Mixup:画像合成による精度向上

AIの初心者
先生、『混ぜ合わせ』って、二つの絵を混ぜるんですよね?どんな風に混ぜるんですか?

AI専門家
そうだね、二つの絵を混ぜ合わせるんだけど、単に重ねるだけではないんだ。例えば、猫の絵と犬の絵を混ぜるとするね。それぞれの絵に、0.7と0.3のような重みをつけて、混ぜ合わせるんだ。0.7の重みをつけた猫の絵と、0.3の重みをつけた犬の絵を混ぜると、猫の特徴が強い、少しだけ犬っぽい絵ができるんだよ。
AIの初心者
なるほど。じゃあ、出来た絵には、「猫と犬がいます」っていう二つの答えがつくんですか?
AI専門家
正解!その通り。混ぜ合わせた比率に合わせて、答えも混ぜ合わせるんだ。例えば、先ほどの例だと「猫:0.7、犬:0.3」のようにね。こうすることで、あいまいな絵も学習できるようになるから、より賢いAIになるんだよ。
Mixupとは。
「人工知能」に関する言葉である「混ぜ合わせ」(混ぜ合わせとは、データを増やす方法の一つです。この方法では、二枚の絵を混ぜ合わせて新しい絵を作ります。この方法を使うと、ばらつきを抑える効果が出て、絵の中間の見分け方もできるようになり、結果として正答率が上がりました。)について
混ぜ合わせの仕組み

混ぜ合わせは、二つの絵を混ぜて、新しい学習用の絵を作る方法です。これは、絵の数を増やす工夫の一つです。具体的には、まず二つの絵をでたらめに選びます。次に、どのくらいの割合で混ぜるかを決めるために、ゼロから一の間の数をでたらめに選びます。たとえば、この数が0.3だったとしましょう。すると、一枚目の絵は三割、二枚目の絵は七割の割合で混ぜ合わせることになります。
混ぜるのは絵の色だけではありません。それぞれの絵に付いている正解の札も、同じ割合で混ぜます。たとえば、一枚目の絵が「いぬ」で二枚目の絵が「ねこ」だとしましょう。先ほどの割合で混ぜると、新しい絵に付く札は「いぬ」三割と「ねこ」七割が混ざったものになります。
こうして、全く新しい絵とそれに対応する札が生まれます。この新しい絵は、元の二つの絵の特徴を両方とも持っています。だから、この新しい絵で学習すれば、色々な種類の絵で学習したのと同じ効果が得られます。これは、二枚の絵の間にある情報を埋めるような働きがあり、結果として、学習した機械は、より滑らかな線引きで絵を区別できるようになります。
たとえば、機械に「いぬ」と「ねこ」を見分ける学習をさせるとします。混ぜ合わせを使わない場合、機械は「いぬ」と「ねこ」の境界線をはっきりと引いてしまうかもしれません。しかし、混ぜ合わせを使うと、「いぬ」と「ねこ」の間にある色々な段階の絵、たとえば「いぬ」三割と「ねこ」七割の混ざった絵を学習することができます。その結果、機械は境界線を滑らかに引くことができ、「いぬ」と「ねこ」の微妙な違いも理解できるようになります。
このように、混ぜ合わせは、限られた数の絵からたくさんの学習用の絵を作り出し、機械の学習能力を向上させるための、とても役に立つ方法です。
| 混ぜ合わせとは | 二つの絵を混ぜて、新しい学習用の絵を作る方法 |
|---|---|
| 目的 | 絵の数を増やし、学習データのバリエーションを増やす |
| 手順 |
|
| 混ぜ合わせの対象 | 絵の色と正解ラベル |
| 効果 |
|
| 例 | 「いぬ」と「ねこ」の画像を混ぜることで、両方の特徴を持つ画像を生成し、より正確な分類を可能にする |
正則化の効果

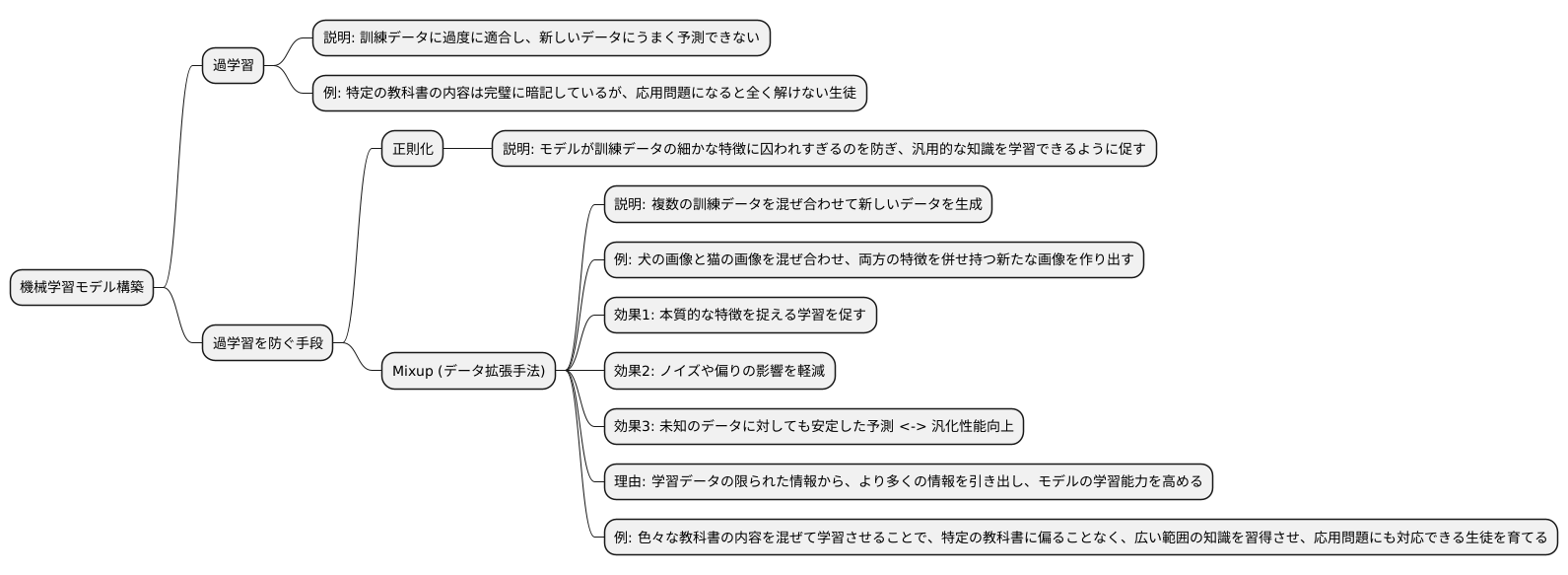
機械学習モデルを構築する際、しばしば「過学習」という問題に直面します。過学習とは、訓練データに過度に適合しすぎてしまい、新しいデータに対してうまく予測できない状態のことです。まるで、特定の教科書の内容は完璧に暗記しているのに、応用問題になると全く解けない生徒のようなものです。
この過学習を防ぐための有効な手段の一つとして、「正則化」と呼ばれる手法があります。正則化は、モデルが訓練データの細かな特徴に囚われすぎるのを防ぎ、より汎用的な知識を学習できるように促します。
「Mixup」と呼ばれるデータ拡張手法は、この正則化の効果を発揮する有力な方法の一つです。Mixupは、複数の訓練データを混ぜ合わせて、新しいデータを生成する技術です。例えば、犬の画像と猫の画像を混ぜ合わせ、両方の特徴を併せ持つ新たな画像を作り出すことができます。
このMixupを用いることで、モデルは個々のデータの些細な違いに過剰に反応するのではなく、本質的な特徴を捉える学習を促されます。訓練データに含まれるノイズや偏りの影響も軽減され、結果として未知のデータに対しても安定した予測が可能になります。これは、学習データの限られた情報から、より多くの情報を引き出し、モデルの学習能力を高める効果があるためです。
つまり、Mixupは、いわば色々な教科書の内容を混ぜて学習させることで、特定の教科書に偏ることなく、より広い範囲の知識を習得させ、応用問題にも対応できる生徒を育てるようなものです。これにより、モデルの汎化性能が向上し、実用的な場面でより信頼性の高い予測を実現できるようになります。
あいまいさの学習

物の見分け方をうまくできるようにするために、混ぜ合わせるやり方を試します。たとえば、犬の絵と猫の絵を混ぜてみます。混ぜると、犬と猫、両方の特徴を持った絵ができます。この混ぜ合わせた絵を使って学習することで、機械は「犬みたいな猫」や「猫みたいな犬」といった、はっきりとはどちらとも言えない絵も正しく見分けられるようになります。
これまでのやり方では、このようなあいまいな絵を正しく見分けるのは難しかったのですが、この混ぜ合わせるやり方を使うと、絵に隠れている、見た目にはわからない特徴も掴むことができるようになります。
私たちが暮らす世界には、はっきり何かに分類できないものがたくさんあります。たとえば、少しだけ赤い黄色や、少しだけ黄色い赤など、微妙な色の違いは、赤とも黄色とも言い切れないことがあります。また、成長過程の子どもは、大人でも子どもでもない、その中間の段階です。このような、あいまいなものを正しく見分ける能力は、複雑な現実世界を理解するためにとても大切です。
混ぜ合わせる学習方法を使うと、機械は色々な変化にも対応できる強い力を持つようになります。なぜなら、はっきりとは区別できないあいまいなデータも学習に使うことで、見たことがないようなデータに対しても、より柔軟に対応できるようになるからです。これは、機械がより賢く、より信頼できるものになるために、とても役立つと言えるでしょう。
| 問題点 | 解決策 | メリット | 結論 |
|---|---|---|---|
| 従来の方法では、あいまいな絵(犬みたいな猫、猫みたいな犬など)を正しく見分けるのが難しい。 | 犬の絵と猫の絵を混ぜ合わせることで、両方の特徴を持った絵を作り、学習に利用する。 |
|
機械がより賢く、より信頼できるものになる。 |
精度の向上

学習のやり方を少し工夫することで、物の見分けの正確さをぐんと上げることができる方法があります。これを「混ぜ合わせ学習」と呼びましょう。この方法は、様々な課題、特に絵で見分ける作業で、成績を上げるのに役立つことが分かっています。「混ぜ合わせ学習」は、学習データを混ぜ合わせることで、いわば「あいまいな」データを新しく作り出し、それから学習を行います。たとえば、犬の絵と猫の絵を混ぜ合わせて、犬と猫の特徴を両方持つ、あいまいな絵を作り出すのです。
なぜこのような方法が効果的なのかというと、大きく分けて二つの理由があります。一つ目は、混ぜ合わせることで、実際には存在しないようなデータも学習に使えるようになるため、学習に使える絵のバリエーションが増えるということです。色々な絵の組み合わせで学習することで、特定の絵の特徴に偏ることなく、より本質的な特徴を捉えることができるようになります。これは、いわば色々な練習問題を解くことで、試験でどんな問題が出ても対応できるようになるようなものです。二つ目は、あいまいな絵を学習することで、白黒はっきりしないものも上手に判断できるようになるということです。たとえば、犬と猫が混ざった絵を「犬と猫の両方の特徴を持つもの」と判断できるようになることで、判断の幅が広がり、より柔軟な対応が可能になります。
特に、学習に使える絵の数が少ない場合や、絵がぼやけている場合などは、「混ぜ合わせ学習」の効果がより顕著に現れます。少ない情報からでも多くのことを学ぶことができ、あいまいな情報にも惑わされにくくなるからです。この「混ぜ合わせ学習」は、やり方は単純ですが、物の見分けの正確さを上げるための、とても強力な方法と言えるでしょう。この方法をうまく活用することで、様々な場面で、より正確な判断ができるようになる可能性を秘めています。
| 混ぜ合わせ学習とは | 学習データを混ぜ合わせて、あいまいなデータを新しく作り出し、学習を行う方法 |
|---|---|
| 効果 | 物の見分けの正確さを上げる |
| 理由1 | 学習に使えるデータのバリエーションが増えるため、本質的な特徴を捉えることができる |
| 理由2 | あいまいな絵を学習することで、白黒はっきりしないものも上手に判断できるようになる |
| 効果的な場面 | 学習に使える絵の数が少ない場合や、絵がぼやけている場合 |
| 結論 | 物の見分けの正確さを上げるための強力な方法 |
実装の容易さ

混ぜ合わせ増強と呼ばれる手法は、導入のしやすさが大きな利点です。プログラムに少し手を加えるだけで、今までの学習手順にこの手法を組み込むことができます。多くの深層学習の仕組みでは、この手法を扱う機能が既に用意されているので、すぐに利用できます。この手軽さは、研究者や開発者にとって大きな魅力であり、混ぜ合わせ増強が広く使われている理由の一つです。簡単に導入できるため、様々な学習の型やデータの集まりで試すことができ、最適な学習方法を探す上で強力な道具となります。
具体的には、二つの学習データを混ぜ合わせることで、新たな学習データを作り出します。例えば、画像認識の場合、二つの画像を混ぜ合わせて、新しい画像を作り出します。この混ぜ合わせの割合は、ランダムに決められます。混ぜ合わせる割合は、0から1の間の値で表され、0に近いほど一方の画像の影響が強くなり、1に近いほどもう一方の画像の影響が強くなります。
混ぜ合わせ増強は、過学習を抑える効果があります。過学習とは、学習データに過剰に適応してしまい、未知のデータに対してうまく対応できなくなる現象です。混ぜ合わせ増強は、学習データを混ぜ合わせることで、データの多様性を増やし、過学習を抑える効果があります。
また、混ぜ合わせ増強は、モデルの頑健性を高める効果もあります。頑健性とは、ノイズや外れ値などの影響を受けにくい性質のことです。混ぜ合わせ増強は、学習データを混ぜ合わせることで、ノイズや外れ値の影響を軽減し、モデルの頑健性を高める効果があります。
混ぜ合わせ増強は、画像認識だけでなく、自然言語処理など、様々な分野で応用されています。その手軽さと効果から、今後も様々な分野で活用されていくことが期待されます。
| 手法 | メリット | 効果 | 具体例 |
|---|---|---|---|
| 混ぜ合わせ増強 | 導入が容易 多くの深層学習で標準搭載 |
過学習の抑制 モデルの頑健性向上 |
画像認識:二つの画像を混ぜ合わせて新たな学習データを作成 混ぜ合わせの割合は0から1の間でランダムに決定 |
今後の展望

混ぜ合わせる手法は、図を分類するだけでなく、ものの場所を見つけたり、図を切り分けたりといった他の使い方にも期待が高まっています。この手法は、違う種類の図を混ぜ合わせることで、学習データの量を増やし、ものの特徴をより深く学ぶのに役立ちます。
現在、この混ぜ合わせ手法をより良くしたり、その考え方を広げた新しいデータを増やす方法の研究が盛んに行われています。例えば、混ぜ合わせる割合を自動的に調整したり、混ぜ合わせる対象をより多様化したりすることで、より効果的な学習が可能になると考えられています。
将来的には、この手法はさらに進化し、様々な分野で活用されることが期待されます。医療分野では、少ないデータからでも病気を正確に診断するのに役立つ可能性があります。また、製造業では、不良品を自動的に見つけるシステムの精度向上に貢献するかもしれません。
さらに高度な混ぜ合わせ手法や、他のデータを増やす方法との組み合わせにより、今以上の精度向上や新しい応用可能性が生まれる可能性を秘めています。例えば、図の一部だけを混ぜ合わせたり、混ぜ合わせる際にものの形や色などの特徴を考慮したりすることで、より効果的な学習が可能になるかもしれません。
混ぜ合わせ手法は、深い学びにおけるデータ増強の新しい可能性を切り開き、今後の発展が非常に楽しみな技術です。この技術の進歩により、人工知能はより賢く、より人間に役立つものへと進化していくことでしょう。
| 混ぜ合わせ手法のメリット | 現状と今後の研究 | 将来的な応用 |
|---|---|---|
| 学習データの量を増やし、ものの特徴をより深く学ぶのに役立つ | 混ぜ合わせる割合の自動調整、混ぜ合わせる対象の多様化など、より効果的な学習方法の研究 | 医療分野:少ないデータでの病気の正確な診断 製造業:不良品自動検出システムの精度向上 |
| 図の分類、ものの場所特定、図の切り分けなど、様々な用途に活用できる | より高度な混ぜ合わせ手法や、他のデータ増やす方法との組み合わせの研究 | 更なる精度向上や新しい応用可能性 |