人間と共に進化するAI:RLHF入門

AIの初心者
先生、「あーるえるえいちえふ」ってよく聞くんですけど、どういう意味ですか?

AI専門家
「あーるえるえいちえふ」は「強化学習による人間からのフィードバック」の略で、人間がAIの回答を評価して、その評価に基づいてAIが学習する方法のことだよ。
AIの初心者
人間の評価に基づいて学習するんですね。具体的にはどのように学習するんですか?
AI専門家
例えば、AIが質問にいくつか回答を生成したとします。人間がそれらの回答を「良い」「悪い」と評価することで、AIは「良い」と評価された回答の特徴を学習し、より良い回答を生成できるようになるんだ。 つまり、人間のフィードバックによってAIの性能が向上していくんだよ。
RLHFとは。
人工知能の分野で「強化学習による人間からのフィードバック」という学習方法があります。
はじめに

近ごろの技術革新によって、人工知能は目覚ましい発展を遂げ、様々な場所で活躍するようになりました。特に、人間の意見を学習に取り入れる方法である「人間からのフィードバックによる強化学習」、略して「強化学習HF」は、人工知能をより人間らしく、より実用的にするために欠かせない技術として注目されています。
従来の機械学習では、人間の持つ価値観や感覚を人工知能に反映させることは困難でした。例えば、文章の良し悪しを判断する際、文法的な正しさだけでなく、内容の面白さや表現の豊かさなども考慮する必要があります。しかし、これらの要素を数値化することは容易ではありませんでした。強化学習HFは、人間のフィードバックを直接学習に取り入れることで、この問題を解決する糸口となります。具体的には、人間が人工知能の出力結果を評価し、その評価に基づいて人工知能が学習を進めるという仕組みです。
強化学習HFの仕組みは、大きく分けて三つの段階に分かれています。まず、初期段階の人工知能モデルを用意し、様々な課題を与えて出力結果を得ます。次に、人間がこれらの出力結果を評価し、良し悪しを判断します。そして最後に、人間の評価を基に、人工知能モデルが学習を行い、より良い出力結果を出せるように調整を行います。このサイクルを繰り返すことで、人工知能は次第に人間の価値観や感覚に沿った出力を生成できるようになります。
強化学習HFは、文章生成や翻訳、画像生成など、様々な分野で応用が期待されています。例えば、文章生成においては、より自然で人間らしい文章を作成することが可能になります。また、翻訳においては、より正確でニュアンスに富んだ翻訳が可能になります。さらに、画像生成においては、人間の感性に訴えかけるような、より創造的な画像を生成することが可能になります。このように、強化学習HFは、人工知能の未来を担う重要な技術と言えるでしょう。今後、更なる研究開発が進み、様々な分野で活用されることで、私たちの生活はより豊かで便利なものになることが期待されます。
| 技術 | 概要 | 従来の課題 | 仕組み | 応用分野 |
|---|---|---|---|---|
| 強化学習HF (人間からのフィードバックによる強化学習) |
人間のフィードバックを学習に取り入れ、AIをより人間らしく、実用的にする技術 | 人間の価値観や感覚(例: 文章の面白さ、表現の豊かさ)をAIに反映させるのが困難 | 1. 初期AIモデルに課題を与え、出力結果を得る 2. 人間が出力結果を評価 3. 評価に基づきAIモデルが学習、調整 このサイクルを繰り返す |
文章生成、翻訳、画像生成など 例: より自然な文章、ニュアンスに富んだ翻訳、創造的な画像生成 |
強化学習とは

強化学習とは、機械が試行錯誤を通して学習する仕組みのことを指します。人間が犬をしつけるように、機械も良い行動をとれば褒美を与え、悪い行動をとれば罰を与えることで、望ましい行動を学習していきます。この褒美と罰に当たるものを、強化学習の世界では「報酬」と呼びます。
学習の舞台となるのは、ある特定の「環境」です。この環境の中で、機械は様々な行動をとります。そして、とった行動に応じて環境から報酬が与えられます。報酬が高いほど良い行動とされ、機械はそれを繰り返すように学習します。逆に、報酬が低い、あるいは罰となる行動は避けるように学習します。
例えば、ロボットに物を掴む作業を学習させるとします。掴むことに成功すれば報酬を与え、失敗すれば報酬を与えません。ロボットは、最初はランダムに手を動かしますが、次第に掴むことに成功する行動を見つけ出し、その行動を強化していきます。最終的には、高い確率で物を掴めるようになります。
このように、強化学習は明確な正解が分からない問題を解くのに役立ちます。正解を教えてもらうのではなく、試行錯誤とその結果得られる報酬を通じて、最適な行動を自ら学習していくのです。この学習方法は、ゲームの攻略やロボットの制御だけでなく、自動運転や創薬など、様々な分野で応用が期待されています。まさに、機械が自ら考え、行動を最適化していくための画期的な学習方法と言えるでしょう。
人間からのフィードバック

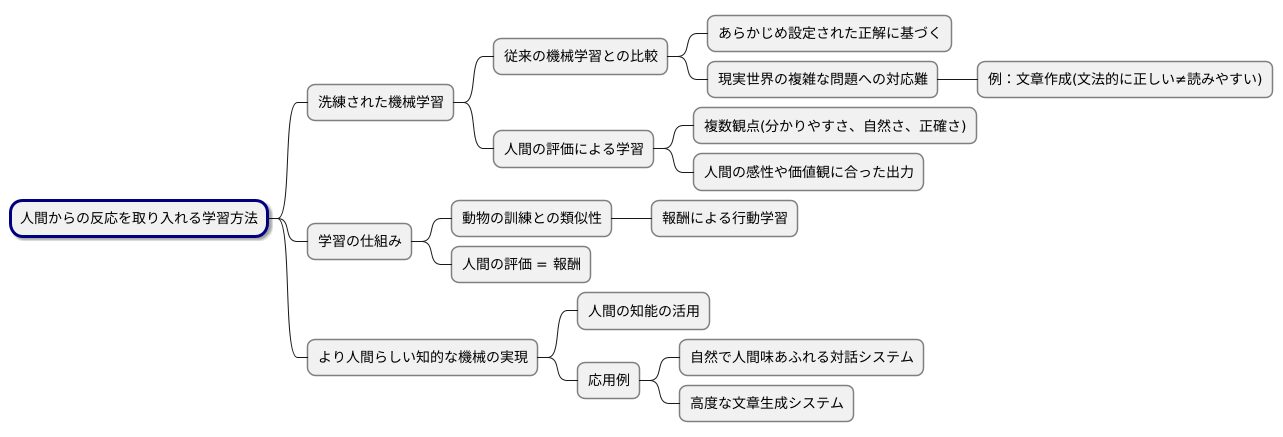
人間からの反応を取り入れる学習方法は、機械学習をより洗練されたものにするための重要な技術です。この学習方法では、人間が機械の行動を評価し、その評価結果を機械に教えることで、より良い行動を学習させます。
従来の機械学習では、あらかじめ設定された正解に基づいて学習が進められます。しかし、現実世界の複雑な問題を扱う場合、正解を明確に定義することが難しい場合があります。例えば、文章作成の場合、文法的に正しくても、読みやすく分かりやすい文章とは限りません。このような場面で役立つのが、人間からの反応を取り入れる学習方法です。
この方法では、機械が生成した文章に対して、人間が「良い」「悪い」といった評価を付けます。具体的には、「分かりやすさ」「自然さ」「正確さ」など、複数の観点から文章を評価し、その結果を機械にフィードバックします。機械はこのフィードバックをもとに、人間の感性や価値観に合った文章を生成するように学習します。
この学習の仕組みは、報酬を与えて動物を訓練する仕組みに似ています。良い行動をすれば報酬が与えられ、悪い行動をすれば報酬が与えられないため、動物は報酬がもらえる行動を学習します。人間からの反応を取り入れる学習方法も同様に、人間の評価を報酬として機械に与えることで、より望ましい行動を学習させます。
このように、人間からの反応を取り入れる学習方法は、人間の知能を機械学習に取り入れるための重要な技術であり、より人間らしい知的な機械の実現に貢献すると期待されています。例えば、この技術を応用することで、より自然で人間味あふれる対話システムや、より高度な文章生成システムを開発することが可能になります。
学習方法

人の手による教えを基に学ぶ段階から始めます。まるで生まれたばかりの子供のように、様々な振る舞いの仕方を学ぶために、人が用意した手本となるデータを使います。このデータには、好ましい行動や望ましい結果などが含まれており、これらを模倣することで、基礎となる振る舞いを身につけます。
次の段階では、試行錯誤を通じて学ぶ強化学習という方法を用います。この段階では、様々な行動を試し、その結果に応じて報酬が与えられます。ちょうど、犬をしつけるように、良い行動には褒美を与え、望ましくない行動には修正を促します。AIは、この報酬を最大化するために、試行錯誤を繰り返し、より良い行動を学習していきます。この報酬は人の手によって与えられます。人の判断に基づいて、AIの行動の良し悪しを評価し、それに応じた報酬を与えることで、人の意図に沿った行動を学習するように促します。
最後の段階では、実践的な環境での試験を行います。これは、学校で学んだことを実際に社会で試すようなものです。これまで学習してきたことを基に、現実世界の問題に取り組み、その成果を評価します。この評価結果を基に、更なる改善を行い、より高い能力を目指します。
このように、三つの段階を踏むことで、AIは人との協調性を高め、より複雑な課題をこなせるように成長していきます。人の教えから始まり、試行錯誤、そして実践経験を通じて、まるで人が成長していくように、AIも段階的に学習し、高度な能力を獲得していくのです。
| 段階 | 学習方法 | 説明 |
|---|---|---|
| 1. 模倣学習 | 人の手による教え | 生まれたばかりの子供のように、人が用意した手本となるデータ(好ましい行動や望ましい結果など)を模倣することで、基礎となる振る舞いを身につけます。 |
| 2. 強化学習 | 試行錯誤と報酬 | 様々な行動を試し、その結果に応じて人の手によって与えられる報酬を最大化することで、より良い行動を学習します。犬のしつけのように、報酬を通じて人の意図に沿った行動を学習します。 |
| 3. 実践学習 | 実践的な環境での試験 | 学校で学んだことを社会で試すように、現実世界の問題に取り組み、その成果を評価します。この評価結果を基に、更なる改善を行い、より高い能力を目指します。 |
応用事例

人間とのやり取りを必要とする場面で役立つ技術として、強化学習を用いた人間からのフィードバックによる学習、いわゆるRLHFが注目を集めています。この技術は、様々な分野での活用が期待されており、私たちの生活を大きく変える可能性を秘めています。
例えば、顧客対応の自動化です。従来の自動応答システムは、あらかじめ決められたパターンでしか対応できませんでしたが、RLHFを導入することで、より自然で柔軟な対応が可能になります。顧客の様々な質問や要望に対して、まるで人間と話しているかのようなスムーズなやり取りを実現し、顧客満足度向上に貢献します。
また、個々の利用者に合わせた個別対応支援もRLHFの得意とするところです。利用者の好みや習慣を学習し、最適な情報やサービスを提供することで、生活をより便利で豊かにします。さらに、教育の分野でも、生徒一人ひとりの学習状況に合わせた個別指導を実現するなど、教育の質向上に大きく貢献することが期待されます。
娯楽の分野でも、RLHFは革新をもたらします。ゲームでは、より人間らしい行動や反応をするキャラクターが登場し、よりリアルで奥深いゲーム体験が可能になります。ロボットの制御にも応用することで、より滑らかで自然な動きを実現し、人間とロボットの協働作業をよりスムーズにします。
医療や金融といった専門知識が必要な分野でも、RLHFは力を発揮します。膨大なデータから最適な判断材料を抽出し、医師や金融専門家の意思決定を支援することで、より正確で効率的な業務遂行を可能にします。このように、RLHFは、様々な分野で人間の能力を拡張し、より良い社会を実現するための鍵となる技術と言えるでしょう。
| 分野 | RLHFの活用例 | 効果 |
|---|---|---|
| 顧客対応 | より自然で柔軟な対応 | 顧客満足度向上 |
| 個別対応支援 | 利用者の好みや習慣を学習し、最適な情報やサービスを提供 | 生活の利便性と豊かさの向上 |
| 教育 | 生徒一人ひとりの学習状況に合わせた個別指導 | 教育の質向上 |
| 娯楽(ゲーム) | より人間らしい行動や反応をするキャラクター | リアルで奥深いゲーム体験 |
| 娯楽(ロボット制御) | より滑らかで自然な動き | 人間とロボットの協働作業の円滑化 |
| 医療・金融 | 最適な判断材料の抽出と意思決定支援 | 正確で効率的な業務遂行 |
今後の展望

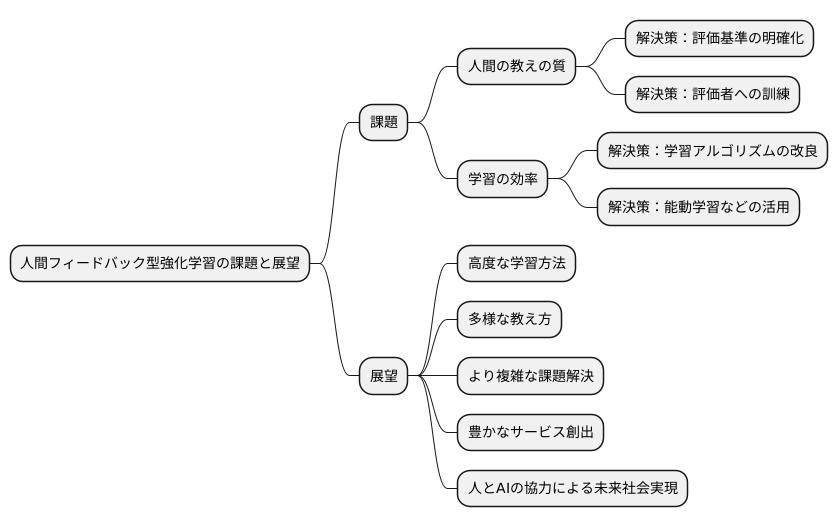
人間からの手ほどきを取り入れた強化学習、いわゆる人間フィードバック型強化学習は、人工知能開発における革新的な手法として注目を集めていますが、発展途上の技術であるがゆえに、幾つかの課題も抱えています。今後の展望を考える上で、これらの課題を理解し、解決への道筋を探ることが重要です。
まず、人間からの教えの質をどう保つかという問題があります。人工知能の学習は、人間の評価に基づいて行われますが、評価の基準が人によって異なったり、評価自体に偏りがあったりすると、人工知能の学習に悪影響を及ぼす可能性があります。そのため、評価基準を明確化し、評価を行う人たちの訓練を徹底するなど、教えの質を管理するための仕組みづくりが不可欠です。
次に、学習の効率を高める方法も重要な課題です。人間からの教えを得るには、手間と時間がかかります。限られた時間の中で、より効果的に学習を進めるためには、学習アルゴリズムの改良や、人間からの教えを効率的に活用する手法の開発が求められます。例えば、人工知能が自ら学習に役立つ情報を求める能動学習といった技術の活用が期待されます。
これらの課題を乗り越えることができれば、人間フィードバック型強化学習は、人工知能の発展を大きく前進させる可能性を秘めています。より高度な学習方法や、多様な教え方を取り入れることで、人工知能はより複雑な課題を解決できるようになり、私たちの社会生活をより豊かにする様々なサービスを生み出すことが期待されます。そして、人と人工知能が互いに協力し合う未来社会の実現に大きく貢献すると信じています。人間フィードバック型強化学習は、人と人工知能が共に進化していく未来を象徴する技術と言えるでしょう。