
Leaky ReLU関数:活性化関数の進化

AIの初心者
「なめらかでないReLU関数」っていうのがよくわからないんですが…

AI専門家
「なめらかでないReLU関数」は、一般に「Leaky ReLU関数」や「漏れのあるReLU関数」と呼ばれる、ReLU関数の改良版です。ReLU関数は、入力が0より大きいときはその値をそのまま出力し、0以下のときは0を出力します。計算が簡単で学習を進めやすい一方、0以下の入力では勾配が0になり、学習が止まりやすい場合があります。そこで、その弱点を補うためにLeaky ReLU関数が使われます。
AIの初心者
なるほど。ReLU関数の改良版なんですね。具体的にはどのように違うのですか?
AI専門家
Leaky ReLU関数は、入力が0以下のときも小さな傾きを残します。例えば、負の入力に0.01を掛けた値を出力するようにすれば、入力がマイナスでも勾配が完全には0になりません。そのため、ReLUで起きやすい学習の停滞を抑えやすくなります。
Leaky ReLU関数とは。
Leaky ReLU関数は、ニューラルネットワークで使われる活性化関数の一種です。基本形であるReLU関数のシンプルさを保ちながら、負の入力でもわずかに反応するようにした点が特徴です。特に、ReLUの弱点であるdying ReLU問題を抑えるための改良として理解すると分かりやすいでしょう。
活性化関数とは
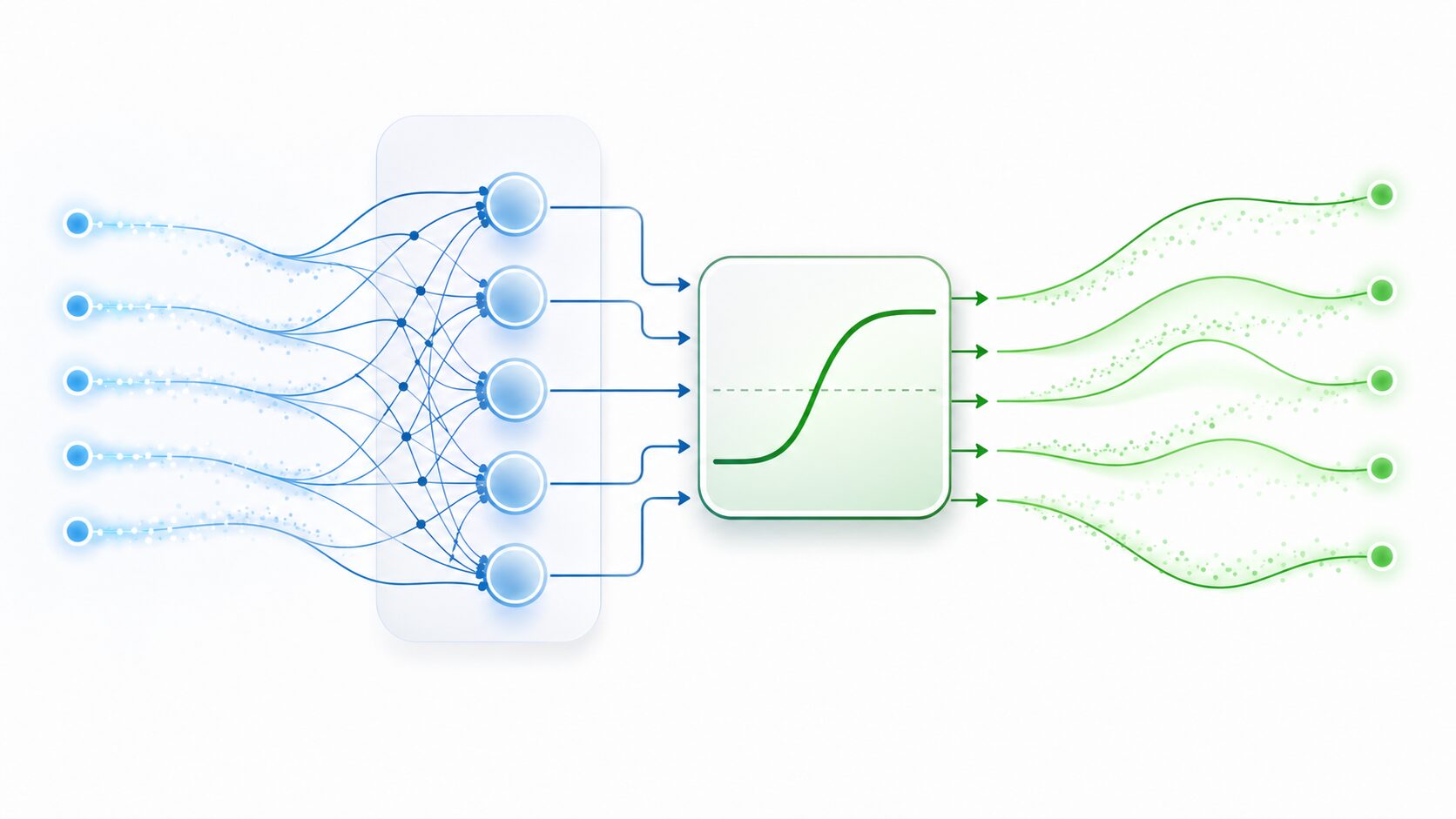
活性化関数とは、ニューラルネットワークの各層で計算された値を変換し、次の層へ渡すための関数です。人間の神経細胞が一定以上の刺激に反応するように、人工ニューラルネットワークでも入力に対してどのような出力を返すかを決めます。
もし活性化関数がなければ、層を何段重ねても全体としては単純な一次関数に近い働きしかできません。活性化関数を入れることで、モデルは直線では表しにくい関係を扱えるようになります。つまり、活性化関数はニューラルネットワークに非線形性を与える重要な部品です。
代表的な活性化関数には、シグモイド関数、tanh関数、ReLU関数などがあります。現在の深層学習では、計算が軽く扱いやすいReLU系の関数がよく使われます。ただし、どの関数が最適かは、データの性質やモデルの目的によって変わります。
ReLU関数の登場と課題
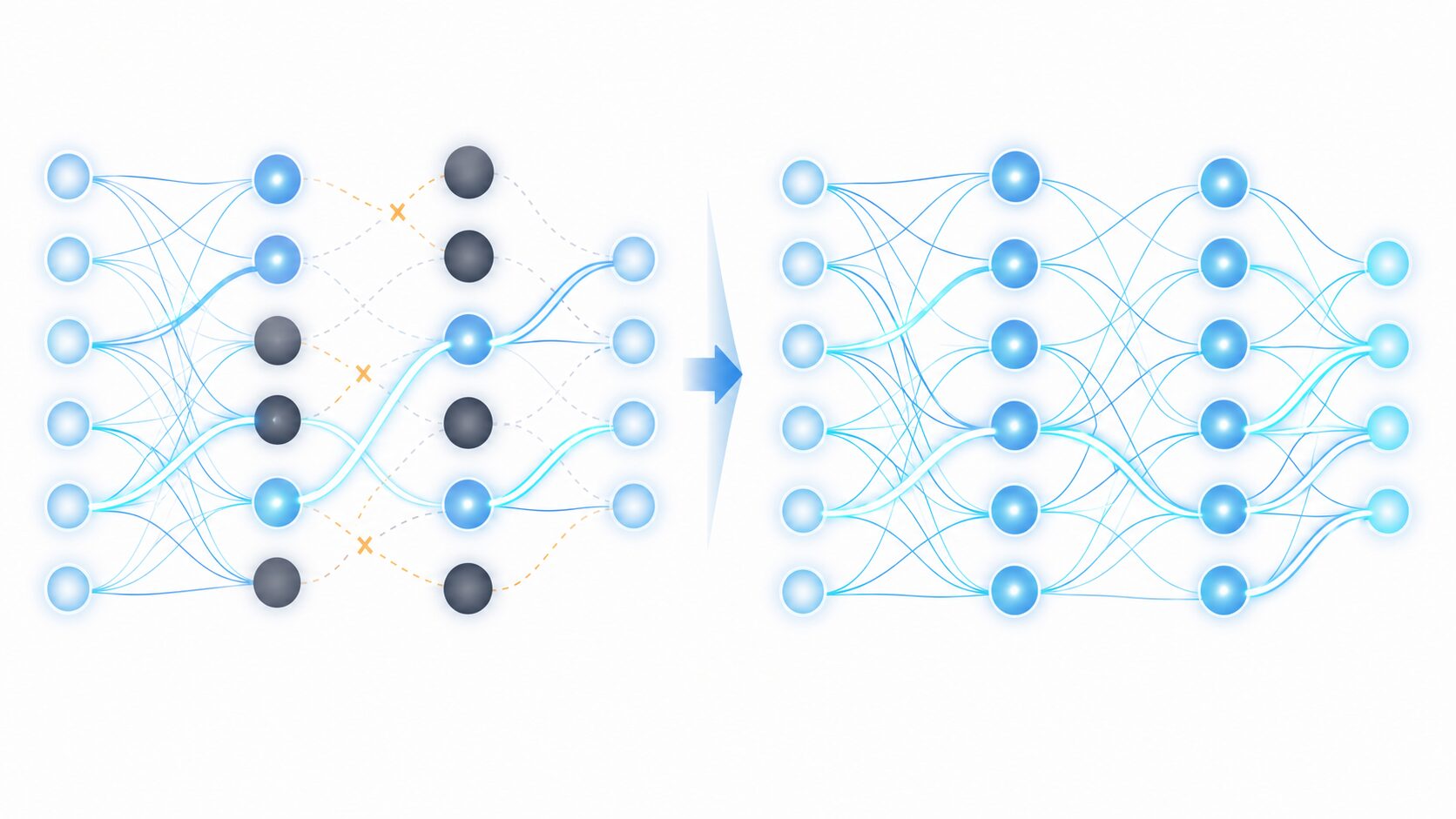
ReLU関数は「Rectified Linear Unit」の略で、日本語では修正線形ユニットとも呼ばれます。入力が正の値ならそのまま出力し、0以下なら0を出力する、とても単純な関数です。
ReLUが広く使われる理由は、計算が簡単で学習速度を上げやすいことです。また、シグモイド関数やtanh関数で起こりやすい勾配消失問題を、正の入力領域ではある程度避けられます。正の入力では勾配が一定なので、深いネットワークでも学習信号が伝わりやすくなります。
一方で、ReLUには大きな弱点もあります。入力が負になると出力が常に0になり、勾配も0になります。この状態が続くと、そのニューロンの重みが更新されにくくなり、事実上働かなくなることがあります。これがdying ReLU問題です。
Leaky ReLU関数は、このdying ReLU問題を軽減するために考えられたReLUの改良版です。負の入力でも勾配を完全には消さないため、学習の流れを保ちやすくなります。
| 活性化関数 | 特徴 | 利点 | 注意点 |
|---|---|---|---|
| ReLU | 正の入力はそのまま、負の入力は0にする | 計算が軽く、正の領域で勾配が伝わりやすい | dying ReLU問題が起こることがある |
| シグモイド関数・tanh関数 | 出力を一定範囲に収める | 確率や符号付き値の表現に使いやすい場合がある | 入力が大きいと勾配が小さくなりやすい |
| Leaky ReLU・PReLU | ReLUの負の領域を改良する | dying ReLU問題を軽減しやすい | 負の傾きの設定や学習方法を考える必要がある |
Leaky ReLU関数の仕組み

Leaky ReLU関数の基本的な考え方は、ReLUの負の領域に小さな傾きを持たせることです。ReLUでは、入力が0以下になると出力は0に固定されます。これに対してLeaky ReLUでは、負の入力に小さな係数を掛けた値を出力します。
例えば、係数を0.01とすると、入力が-1のときの出力は-0.01になります。入力が-10なら出力は-0.1です。値としては小さいものの、完全な0ではないため、学習時の勾配も残ります。
この「少しだけ漏らす」ような動きが、Leaky ReLUという名前の由来です。重要なのは、負の入力を大きく扱うことではありません。負の領域でも学習信号を完全に途切れさせないことが目的です。
| 関数 | 入力が正の場合 | 入力が負の場合 | 勾配の考え方 |
|---|---|---|---|
| ReLU | そのまま出力 | 0を出力 | 正の領域は1、負の領域は0 |
| Leaky ReLU | そのまま出力 | 小さな係数を掛けて出力 | 正の領域は1、負の領域も小さな値を保つ |
Leaky ReLU関数の利点

Leaky ReLU関数の最大の利点は、ReLUの計算の軽さをほぼ保ちながら、dying ReLU問題を起こりにくくできることです。負の入力でも勾配が残るため、ニューロンが完全に沈黙しにくくなります。
また、計算式が単純な点も実用上の強みです。負の入力に小さな係数を掛ける処理が加わるだけなので、複雑な関数に比べて計算負荷は大きく増えません。そのため、大規模なニューラルネットワークでも使いやすい活性化関数です。
画像認識や自然言語処理などの深層学習では、層が深くなるほど学習の安定性が重要になります。Leaky ReLUは、すべての問題で必ずReLUより良いわけではありませんが、負の入力側の勾配を残したい場面では有力な選択肢になります。
| 項目 | Leaky ReLU関数 | ReLU関数 |
|---|---|---|
| 負の入力への対応 | 小さな傾きを残す | 0にする |
| dying ReLU問題 | 起こりにくくできる | 起こる場合がある |
| 計算量 | 軽い | 非常に軽い |
| 使いどころ | 学習の停滞を抑えたい場合 | まず試す基本的な活性化関数として使いやすい |
様々なReLU関数ファミリー

ReLUをもとにした活性化関数には、Leaky ReLU以外にもいくつかの改良版があります。いずれも、ReLUのシンプルさを活かしながら、負の入力側の扱いを工夫している点が共通しています。
代表的なものがPReLUです。PReLUは、Leaky ReLUの負の領域の傾きを固定値ではなく、学習可能なパラメータとして扱います。データに合わせて傾きを調整できるため、より柔軟な表現が可能になります。
RReLUは、学習中に負の領域の傾きをランダムに変える方法です。検証や推論では平均的な値を使います。ランダム性を入れることで、過学習を抑える効果が期待されます。
どの関数を選ぶべきかは、モデルの構造、データ量、タスク、計算資源によって変わります。まずReLUを基準にし、学習が不安定な場合やdying ReLUが疑われる場合に、Leaky ReLUや関連手法を検討すると整理しやすくなります。
| 関数 | 負の入力の扱い | 特徴 |
|---|---|---|
| ReLU | 0にする | 単純で計算が軽い |
| Leaky ReLU | 小さな固定係数を掛ける | dying ReLU問題を軽減しやすい |
| PReLU | 傾きを学習する | データに合わせて柔軟に調整できる |
| RReLU | 学習中に傾きをランダム化する | 過学習の抑制が期待できる |
今後の展望
活性化関数は、ニューラルネットワークの性能や学習の安定性に大きく関わる要素です。Leaky ReLU関数は、ReLUの弱点を補う代表的な改良として、深層学習の発展に貢献してきました。
今後も、より安定して学習できる関数や、特定のタスクに適した関数の研究は続いていくでしょう。画像認識、音声認識、自然言語処理など、AIが使われる領域が広がるほど、活性化関数の選び方も重要になります。
Leaky ReLUを理解することは、単に1つの関数を覚えることではありません。ReLUの長所と弱点、勾配の流れ、学習の安定性をまとめて理解する入口になります。活性化関数を比較しながら選べるようになることが、ニューラルネットワークを実践的に扱うための第一歩です。
更新履歴
| 日付 | 内容 |
|---|---|
| 2025年2月2日 | 初回公開 |
| 2026年4月28日 | Leaky ReLU関数の定義、ReLUとの違い、dying ReLU問題、ReLUファミリーとの比較を初心者向けに再構成 |