直積量子化とは?ベクトル検索を軽くするProduct Quantizationの仕組み

AIの初心者
ベクトル検索の記事で「直積量子化」や「PQ」という言葉を見ました。普通の圧縮と何が違うのですか?

AI専門家
直積量子化は、高次元ベクトルをいくつかの小さな部分に分け、それぞれを代表パターンの番号で表す方法です。とくに大量の埋め込みベクトルを検索するとき、メモリを減らしながら近い候補を探すために使われます。
AIの初心者
つまり、元のベクトルを短くしても検索できるようにする技術ということですか?
AI専門家
その理解で大丈夫です。ただし完全に元通りに戻す圧縮ではなく、検索に必要な距離計算を近似するための表現です。この記事では、仕組み、IVF-PQとの関係、精度と速度の調整まで順番に見ていきます。
直積量子化とは。
直積量子化とは、高次元のベクトルを複数の部分ベクトルに分割し、それぞれを学習済みの代表ベクトルの番号へ置き換えることで、ベクトル検索に必要なメモリ量と計算量を減らす量子化手法です。英語では Product Quantization と呼ばれ、略して PQ と表記されます。
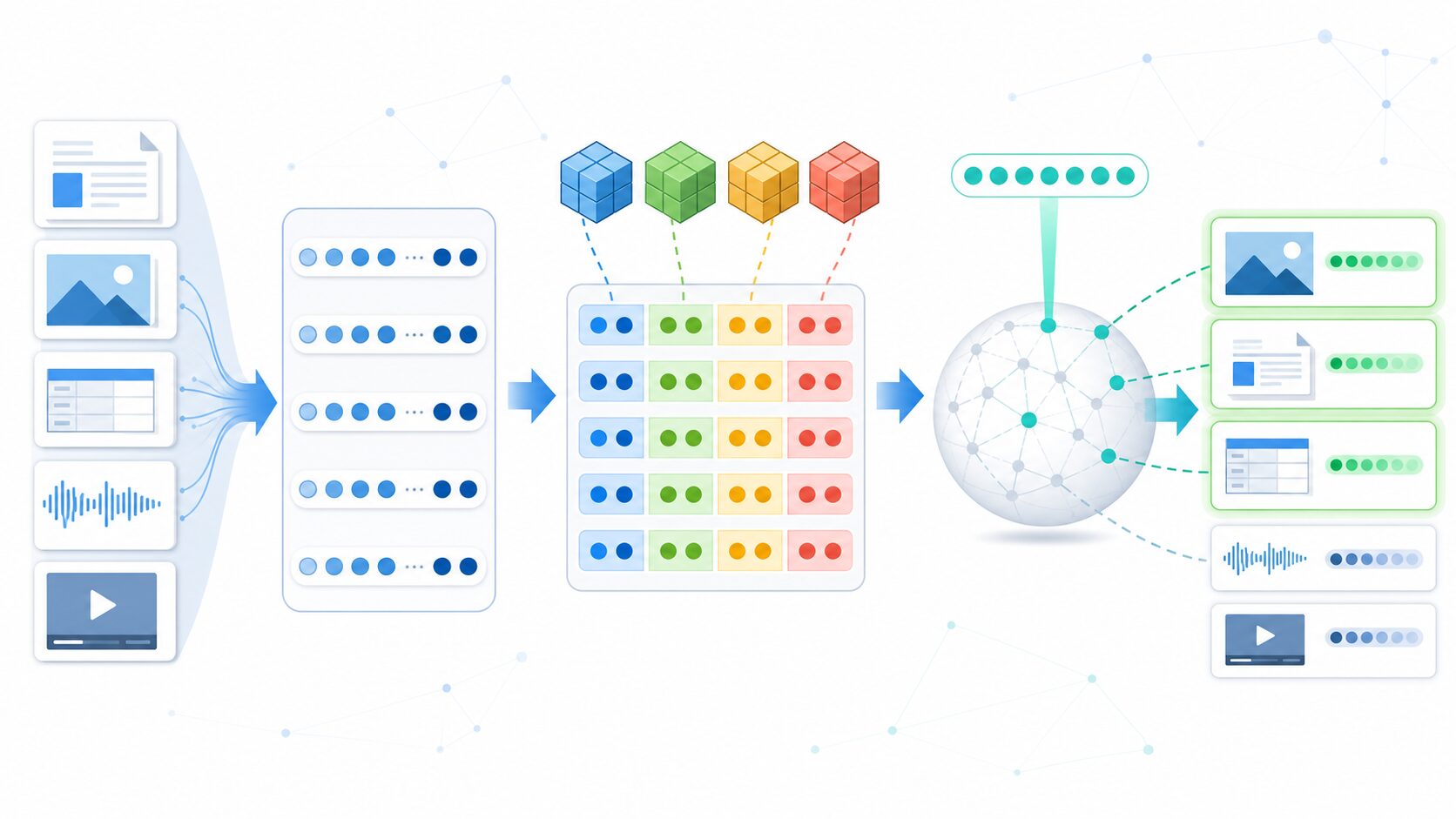
AIで扱う「埋め込み」は、文章、画像、音声、商品、ユーザー行動などを数百から数千次元の数値ベクトルとして表したものです。似ているもの同士はベクトル空間の中で近くに配置されるため、検索や推薦では「問い合わせベクトルに近いベクトルを探す」処理が重要になります。
しかし、データ数が増えるほど問題は単純ではなくなります。たとえば1000万件の文書を768次元のfloatベクトルで保存し、毎回すべてのベクトルと距離を計算する場合、保存容量も計算時間も大きくなります。そこで使われるのが、ベクトルを検索に使える形で小さく表すための技術です。直積量子化は、その代表的な方法のひとつです。
直積量子化が必要になる背景
ベクトル検索では、文書や画像をあらかじめ埋め込みベクトルに変換しておき、ユーザーの質問や検索語も同じ空間のベクトルへ変換します。そのうえで、コサイン類似度や内積、ユークリッド距離などを使って近いデータを探します。小さなデータセットなら全件比較でも十分ですが、実務では件数が数十万、数百万、数千万へ増えていきます。
このとき最初に重くなるのがメモリです。ベクトルの各次元を32bit浮動小数点数で保存すると、768次元のベクトル1本だけでも約3KBを使います。1000万件ならベクトルだけで数十GB規模になります。さらに検索時には、それらを高速に読み出し、距離計算を繰り返す必要があります。メモリに載らない、キャッシュ効率が悪い、距離計算が多すぎる、といった問題が検索速度に直結します。
もうひとつの背景は、検索結果に求められる性質です。ベクトル検索では、厳密に最も近い1件だけを数学的に証明したい場面より、十分に近い候補を短時間で取り出したい場面が多くあります。RAGで関連文書を上位数十件取り出す、画像検索で似た画像候補を並べる、推薦で近い商品候補を作る、といった用途では、検索の初段で近似を使い、その後で必要に応じて再ランキングする設計がよく採られます。
直積量子化は、このような場面で「保存を軽くし、距離計算を速くし、必要な近さを保つ」ために使われます。元のベクトルをそのまま全部持つ代わりに、短いコード列と代表ベクトルの表を持ち、検索時にはそのコードから距離を近似します。
基本の仕組み:ベクトルを分けて、それぞれを代表値に置き換える
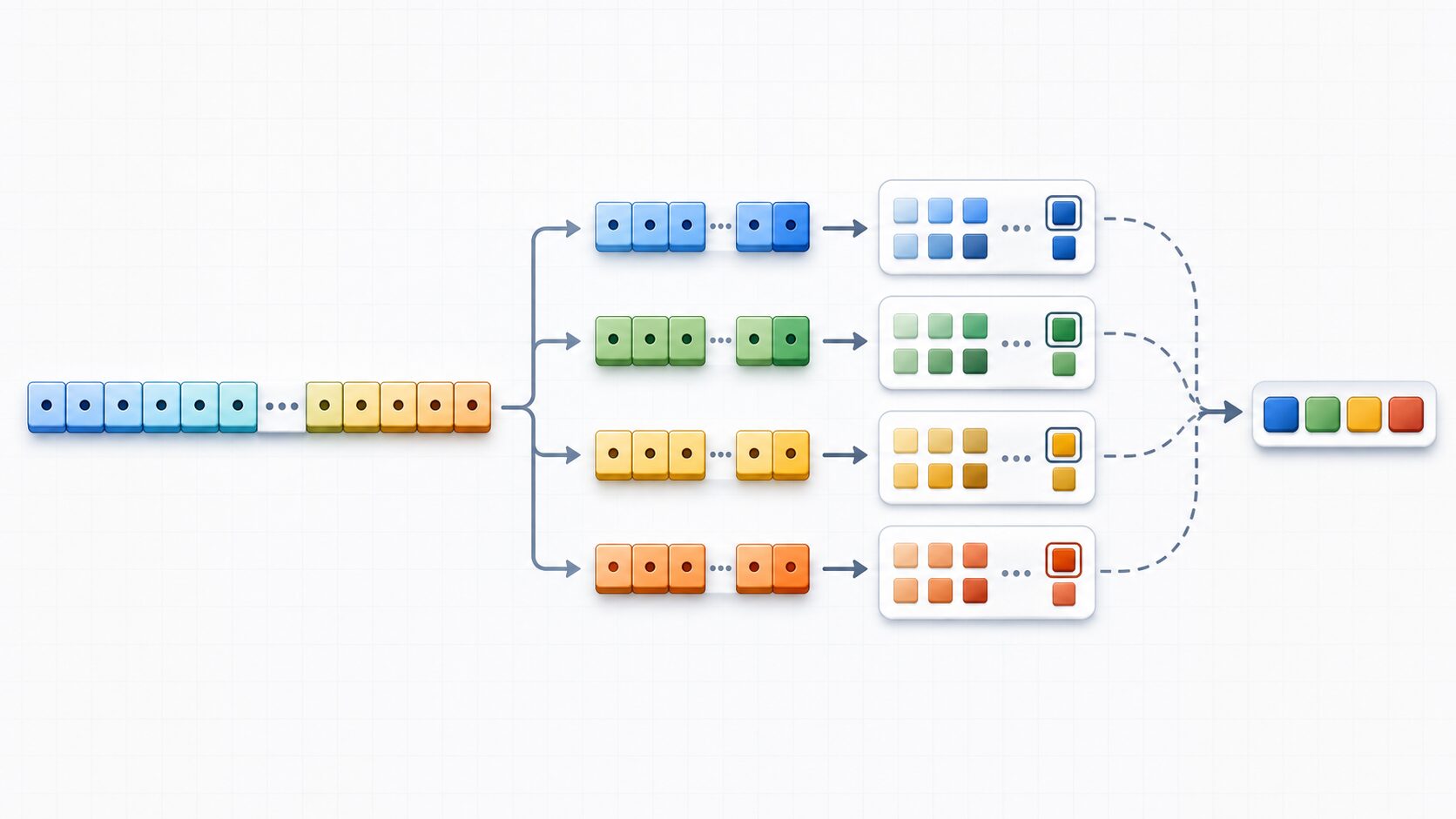
直積量子化の考え方は、名前だけ見ると難しく見えますが、流れは比較的シンプルです。高次元ベクトルをいくつかの同じ長さの部分ベクトルに分け、それぞれの部分空間ごとに代表ベクトルの一覧を作ります。そして、各部分ベクトルを最も近い代表ベクトルの番号で表します。
たとえば768次元の埋め込みベクトルを8分割すると、1つの部分ベクトルは96次元になります。それぞれの96次元空間について、学習データから256個の代表ベクトルを作っておくとします。あるデータの1番目の部分ベクトルが代表ベクトルの17番に近く、2番目が203番に近く、というように、各部分を番号で表せます。結果として、768個のfloat値の代わりに、8個の小さな番号を保存できます。
この代表ベクトルの一覧は、一般にコードブックと呼ばれます。データ本体には各部分がどの代表ベクトルに対応するかというコードだけを保存し、コードブックは検索システム全体で共有します。データごとに全次元の実数を持つより、共有された代表パターンと短い番号列を使ったほうが大幅に小さくなります。
ここで重要なのは、直積量子化が「ベクトル全体を一度にひとつの代表ベクトルへ置き換える」のではない点です。高次元空間全体を一括で量子化しようとすると、表現できるパターン数を増やすために非常に大きなコードブックが必要になります。直積量子化では、ベクトルを複数の部分空間に分け、各部分の代表値の組み合わせで全体を表します。そのため、比較的小さなコードブックでも多くの組み合わせを表現できます。
この「部分ごとの代表値の組み合わせ」が、Product Quantization の Product にあたる考え方です。各部分空間の選択肢を組み合わせることで、全体としては非常に多くの近似ベクトルを表現できます。初心者向けに言えば、洋服を丸ごと1種類の型で分類するのではなく、上着、ズボン、靴、バッグをそれぞれ代表パターンから選び、組み合わせで全体の特徴を表すようなものです。
検索時には距離をどう計算するのか
直積量子化で保存されたデータは、元のfloatベクトルそのものではありません。そのため、検索時には「問い合わせベクトル」と「圧縮されたデータ」の距離を近似的に求めます。代表的な方法では、問い合わせベクトルも同じように部分ベクトルへ分け、各部分についてコードブック内の代表ベクトルとの距離を先に計算して表にします。
たとえば8分割で、各部分に256個の代表ベクトルがある場合、検索クエリごとに8個の小さな距離表を作ります。データ側のコードが「1番目の部分は17番、2番目は203番」のように保存されていれば、検索時には距離表から該当する値を引き、部分ごとに足し合わせるだけで近似距離を求められます。元の768次元ベクトル同士を毎回すべて掛け算・足し算するより、処理が軽くなります。
この方式は、圧縮されたコードから元ベクトルを完全に復元してから距離を計算するのではありません。検索に必要な距離だけを、コードブックと短いコードを使って近似します。これにより、保存容量だけでなく、メモリアクセスや距離計算の負担も減らせます。
一方で、代表ベクトルに置き換える以上、元ベクトルとの差は必ず生じます。この差を量子化誤差と考えると分かりやすいでしょう。誤差が小さければ検索順位は元のベクトル検索に近くなりますが、誤差が大きいと本来近いはずの候補を取り逃がしたり、順位が入れ替わったりします。直積量子化を使うときは、速度だけでなく、検索品質とのバランスを見る必要があります。
IVF-PQとの関係
ベクトル検索の記事やライブラリ設定では、PQだけでなく「IVF-PQ」という表記を見かけることがあります。IVFは Inverted File Index の略で、ベクトル空間を粗くクラスタに分け、検索時に関係のありそうなクラスタだけを見る方法です。日本語では転置ファイルや転置インデックスと説明されることもありますが、一般的な全文検索の転置インデックスとは対象が異なり、ベクトル空間上の粗い分割を使う点が特徴です。
IVF-PQでは、まずIVFが検索範囲を絞ります。すべてのベクトルを比較するのではなく、問い合わせベクトルに近いクラスタをいくつか選び、そのクラスタ内のデータだけを候補にします。次に、その候補データをPQコードで比較し、近い順に並べます。つまり、IVFはどこを探すかを粗く決め、PQは候補内の距離計算と保存を軽くする役割を持ちます。
この組み合わせは、大規模なベクトル検索でよく使われます。IVFだけでも検索範囲は減りますが、クラスタ内のベクトルを元のfloatのまま保存するとメモリは大きくなります。PQだけでも保存は軽くなりますが、全データのコードを毎回見るなら件数が増えたときに重くなります。IVF-PQは、粗い候補選択と圧縮された距離計算を組み合わせることで、速度とメモリ効率を両方改善しようとする設計です。

ただし、IVF-PQにも調整項目があります。IVFのクラスタ数を増やすと、1クラスタあたりの候補数は減りやすくなりますが、適切なクラスタを選ぶ設定が重要になります。検索時に調べるクラスタ数を増やせば取り逃がしは減りますが、検索時間は増えます。PQの分割数やコードブックサイズを増やせば近似精度は上がりやすい一方で、保存容量や距離表の計算量が増えます。
実務では、IVF-PQを単独で完結させるより、上位候補をPQで高速に取り出し、その後に元ベクトルや別のスコアで再ランキングする構成もよく使われます。たとえばRAGでは、まずPQで関連しそうな文書を多めに取り出し、最終的に埋め込みの厳密な類似度、キーワード条件、更新日時、権限、LLMによる再評価などを組み合わせることがあります。
精度、メモリ、速度のトレードオフ
直積量子化の中心にあるのは、精度、メモリ、速度のトレードオフです。保存するコードを短くすればメモリは減りますが、表現できる情報は少なくなります。コードブックを細かくすれば近似精度は上がりやすくなりますが、学習や検索時の計算が重くなります。検索システムに求められる要件によって、最適な設定は変わります。
よく見る調整軸のひとつは、ベクトルをいくつに分割するかです。分割数を増やすと、各部分をより細かく組み合わせられるため、全体として表現力が上がる場合があります。一方で、コード長も増えます。もうひとつは、各部分空間の代表ベクトル数です。256個の代表を使えば1部分を8bitで表せますが、代表数を増やすとより細かく近似できる代わりに距離表や学習の負担が増えます。
データの分布も重要です。埋め込みベクトルが均一に広がっている場合と、特定の領域に偏っている場合では、同じコードブックでも誤差の出方が変わります。学習に使ったデータと本番データの分布が大きく違うと、代表ベクトルが本番データに合わず、検索品質が落ちる可能性があります。新しい種類の文書や画像が増えたときに、コードブックを再学習する必要があるかも検討します。
また、評価指標を決めずに「速くなった」「精度が落ちた」と判断するのは危険です。近似検索では、Recall@k、Precision@k、NDCG、クリック率、回答品質、レイテンシ、メモリ使用量など、用途に合う指標を見ます。RAGなら「正しい根拠文書が上位に入っているか」、画像検索なら「見た目が近い候補が上位にいるか」、推薦なら「ユーザーが反応する候補を出せているか」が重要になります。

関連する量子化手法との違い
直積量子化を理解するときは、似た用語との違いを整理すると混乱しにくくなります。量子化という言葉は、モデル軽量化、画像処理、音声処理、ベクトル検索など幅広い文脈で使われます。すべてに共通するのは、連続的または高精度な値を、より少ない種類の値や短い表現へ置き換えることです。ただし、目的と対象は文脈によって違います。
スカラー量子化は、各次元の数値を個別に低いbit幅へ変換する考え方です。たとえばfloat32をint8にするような変換です。これは分かりやすく実装しやすい一方、次元同士の関係をうまく使いにくい場合があります。直積量子化は、次元をまとまりとして扱い、各部分ベクトルを代表ベクトルに置き換えます。
ベクトル量子化は、ベクトル全体またはベクトルのまとまりを代表ベクトルへ置き換える広い考え方です。直積量子化はその一種と考えられます。ただし、高次元全体を一括で代表ベクトルに置き換えると、必要な代表数が膨大になりやすいため、PQでは部分空間に分割して組み合わせで表現します。
OPQは Optimized Product Quantization の略で、PQの前にベクトル空間を回転・変換して、分割後の量子化誤差が小さくなるようにする考え方です。元の次元の並びがPQの分割に合っていない場合、ただ機械的に前から分けるだけでは情報が偏ることがあります。OPQはその偏りを減らすための工夫です。
HNSWは、グラフ構造を使った近似最近傍探索の手法です。PQとは直接同じ分類ではありません。HNSWは探索経路を工夫して近い点へたどり着く方法であり、PQはベクトル表現を圧縮して距離計算を軽くする方法です。実装によっては、グラフ系の探索と量子化を組み合わせることもあります。
| 用語 | 主な目的 | 直積量子化との違い |
|---|---|---|
| スカラー量子化 | 各次元の値を低精度にする | 次元を個別に扱う。PQは部分ベクトル単位で代表ベクトルに置き換える。 |
| ベクトル量子化 | ベクトルを代表ベクトルへ近似する | PQはベクトル量子化を部分空間に分けて組み合わせる方法。 |
| OPQ | PQの誤差を減らす | PQの前処理として空間を変換し、分割しやすくする。 |
| IVF | 検索範囲を粗く絞る | IVFは候補領域を選ぶ。PQは候補の保存と距離計算を軽くする。 |
| HNSW | グラフ探索で近い点を探す | 探索構造の工夫。PQはベクトル表現の圧縮。 |
| LSH | ハッシュで近い候補を集める | 類似したベクトルが同じ箱に入りやすいようにする。PQは距離の近似計算に使う。 |
実務での使いどころ
直積量子化がよく使われるのは、データ数が多く、ベクトルをそのまま保存・比較するコストが大きい場面です。代表例はRAGの文書検索です。社内文書、FAQ、マニュアル、議事録、ナレッジベースなどを埋め込み化して検索する場合、件数が増えるほどメモリと検索時間が課題になります。PQを使えば、初段検索のコストを下げやすくなります。
画像検索やマルチモーダル検索でも有効です。画像埋め込みは高次元になりやすく、商品画像、写真、動画フレームなどを大量に扱うと保存容量が急増します。見た目が近い候補をまず広めに取り出し、その後で画像特徴やメタデータで絞る設計では、PQによる近似検索が役立ちます。
レコメンドでも似た考え方が使えます。ユーザーやアイテムをベクトルで表し、近いアイテムやユーザー群を探索する場合、候補生成の段階では高速性が重要です。最終的な順位は別のランキングモデルで決めるとしても、候補を作る段階で取りこぼしが多いと後段では回復できません。PQを使う場合も、候補数を多めに取り、再ランキングで品質を補う設計がよく検討されます。
ただし、すべてのシステムにPQが必要なわけではありません。データ件数が少ない、検索頻度が低い、メモリに余裕がある、厳密な順位が非常に重要、といった場合は、元ベクトルをそのまま使うほうが単純で扱いやすいこともあります。システムを複雑にする前に、まずはデータ量、レイテンシ要件、検索品質、運用負荷を確認することが大切です。

初心者が誤解しやすいポイント
直積量子化で最も誤解されやすいのは、「圧縮しても元のベクトルと同じ検索結果になる」と考えてしまうことです。PQは近似です。多くの場合、十分に近い結果を高速に得るための技術であり、完全一致の代替ではありません。とくに上位数件の順位が重要な場合や、非常に似た候補同士を厳密に区別したい場合は、再ランキングや元ベクトルの保持を検討します。
次に、分割数やコードブックサイズを大きくすれば必ず良くなる、という誤解があります。たしかに表現力は上がりやすくなりますが、メモリ、計算量、学習時間、実装の複雑さも増えます。検索の目的が「上位100件に正しい候補が入ればよい」のか、「上位3件の順序が重要」なのかで、必要な設定は変わります。
また、PQの学習データにも注意が必要です。コードブックはデータ分布から作られるため、学習に使うベクトルが偏っていると、本番検索でうまく近似できない領域が出る可能性があります。新しいカテゴリの文書が増えた、埋め込みモデルを変更した、データの言語や形式が大きく変わった、といったタイミングでは、既存のコードブックが適切かを再評価します。
最後に、ベクトルデータベースや検索ライブラリの設定名だけを暗記しないことも大切です。`m`、`nbits`、`nlist`、`nprobe` のようなパラメータは実装ごとに名前や意味が少しずつ異なる場合があります。値を変えると何が起こるのか、メモリ、速度、Recallにどう影響するのかを、小さな検証データで確認してから本番設定へ反映すると安全です。
パラメータを見るときの考え方
PQ関連の設定では、まず「ベクトルを何個の部分に分けるか」を確認します。この値はサブベクトル数、または実装によっては `m` と呼ばれます。ベクトル次元数がこの値で割り切れる必要がある場合もあります。たとえば768次元を8分割すれば1部分は96次元、16分割すれば1部分は48次元です。分割数が変わると、1データあたりのコード長と表現の細かさが変わります。
次に、各部分で何種類の代表ベクトルを使うかを見ます。256種類なら、1部分を8bitの番号で表せます。これが `nbits` のような設定として出てくることがあります。代表数を増やすと細かく近似できますが、距離表やコードブックのサイズも増えます。初学者は、圧縮率だけでなく、検索時にどのくらいの候補をどの品質で返したいのかを先に決めると設定を理解しやすくなります。
IVFと組み合わせる場合は、クラスタ数と検索時に調べるクラスタ数も重要です。クラスタ数が多すぎると学習や管理が難しくなり、少なすぎると1クラスタ内の候補が多くなります。検索時に調べるクラスタ数を増やすとRecallは上がりやすい一方、速度は落ちます。このような設定は、単独で最適値が決まるのではなく、データ件数、ベクトル次元、クエリ頻度、許容レイテンシ、必要なRecallによって決まります。
本番導入前には、元ベクトルによる厳密検索を基準として、PQやIVF-PQの結果がどの程度一致するかを測ると判断しやすくなります。たとえば、厳密検索の上位10件のうち、近似検索の上位10件に何件含まれるかを見る方法があります。数値だけでなく、実際の検索結果を人が見て妥当性を確認することも重要です。
まとめ
直積量子化は、高次元ベクトルを複数の部分ベクトルに分け、それぞれを代表ベクトルの番号で表すことで、大量のベクトルを軽く扱うための技術です。Product Quantization、またはPQと呼ばれ、ベクトル検索、近似最近傍探索、ベクトルデータベース、RAG、画像検索、推薦などで重要になります。
ポイントは、PQが単なるファイル圧縮ではなく、検索時の距離計算を近似するための表現だということです。メモリ使用量を減らし、検索を速くできる一方で、量子化誤差によって検索順位が変わる可能性があります。そのため、分割数、コードブックサイズ、IVFとの組み合わせ、再ランキング、評価指標をセットで考える必要があります。
初心者は、まず「長いベクトルを部分に分け、各部分を代表パターンの番号に置き換える」と理解すると十分です。そのうえで、なぜベクトル検索でメモリと速度が問題になるのか、IVF-PQではIVFとPQがどう役割分担するのか、精度と効率をどの指標で評価するのかを押さえると、実務の設定値や技術記事を読みやすくなります。
更新履歴
| 日付 | 内容 |
|---|---|
| 2026年5月16日 | 初回公開 |