赤池情報量基準:モデル選択の指標

AIの初心者
先生、「赤池情報量基準」って、結局どういうものなんですか?難しくてよくわからないです。

AI専門家
そうだね、難しいよね。簡単に言うと、統計モデルが良いか悪いかを判断するための点数みたいなものだよ。モデルがデータにどれだけ合っているかと、モデルがどれだけ複雑か、のバランスをみて点数をつけるんだ。
AIの初心者
データに合っているのは良いことだけど、複雑なのは良くないんですか?
AI専門家
複雑すぎると、今のデータにはすごく合っていても、新しいデータではうまくいかないことがあるんだ。これを「過学習」と言うんだけど、それを避けるために、複雑すぎないモデルが良いモデルとされているんだよ。AICは、このバランスをうまく考えてくれる便利な道具なんだ。
赤池情報量基準とは。
人工知能の分野でよく使われる「赤池情報量基準」について説明します。これは、統計モデルが良いか悪いかを判断するための指標です。
統計モデルを作る時、私たちは集めたデータにどれだけうまく合致するかを重視します。もちろん、データにぴったり合うモデルが良いモデルです。しかし、あまりにデータに合わせすぎると、そのデータ特有の癖まで覚えてしまい、新しいデータではうまく予測できないという問題が起こります。これを「過学習」と呼びます。過学習は、モデルが複雑になりすぎた時に起こりやすいです。
つまり、良いモデルを作るには、データへの合致度とモデルの複雑さのバランスを取ることが大切です。複雑すぎず、それでいてデータにもある程度合っているモデルが理想的です。このバランスをうまく捉えて、モデルの良し悪しを評価するのが「赤池情報量基準」です。
はじめに

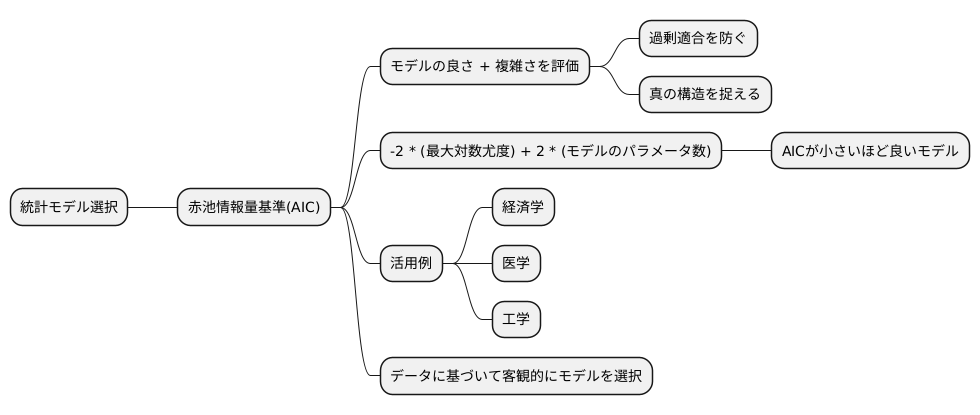
統計解析を行う上で、数ある統計モデルの中から最適なものを選ぶことは肝要です。適切なモデル選びは、データに潜む真の構造を明らかにする鍵となります。そこで登場するのが、赤池情報量基準(AIC)です。AICは、モデルの良さだけでなく、複雑さも加味して評価することで、データへの過剰な適合を防ぎ、より良いモデル選びを助けてくれます。
統計モデルとは、データの生成過程を数式で表現したものです。例えば、ある商品の売上高を予測したい場合、売上高に影響を与えるであろう広告費や気温などの変数を用いてモデルを構築します。しかし、変数を多くすればするほどモデルは複雑になり、手元のデータにぴったりと合うようになります。一見すると良いモデルのように思えますが、これは過学習と呼ばれる状態で、新しいデータに対しては予測精度が下がってしまう可能性があります。AICは、このような過学習を防ぐために、モデルの複雑さを罰則として加えることで、真の構造を捉えることに重点を置いたモデル選びを実現します。
AICは、-2 × (最大対数尤度) + 2 × (モデルのパラメータ数)で計算されます。最大対数尤度は、モデルが観測データにどれだけ適合しているかを示す指標で、値が大きいほど適合度が高いことを意味します。パラメータ数は、モデルの複雑さを表す指標で、値が大きいほどモデルは複雑になります。AICはこれらのバランスを取りながら、最適なモデル選びを支援します。AICが小さいほど良いモデルとされ、複数のモデルを比較する際は、AICが最も小さいモデルが最良のモデルとして選択されます。
AICは様々な分野で活用されています。例えば、経済学では、経済指標の予測モデルの選択に、医学では、病気の診断モデルの選択に、そして工学では、システム制御モデルの選択に用いられています。AICは、データに基づいて客観的にモデルを選択できる強力なツールであり、その活用は研究の信頼性を高める上で非常に重要です。
当てはまりと複雑さのバランス

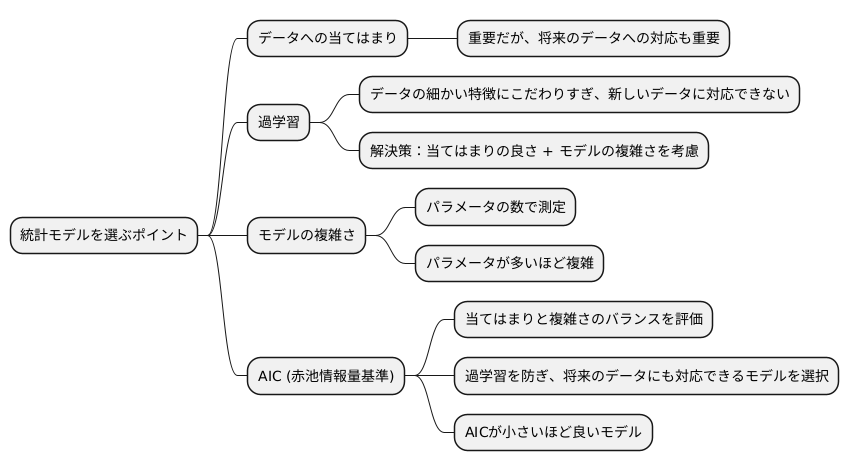
統計モデルを選ぶとき、データにうまく合うことは大切ですが、ただ合うだけでなく、将来のデータにも対応できるかが重要です。ぴったり合うモデルを作ることは簡単そうに思えますが、複雑すぎるモデルは、今のデータの細かい特徴にこだわりすぎて、新しいデータにはうまく対応できないことがあります。これは、まるで、特定の問題集の解答だけを暗記して、似たような問題が出ても応用できないようなものです。
この現象を過学習と呼びます。過学習は、モデルが複雑になりすぎ、観測されたデータの偶然のばらつきやノイズまで学習してしまうことで起こります。たとえば、ある商品の売上を予測するモデルで、過去の売上の細かい変動にまで合わせてモデルを作ってしまうと、将来の売上の変化をうまく捉えられない可能性があります。
そこで、当てはまりの良さだけでなく、モデルの複雑さも考慮する必要があります。モデルの複雑さは、モデルが持つパラメータの数などで測ることができます。パラメータが多いほど、モデルは複雑になります。
AIC(赤池情報量基準)は、この当てはまりと複雑さのバランスを評価する指標です。AICは、モデルがデータにどれだけ良く合うかを表す指標と、モデルの複雑さを表す指標を組み合わせることで、過学習を防ぎ、将来のデータにも対応できるモデルを選びやすくします。
AICが小さいほど、良いモデルとされます。AICを使うことで、現在手元にあるデータだけでなく、将来得られるであろうデータに対しても良い予測ができるモデルを選択することができます。これは、様々な状況で使える、応用力の高い知識を身につけることに似ています。AICは、統計モデルを選ぶ際に、より良い判断をするための有力な道具となります。
赤池情報量基準の計算方法

赤池情報量基準(AIC)は、統計モデルの良さを評価するための指標です。数式の理解が難しくても、基本的な考え方をつかめば、誰でもその意味を理解できます。
AICを計算するには、まず「最大対数尤度」を求めます。これは、観測されたデータが、ある統計モデルのもとでどれくらい起こりやすいかを表す指標です。この値が大きいほど、モデルはデータをよく説明できていると考えられます。しかし、複雑なモデルはデータへの当てはまりが良くなる傾向があります。たとえば、データの個数と同じだけのパラメータを持つモデルを考えれば、すべてのデータ点を完全に再現できます。しかし、このようなモデルは将来のデータに対する予測能力が低い、いわゆる過学習の状態にある可能性が高いです。
そこで、AICはモデルの複雑さを考慮するために、「パラメータ数」を罰則項として加えます。パラメータ数は、モデルが持つ調整可能な変数の数を指します。パラメータ数が多いほど、モデルは複雑になります。AICの計算式は、「−2×(最大対数尤度)+2×(パラメータ数)」となります。
AICは、モデルの当てはまりの良さ(最大対数尤度)と複雑さ(パラメータ数)のバランスを評価することで、最適なモデルを選択するための基準となります。AICの値が小さいほど、モデルは良いモデルと判断されます。複数のモデルを比較する場合、AICが最も小さいモデルが、データに最もよく適合し、かつ過剰に複雑でない、良いモデルであると考えられます。
| 項目 | 説明 |
|---|---|
| 赤池情報量基準(AIC) | 統計モデルの良さを評価するための指標。値が小さいほど良いモデル。 |
| 最大対数尤度 | 観測データがモデルでどれくらい起こりやすいかを表す指標。大きいほどデータをよく説明できている。 |
| パラメータ数 | モデルの複雑さを表す指標。モデルが持つ調整可能な変数の数。 |
| AICの計算式 | -2 × (最大対数尤度) + 2 × (パラメータ数) |
| AICの役割 | モデルの当てはまりの良さ(最大対数尤度)と複雑さ(パラメータ数)のバランスを評価し、最適なモデルを選択する。 |
赤池情報量基準の使い方

統計の世界では、データに合う数理モデルを作る事がよくあります。しかし、同じデータにも様々なモデルを当てはめる事ができ、どのモデルが最も適しているかを見極める必要があります。赤池情報量基準(AIC)は、様々なモデルの中から最適なモデルを選ぶための強力な道具です。
AICを使う場合、まず複数のモデルをデータに当てはめて、それぞれのモデルのAICを計算します。AICは、モデルの複雑さとデータへの当てはまりの良さを組み合わせて計算されます。AICが小さいほど、良いモデルと考えられます。例えば、3つのモデルを考え、それぞれのAICが100、105、110だったとします。この場合、AICが100のモデルが最も良いモデルと判断されます。
AICは、モデルの複雑さを適切に評価するところに特徴があります。複雑なモデルは、データに良く合うように見えますが、将来のデータにはうまく対応できない可能性があります。これは「過学習」と呼ばれる現象です。AICは、この過学習を避けるために、モデルの複雑さにペナルティを科しています。つまり、複雑すぎるモデルは、たとえデータに良く合っていたとしても、AICの値が大きくなるため、選ばれにくくなります。
注意点として、AICは相対的な指標であることを覚えておく必要があります。単一のモデルのAICだけを見て、そのモデルが良いか悪いかを判断することはできません。複数のモデルを比較することで、どのモデルが相対的に優れているかを判断することができます。また、AICはあくまでも一つの指標であり、モデル選択の唯一の基準ではないことも重要です。モデルの解釈のしやすさや、その分野の専門知識なども考慮に入れて、最終的なモデルを選択する必要があります。
| AICとは | 様々なモデルの中から最適なモデルを選ぶための強力な道具 |
|---|---|
| AICの使い方 | 複数のモデルに適用し、AICを計算。AICが小さいモデルが良いモデル。 |
| AICの評価基準 | モデルの複雑さとデータへの当てはまりの良さ。複雑すぎるモデルはAICが大きくなる。 |
| AICの注意点 | 相対的な指標であり、単一のモデルでは良し悪しは判断できない。モデル選択の唯一の基準ではない。 |
まとめ

様々な統計的な手法を用いてデータから規則性や構造を見つけ出す作業は、統計モデリングと呼ばれます。このモデリングにおいて、データに最もよく合うモデルを選ぶことは非常に重要です。しかし、ただ単にデータにぴったり合うモデルを選べば良いというわけではありません。あまりにデータに合わせすぎると、そのデータだけに特化したモデルになってしまい、新しいデータに対する予測精度が落ちてしまうことがあります。これは過学習と呼ばれる現象です。
この過学習を防ぎ、新しいデータに対しても高い予測精度を持つモデルを選ぶために用いられるのが、赤池情報量基準(AIC)です。AICは、モデルの当てはまりの良さだけでなく、モデルの複雑さも考慮に入れた指標です。モデルの複雑さとは、例えばモデルに含まれるパラメータの数などで表されます。
AICは、モデルの当てはまりの良さと複雑さのバランスを評価することで、過学習を防ぎ、一般化性能の高いモデルを選択することを可能にします。具体的には、AICは「-2 × (最大対数尤度) + 2 × (パラメータの数)」で計算されます。最大対数尤度は、モデルがデータにどれだけ適合しているかを示す指標で、値が大きいほど適合度が高いことを意味します。一方、パラメータの数はモデルの複雑さを表し、数が大きいほど複雑なモデルとなります。
複数のモデルを比較する場合、それぞれのモデルに対してAICを計算し、AICが最も小さいモデルを選びます。AICが小さいほど、そのモデルはデータに対する説明力が高く、かつ過学習のリスクが低いと判断できます。
AICは、様々な統計モデルに適用できるという利点があります。例えば、回帰分析、時系列分析、機械学習など、幅広い分野でAICは活用されています。適切なモデルを選択することで、より精度の高い分析を行い、データに基づいた意思決定を行うことができます。そのため、統計モデリングを行う際には、AICを有効に活用することが重要です。
| 用語 | 説明 |
|---|---|
| 統計モデリング | 様々な統計的な手法を用いてデータから規則性や構造を見つけ出す作業 |
| 過学習 | データに特化しすぎて、新しいデータに対する予測精度が落ちてしまう現象 |
| 赤池情報量基準(AIC) | モデルの当てはまりの良さと複雑さのバランスを評価する指標。過学習を防ぎ、一般化性能の高いモデルを選択するために用いられる。「-2 × (最大対数尤度) + 2 × (パラメータの数)」で計算される。 |
| 最大対数尤度 | モデルがデータにどれだけ適合しているかを示す指標。値が大きいほど適合度が高い。 |
| パラメータの数 | モデルの複雑さを表す指標。数が大きいほど複雑なモデルとなる。 |
| AICのモデル選択 | 複数のモデルの中からAICが最も小さいモデルを選ぶ。 |