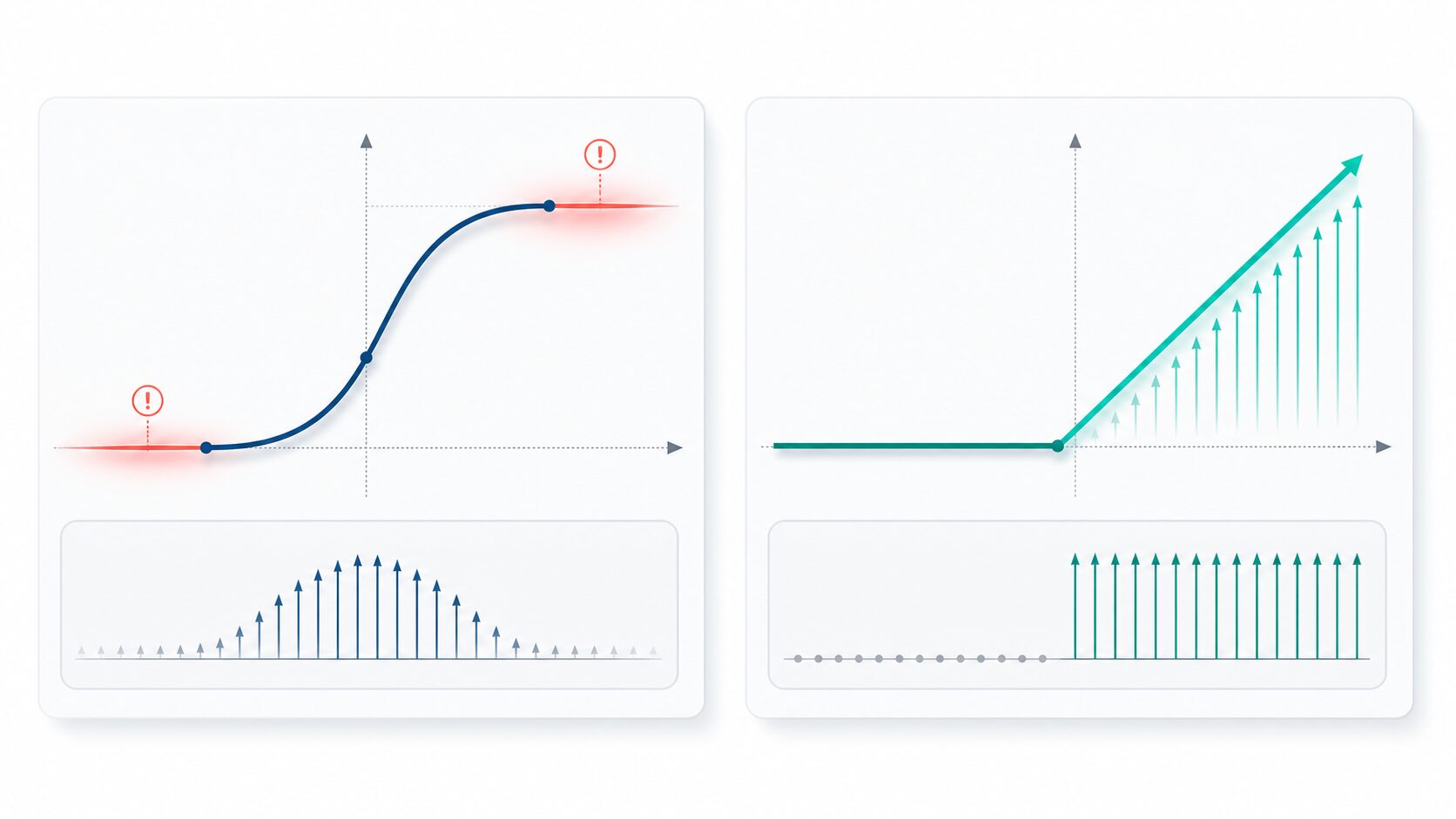
勾配消失問題とは、ニューラルネットワークの学習中に勾配が非常に小さくなり、重みがほとんど更新されなくなる現象です。特に、層を多く重ねた深いニューラルネットワークで起こりやすい問題として知られています。
ニューラルネットワークは、予測結果と正解のずれを小さくするように重みを調整します。この調整の手がかりになるのが勾配です。勾配は、簡単に言えば「どの方向へ、どのくらい重みを動かせば損失が小さくなるか」を示す値です。
勾配が十分に伝わっていれば、各層の重みは少しずつ適切な方向へ更新されます。一方で、勾配が0に近いほど更新量は小さくなります。入力に近い層まで勾配が届かないと、深い層を用意しても、その一部がほとんど学習に参加できません。
その結果、学習を長く続けても損失が下がりにくい、精度が伸びない、深いモデルの利点を活かせないといった状態になります。これが深層学習の初期から大きな課題だった勾配消失問題です。
勾配が消える仕組み
\(\frac{\partial L}{\partial w_1} =
\frac{\partial L}{\partial a_n}
\cdot
\frac{\partial a_n}{\partial a_{n-1}}
\cdot
\frac{\partial a_{n-1}}{\partial a_{n-2}}
\cdots
\frac{\partial a_1}{\partial w_1}
\)
ニューラルネットワークでは、入力から出力へ情報を流して予測を行います。その後、出力と正解の差から損失を計算し、出力側から入力側へ向かって誤差を伝えながら重みを更新します。この手順を誤差逆伝播法と呼びます。
誤差逆伝播では、層ごとの微分値を連鎖的に掛け合わせて勾配を求めます。ここで重要なのは、掛け算が何度も続くことです。例えば 0.5 を10回掛けると約0.001になり、0.25を10回掛けるとほとんど0に近づきます。
深いニューラルネットワークでは、この掛け算の回数が増えます。各層の微分値が1より小さい状態が続くと、入力側へ戻るほど勾配は指数関数的に小さくなります。これが「勾配が消える」と表現される理由です。
直感的には、出力側でははっきりしていた学習の指示が、層をさかのぼるうちに弱まり、入力側の層に届くころにはほぼ聞こえなくなる状態です。入力側の層は低レベルな特徴を学ぶ役割を持つため、ここが更新されないとモデル全体の学習も不安定になります。
活性化関数との関係
勾配消失問題には、活性化関数の選び方が深く関わります。活性化関数は、各ニューロンの入力を変換して次の層へ渡す関数です。ニューラルネットワークが複雑なパターンを学べるのは、活性化関数によって非線形性を取り入れているためです。
代表的な例がシグモイド関数です。シグモイド関数は入力を0から1の範囲へ滑らかに変換するため、確率のような値を表したい場面では便利です。しかし、入力が大きすぎる、または小さすぎる領域では曲線が平らになり、導関数が0に近づきます。
さらに、シグモイド関数の導関数の最大値は0.25です。誤差逆伝播でこのような小さな値を何層にもわたって掛けると、勾配は急速に小さくなります。そのため、シグモイド関数を深い隠れ層で多用すると、勾配消失問題が起こりやすくなります。
一方、ReLUは正の入力をそのまま出力し、正の領域では勾配が保たれやすい活性化関数です。深いニューラルネットワークで広く使われる理由の一つは、シグモイド関数よりも勾配消失を起こしにくい点にあります。ただし、負の入力が続くと出力が0のままになり、そのニューロンが学習しにくくなる場合もあるため、Leaky ReLUなどの派生形が使われることもあります。
| 活性化関数 | 特徴 | 勾配消失との関係 |
|---|---|---|
| シグモイド関数 | 出力を0から1の範囲に収める。確率表現と相性がよい。 | 導関数が小さくなりやすく、深い隠れ層では勾配消失を起こしやすい。 |
| tanh関数 | 出力を-1から1の範囲に収める。 | シグモイドより扱いやすい場面もあるが、入力が大きい領域では勾配が小さくなる。 |
| ReLU | 正の入力をそのまま通し、負の入力を0にする。 | 正の領域で勾配が保たれやすく、勾配消失を軽減しやすい。 |
勾配消失問題が学習に与える影響
勾配消失問題が起きると、入力側に近い層の重みがほとんど更新されません。深層学習では、入力側の層が単純な特徴を捉え、後段の層がより抽象的な特徴へ組み立てていくことが多いため、前段の学習が止まると全体の表現力が落ちます。
画像認識であれば、エッジや模様のような基礎的な特徴がうまく学ばれない可能性があります。自然言語処理や時系列データでは、前の時点の情報が後の判断へ十分に伝わらず、長期的な依存関係を扱いにくくなることがあります。
また、勾配消失は学習ログにも表れます。損失がなかなか下がらない、訓練精度が伸びない、初期層の重み変化が極端に小さいといった症状が見られます。単にデータが足りない、モデルが小さい、学習率が悪いといった問題と混同しやすいため、原因を切り分ける視点が必要です。
重要なのは、勾配消失問題は「深いモデルが悪い」という意味ではないことです。深いモデルを安定して学習させるには、活性化関数、初期値、正規化、ネットワーク構造を適切に設計する必要がある、という問題です。
勾配消失問題への主な対策
勾配消失問題への対策は、一つの方法だけで完結するとは限りません。実際には、モデルの種類、データ、タスクに応じて複数の工夫を組み合わせます。ここでは代表的な対策を整理します。
活性化関数の変更は、最も基本的な対策の一つです。深い隠れ層ではシグモイド関数よりもReLUやその派生形を使うことで、勾配が伝わりやすくなります。画像系の畳み込みニューラルネットワークでも、ReLU系の活性化関数は標準的に使われています。
重みの初期値を適切に設定することも重要です。初期値が大きすぎると学習が不安定になり、小さすぎると信号や勾配が弱くなります。Xavier初期化やHe初期化は、層を通過する信号や勾配の大きさを保ちやすくするための代表的な方法です。
バッチ正規化は、層への入力分布を安定させることで学習を進めやすくする手法です。勾配消失だけを直接解決する道具ではありませんが、深いモデルの学習を安定させ、より大きな学習率を使いやすくする効果があります。
時系列データでは、LSTMやGRUのようなゲート構造を持つネットワークが使われます。これらは情報をどれだけ保持し、どれだけ忘れるかを制御する仕組みを持つため、単純なRNNより長期依存を学習しやすくなります。
| 対策 | 狙い | 補足 |
|---|---|---|
| ReLU系の活性化関数 | 正の領域で勾配を保ちやすくする。 | Leaky ReLU、ELU、GELUなども用途に応じて使われる。 |
| Xavier初期化・He初期化 | 層を通る信号や勾配の大きさを保ちやすくする。 | 活性化関数に合わせて初期化方法を選ぶ。 |
| バッチ正規化 | 学習中の分布を安定させる。 | 深いモデルの学習を進めやすくする代表的な手法。 |
| LSTM・GRU | 時系列データで長期的な情報を保持しやすくする。 | 単純なRNNで起こりやすい勾配消失を軽減する。 |
| 残差接続 | 勾配が伝わる経路を増やす。 | ResNetのような深いモデルで重要な設計。 |
勾配爆発問題との違い
勾配消失問題と一緒に理解しておきたいのが、勾配爆発問題です。どちらも誤差逆伝播で勾配が安定して伝わらない問題ですが、症状は反対です。
勾配消失問題では、勾配が0に近づき、重みがほとんど更新されません。一方、勾配爆発問題では、勾配が非常に大きくなり、重みが過剰に更新されて学習が不安定になります。損失が急に大きくなる、数値が発散する、学習が途中で壊れるといった形で現れます。
対策も一部は異なります。勾配消失には活性化関数や初期化、残差接続が有効です。勾配爆発には、勾配クリッピング、学習率の調整、正規化、適切な初期化がよく使われます。実務では、どちらか一方だけでなく、勾配の大きさが小さすぎないか、大きすぎないかを同時に確認することが大切です。
| 項目 | 勾配消失問題 | 勾配爆発問題 |
|---|---|---|
| 勾配の状態 | 非常に小さくなる。 | 非常に大きくなる。 |
| 主な症状 | 学習が進まない、初期層が更新されにくい。 | 損失が発散する、重みが不安定に変化する。 |
| 代表的な対策 | ReLU系活性化関数、初期化、正規化、残差接続。 | 勾配クリッピング、学習率調整、初期化、正規化。 |
学習や実務で確認したいポイント
勾配消失問題を疑うときは、まず学習の挙動を確認します。訓練損失がほとんど下がらない、訓練精度も検証精度も低いまま動かない、学習率を変えても改善が小さい場合は、勾配が十分に伝わっていない可能性があります。
可能であれば、層ごとの勾配ノルムや重みの更新量を確認します。出力側の層では勾配があるのに、入力側の層ほど極端に小さくなっているなら、勾配消失が起きているかもしれません。深いモデルを扱うフレームワークでは、学習ログや可視化ツールを使ってこのような状態を追跡できます。
初心者が注意したいのは、勾配消失を単独の原因として決めつけないことです。データの前処理不足、ラベルの誤り、学習率の設定、モデル容量、正則化の強さなどでも学習は停滞します。まず小さなモデルや少量データで学習できるかを確認し、次に深くしたときの勾配や損失の変化を見ると、原因を切り分けやすくなります。
実務では、既存のアーキテクチャを利用することも有効です。ResNet、Transformer、LSTM/GRUなどには、勾配を安定して伝えるための設計が含まれています。基礎を理解した上で、タスクに合う実績ある構造を選ぶことが、安定したモデル開発につながります。

まとめ
勾配消失問題は、深いニューラルネットワークで誤差を逆向きに伝える際、勾配が入力側へ戻るほど小さくなり、重みが十分に更新されなくなる現象です。特に、シグモイド関数のように導関数が小さくなりやすい活性化関数を深い隠れ層で使うと起こりやすくなります。
この問題が起きると、入力側の層が学習に参加しにくくなり、損失が下がりにくい、精度が伸びない、深いモデルの利点を活かせないといった影響が出ます。対策としては、ReLU系の活性化関数、Xavier初期化やHe初期化、バッチ正規化、残差接続、LSTM/GRUなどが使われます。
勾配消失問題は、深層学習を理解するうえで重要な基礎概念です。仕組みを押さえておくと、モデルがうまく学習しないときに、学習率やデータだけでなく、勾配の伝わり方にも目を向けられるようになります。
更新履歴
| 日付 | 内容 |
|---|---|
| 2025年2月2日 | 初回公開 |
| 2026年5月1日 | 勾配消失問題の定義、誤差逆伝播で起こる仕組み、活性化関数との関係、対策、勾配爆発問題との違いを初心者向けに再構成 |