データの正規化とは?計算方法・仕組み・活用例をわかりやすく解説

AIの初心者
「正規化」って何ですか?0から1にする、と聞いてもまだよく分かりません。

AI専門家
正規化とは、データの値を一定の範囲にそろえる前処理です。代表的には、最小値を0、最大値を1として、ほかの値も0から1の間に変換します。100点満点のテストと50点満点のテストを比べるとき、点数を同じ尺度に直すと比較しやすくなります。
AIの初心者
同じ尺度に直すんですね。AIや機械学習では、なぜ正規化が必要なんですか?
AI専門家
機械学習では、年齢、価格、面積、ピクセル値のように範囲が大きく違うデータを同時に扱います。範囲がばらばらだと一部の特徴量が強く効きすぎることがあるため、正規化で値の範囲をそろえます。ただし、外れ値があると結果が歪みやすいので、標準化などとの使い分けも大切です。
正規化とは。
正規化は、数値データの範囲をそろえるための前処理です。特に、最小値と最大値を使って0から1へ変換する方法は「min-max正規化」と呼ばれ、AIや機械学習、統計、データ分析でよく使われます。この記事では、正規化の意味、計算式、標準化との違い、実務での注意点を初心者向けに整理します。
データの正規化とは
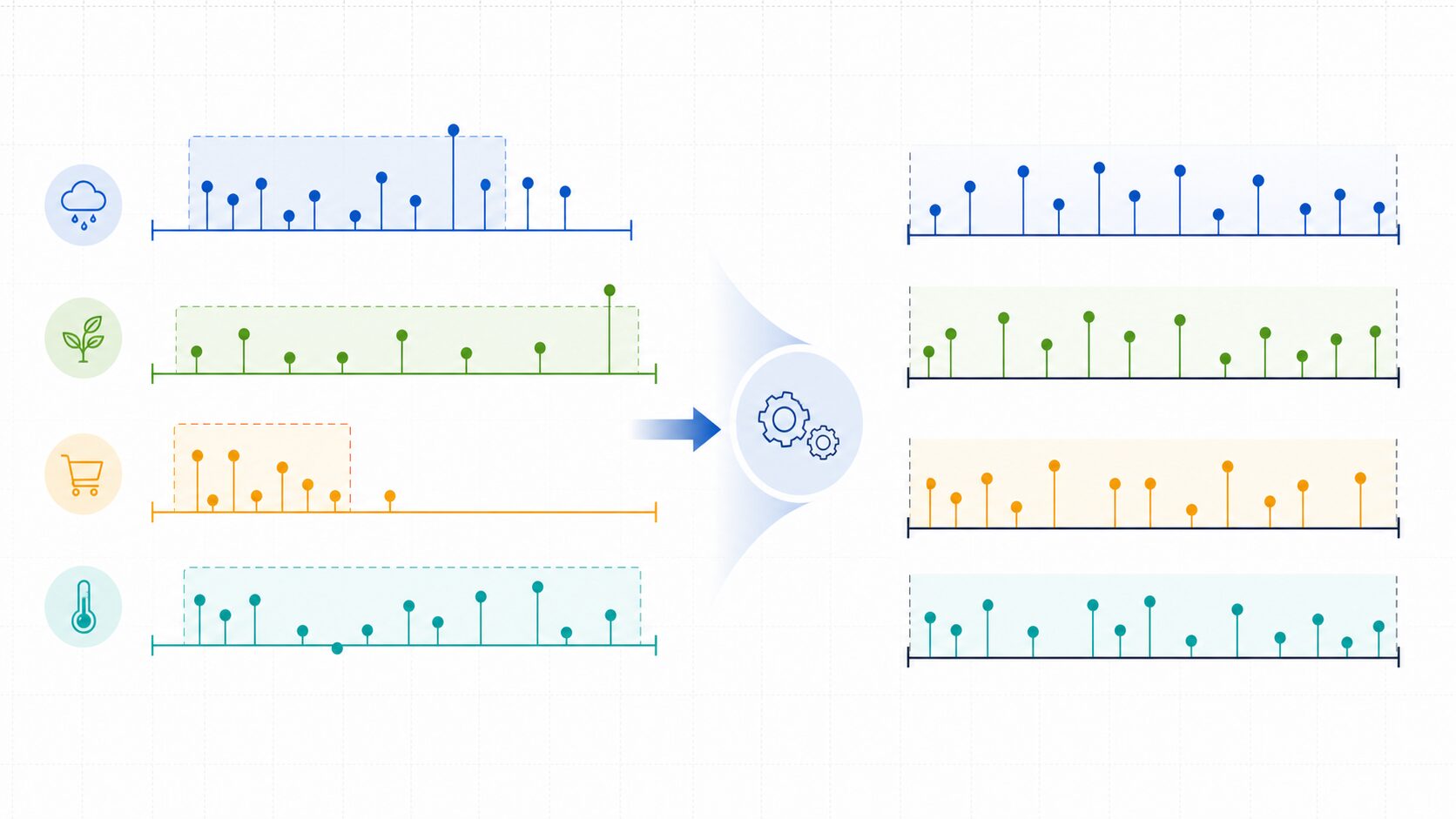
データの正規化とは、異なる範囲を持つ数値を、一定の範囲に変換して扱いやすくする処理です。この記事で中心に扱うのは、データの最小値を0、最大値を1に対応させる方法です。
たとえば、あるデータに「年齢」と「年収」が含まれているとします。年齢は0から100程度、年収は数百万円から数千万円のように、数値の大きさがまったく違います。このまま機械学習モデルへ入れると、値の大きい年収のほうが重要であるかのように扱われることがあります。正規化を行うと、どちらも0から1の範囲に収まり、モデルが値の大きさだけに引っ張られにくくなります。
正規化は、元の値の大小関係を保ったまま範囲だけを変える線形変換です。最小値だったデータは0、最大値だったデータは1になり、その間の値は相対的な位置に応じて0から1の間へ配置されます。つまり、単位や桁数が違うデータを同じ物差しの上に並べ直す処理だと考えると理解しやすいでしょう。
| 項目 | 内容 |
|---|---|
| 目的 | 異なる範囲の数値を比較しやすくする |
| 代表的な変換先 | 0から1の範囲 |
| よく使う場面 | 機械学習の前処理、画像処理、データ分析 |
| 注意点 | 最小値と最大値を使うため、外れ値の影響を受けやすい |
正規化の計算方法と式
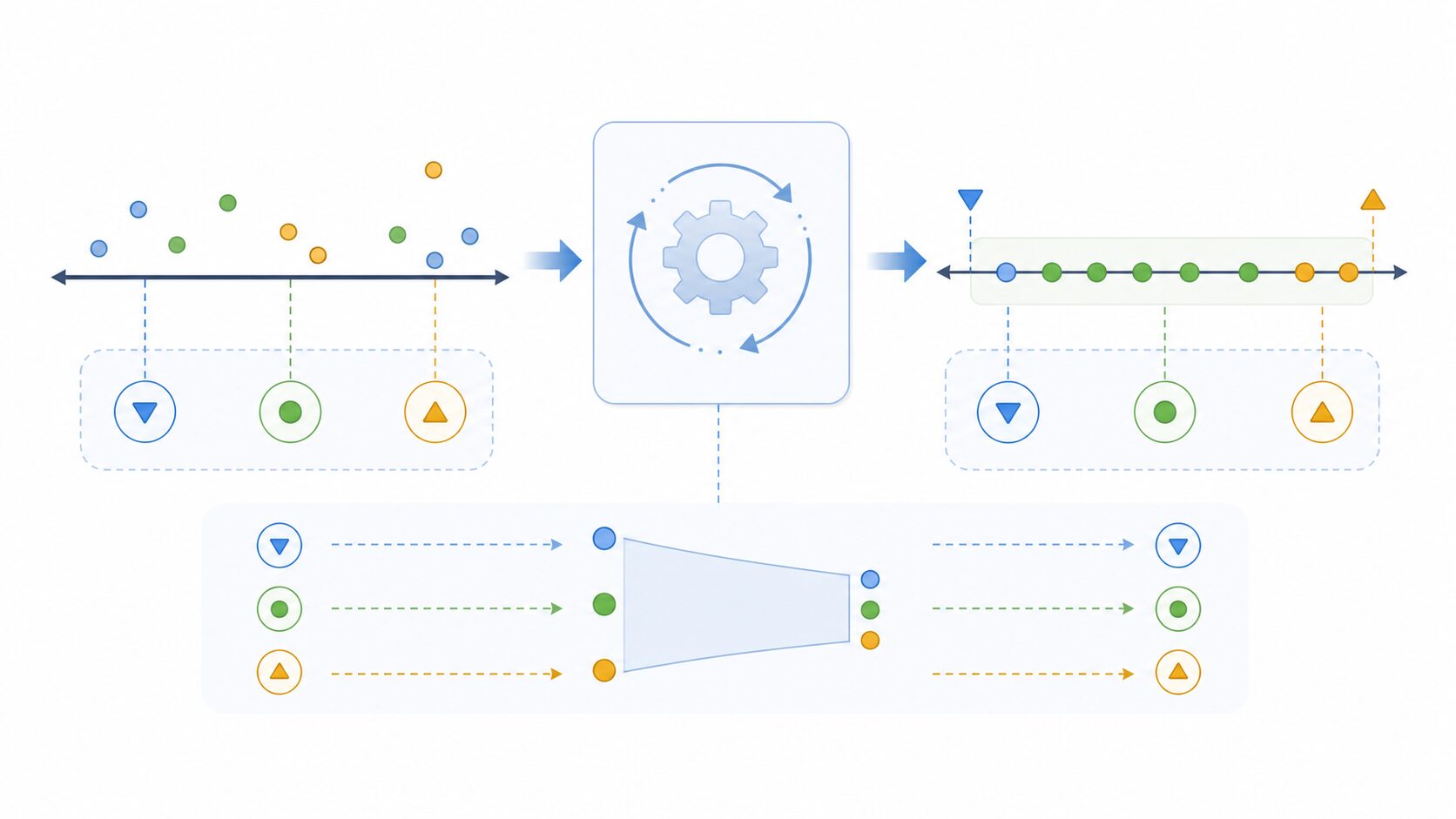
0から1へ変換する正規化では、まずデータ全体の最小値と最大値を確認します。そのうえで、各データから最小値を引き、最大値と最小値の差で割ります。
\(x’ = \frac{x – x_{min}}{x_{max} – x_{min}}\)ここで、\(x\) は元の値、\(x’\) は正規化後の値、\(x_{min}\) はデータの最小値、\(x_{max}\) はデータの最大値です。分母の \(x_{max} – x_{min}\) はデータの範囲を表します。
例として、テストの点数が20点から100点の範囲にあり、ある人の点数が60点だったとします。この場合、正規化後の値は次のように計算できます。
\(\frac{60 – 20}{100 – 20} = \frac{40}{80} = 0.5\)60点は、20点から100点までの範囲のちょうど中央にあるため、正規化後は0.5になります。20点は0、100点は1になり、80点なら0.75です。このように、正規化は複雑な統計処理ではなく、最小値からどれだけ離れているかを、全体の幅に対する割合として表す処理です。
実務では、学習データで求めた最小値と最大値を保存し、予測時の新しいデータにも同じ値を使って変換します。予測するたびに新しいデータだけで最小値と最大値を取り直すと、学習時と異なる尺度になり、モデルの入力条件がずれてしまうためです。
| 手順 | 内容 |
|---|---|
| 1 | 対象データの最小値と最大値を確認する |
| 2 | 各値から最小値を引く |
| 3 | 最大値と最小値の差で割る |
| 4 | 0から1の範囲に収まっているか確認する |
正規化と標準化の違い
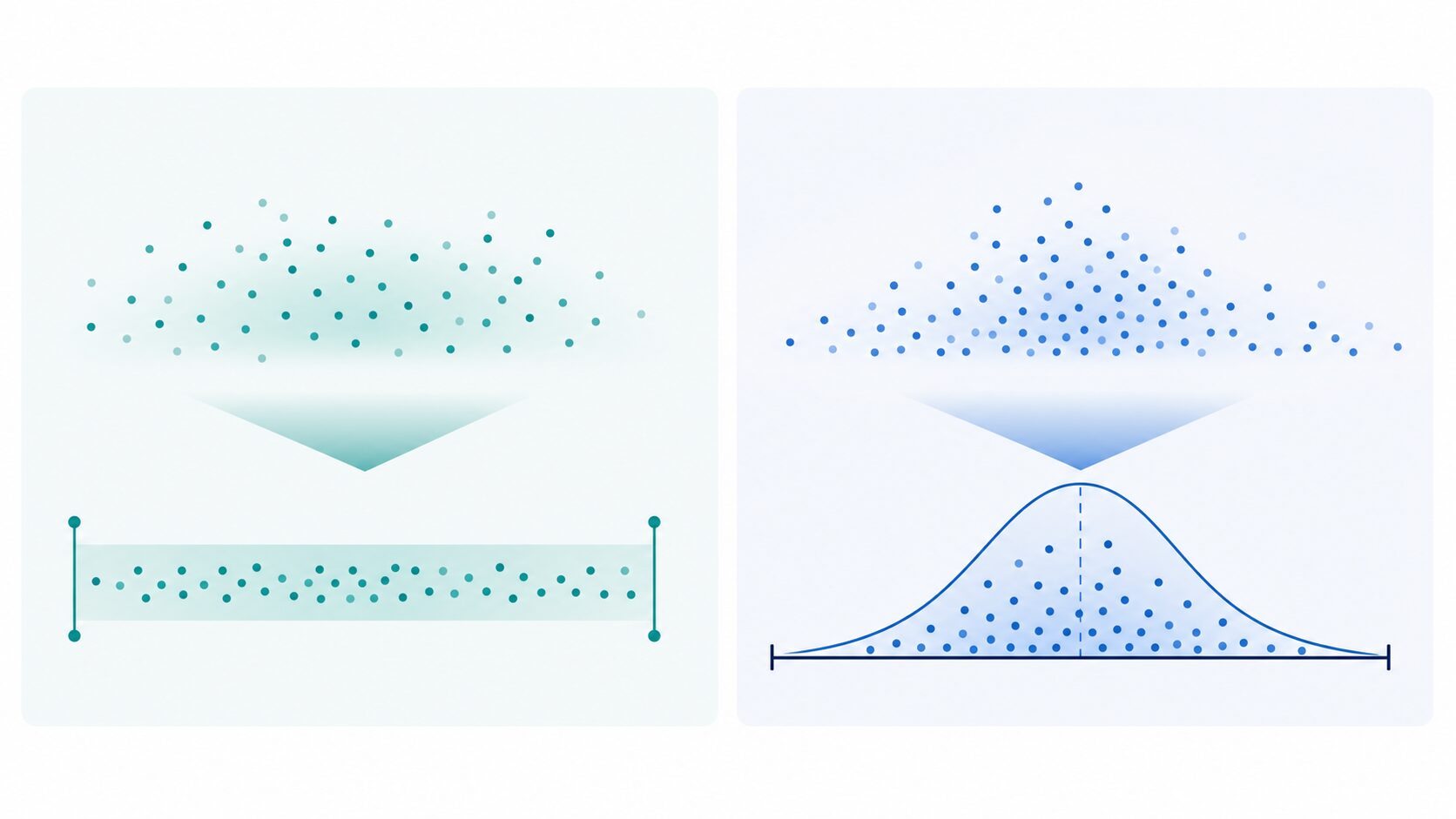
正規化とよく混同される手法に、標準化があります。どちらもデータの尺度を整える前処理ですが、変換後の意味が異なります。
正規化は、最小値と最大値を使って値を0から1などの決まった範囲に収めます。一方、標準化は、平均を0、標準偏差を1にそろえます。標準化の代表的な式は次の通りです。
\(z = \frac{x – \mu}{\sigma}\)ここで、\(x\) は元の値、\(\mu\) は平均、\(\sigma\) は標準偏差、\(z\) は標準化後の値です。正規化のように0から1へ必ず収まるわけではなく、平均より小さい値は負の値、平均より大きい値は正の値になります。
使い分けの大きなポイントは外れ値です。正規化は最小値と最大値に強く依存するため、極端な値が1つあるだけで、他の多くの値が狭い範囲に押し込められます。標準化も外れ値の影響をまったく受けないわけではありませんが、平均と標準偏差を基準にするため、0から1の範囲が必要ない分析では候補になりやすい手法です。
| 項目 | 正規化 | 標準化 |
|---|---|---|
| 基準 | 最小値と最大値 | 平均と標準偏差 |
| 変換後 | 多くの場合0から1 | 平均0、標準偏差1 |
| 外れ値の影響 | 受けやすい | 正規化より目立ちにくい場合がある |
| 向いている場面 | 値を決まった範囲に収めたい場合 | 分布の中心とばらつきをそろえたい場合 |
画像のピクセル値を0から1へ変換したい場合は正規化が分かりやすい選択です。一方、線形モデルや距離にもとづく手法で特徴量の中心とばらつきをそろえたい場合は、標準化が適していることがあります。どちらが常に優れているというより、データの性質とモデルの前提に合わせて選ぶことが重要です。
正規化が使われる場面
正規化は、機械学習の前処理でよく使われます。特徴量ごとの範囲がそろっていないと、モデルが本来の意味ではなく数値の桁の違いに反応してしまうことがあるためです。
画像認識では、ピクセル値が0から255の範囲で表されることが多くあります。この値を255で割ると、0から1の範囲に変換できます。入力の範囲がそろうことで、ニューラルネットワークの学習が安定しやすくなります。
表形式データでも、正規化は役立ちます。住宅価格の予測で、面積、築年数、駅からの距離、価格帯のような特徴量を扱う場合、それぞれの単位や範囲は大きく異なります。特に距離にもとづいて近さを計算する手法では、範囲の大きい特徴量が結果に強く影響しやすいため、正規化や標準化を検討します。
自然言語処理でも、単語の出現回数を文書の長さで割るなど、値を比較しやすくする考え方が使われます。単純な出現回数だけでは、長い文書ほど数が大きくなりやすいため、文書全体の長さを考慮した調整が必要になるからです。
| 分野 | 対象 | 正規化の例 |
|---|---|---|
| 画像認識 | ピクセル値 | 0から255を0から1へ変換する |
| 表形式データ | 年齢、価格、面積、距離 | 特徴量ごとの範囲をそろえる |
| 自然言語処理 | 単語の出現回数 | 文書の長さを考慮して割合に直す |
| 時系列分析 | 株価、センサー値 | 銘柄や機器ごとのスケール差を調整する |
正規化を使うときの注意点
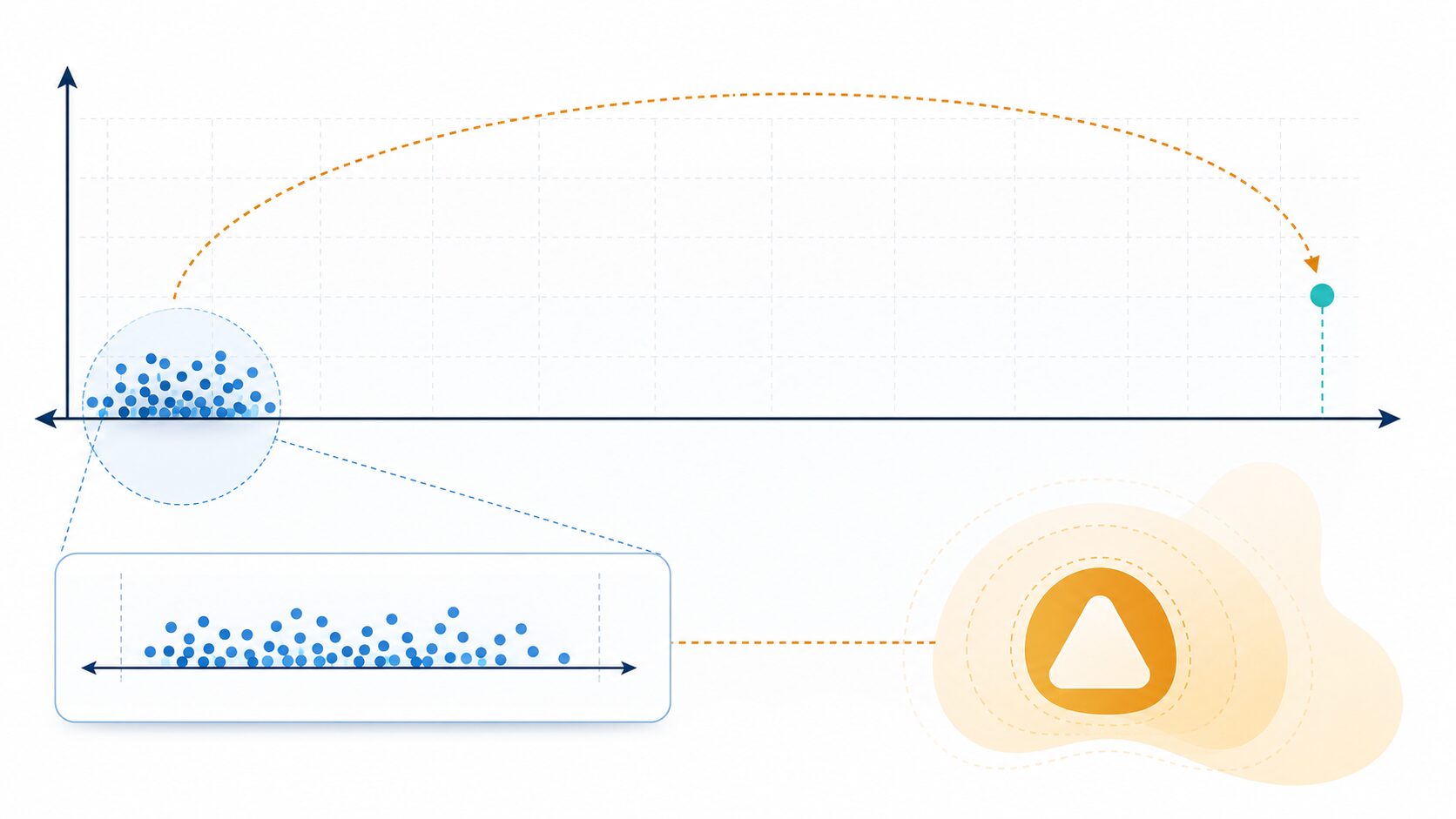
正規化は便利ですが、何でも0から1へ変換すればよいわけではありません。特に注意したいのは、外れ値の影響を受けやすい点です。
たとえば、ほとんどの値が0から10の範囲にあるデータに、100という極端に大きな値が1つだけ含まれていたとします。この状態で正規化すると、100が最大値として1に対応します。その結果、0から10にあった多くの値は0から0.1付近に集まり、細かな違いが見えにくくなります。
外れ値がある場合は、正規化の前にデータを確認し、外れ値を除外する、上限値で丸める、標準化やロバストな変換を使う、といった判断が必要です。外れ値が本当に誤入力なのか、それとも重要な異常のサインなのかによって、取るべき対応は変わります。
もう1つの注意点は、元の単位が見えにくくなることです。正規化後の0.7という値だけを見ても、それが70cmなのか700万円なのかは分かりません。分析結果を説明するときは、元の単位や変換前の範囲も一緒に管理しておく必要があります。
また、学習データとテストデータを分ける場合は、テストデータの情報を使って最小値や最大値を決めないようにします。将来のデータを先に見てしまうことになり、モデル評価が実際より良く見える可能性があるためです。
正規化を学ぶときの進め方
正規化を学ぶときは、まず式を暗記するよりも、最小値が0、最大値が1になる理由を確認すると理解しやすくなります。小さな表を用意し、最小値、中央に近い値、最大値をそれぞれ手計算してみると、変換の意味がつかめます。
次に、正規化と標準化を同じデータに適用して結果を比べてみましょう。正規化では範囲が0から1に収まり、標準化では平均を中心に負の値と正の値が出ます。この違いを見ると、どちらも「尺度を整える」処理でありながら、目的が異なることが分かります。
Pythonで試す場合は、配列の最小値と最大値を求めて式をそのまま実装するだけでも十分です。その後、機械学習ライブラリの前処理機能を使うと、学習データで求めた変換ルールを予測データへ同じように適用する流れも理解しやすくなります。
まとめ
データの正規化は、異なる範囲の数値を0から1などの共通スケールへそろえる前処理です。計算は、元の値から最小値を引き、最大値と最小値の差で割るだけなので、仕組み自体はシンプルです。
一方で、外れ値の影響、元の単位の扱い、学習時と予測時で同じ変換ルールを使うことなど、実際に使うときの注意点もあります。正規化と標準化の違いを押さえ、データの性質とモデルの目的に合わせて選ぶことが、AIやデータ分析の前処理では重要です。
更新履歴
| 日付 | 内容 |
|---|---|
| 2025年1月31日 | 初回公開 |
| 2026年5月24日 | 計算式、標準化との差、外れ値への対応を補強 |