学習データのカットオフ:適切な活用で精度向上

AIの初心者
先生、「学習データのカットオフ」ってよく聞くんですけど、どういう意味ですか?

AI専門家
簡単に言うと、AIの学習に使うデータから、一部をわざと除外することだよ。例えるなら、料理で例えると、腐った野菜を取り除くようなものだね。
AIの初心者
なるほど。どうしてわざわざデータを捨てるんですか?
AI専門家
古い情報や間違った情報で学習すると、AIの精度が悪くなることがあるからだよ。例えば、昔流行った服を今売ろうとしても売れないのと同じで、AIも古い情報に惑わされないように、古いデータを捨てるんだ。他にも、特定の条件を満たすデータだけを使って学習させたい時にも使われるよ。
学習データのカットオフとは。
人工知能を育てるための情報の集まりから、ある一部分を取り除くことを「学習データの切り捨て」と言います。例えば、時間の流れに沿って変わるデータを使う場合、古すぎる情報ばかりを覚えてしまわないように、古いデータをある時点から切り捨てることがあります。他にも、特定の条件に合う情報だけを使って育てたい場合は、条件に合わない情報を切り捨てることがあります。
データのカットオフとは

機械学習の模型を作るには、たくさんの情報が必要です。しかし、良い模型を作るには、情報の量だけでは足りません。情報の質も大切です。そこで「学習情報の切り捨て」という考え方が出てきます。これは、ある基準に基づいて、学習に使う情報の一部をわざと除外する方法です。まるで彫刻家がノミでいらない石を削り落として作品の形を整えるように、情報の切り捨ては情報の集まりからいらない部分を取り除き、模型の学習に最適な情報の組み合わせを作り上げます。
具体的には、ある期間外の情報や、ある条件を満たさない情報などを除外します。たとえば、最新の流行を予測する模型を作る場合、数年前のデータは現在の状況を反映していないため、学習データから除外することが考えられます。あるいは、特定の地域における商品の売れ行きを予測する模型を作る際に、他の地域の情報はかえって予測の精度を下げてしまう可能性があるため、除外する必要があるかもしれません。このように情報の切り捨ては、模型が雑音や古い情報に惑わされることなく、本当に大切な情報に集中して学習できるようにするための大切な作業です。
情報の切り捨てによって、模型の正確さや信頼性を高めることができます。しかし、どのような情報を切り捨てるかは、目的に合わせて慎重に決める必要があります。切り捨てる基準を誤ると、重要な情報を失い、かえって模型の性能を低下させてしまう可能性があるからです。そのため、情報の切り捨てを行う際には、事前にデータの特性を十分に理解し、適切な基準を設定することが不可欠です。また、切り捨てた情報が本当に不要であったかを確認するために、切り捨て前と後の模型の性能を比較することも重要です。
時系列データへの適用

時間を追って記録されたデータ、いわゆる時系列データは、株価の動きや気温の変化のように、刻一刻と変化する様子を捉えています。このようなデータを使って機械学習モデルを訓練する際には、どの時点までのデータを使うか、つまりデータの切り捨てがとても重要になります。
過去のデータが古すぎると、現在の状況を正しく反映しておらず、モデルの予測精度が悪くなる可能性があります。例えば、10年前の株価データを使って今日の株価を予測するのは適切ではありません。市場の状況や経済環境は常に変化しているので、古いデータはむしろ邪魔になり、モデルの学習を妨げることさえあります。
適切な時期にデータを切り捨て、最近の傾向を反映したデータのみで学習させることが重要です。例えば、過去数ヶ月、あるいは数年のデータだけを使うなど、データの特性や予測したい期間に合わせて切り捨てる時期を調整する必要があります。
株価予測の場合、直近の経済指標や企業業績、世界情勢なども考慮に入れる必要があります。過去のデータだけを見ていても、予測精度は上がりません。また、気温予測であれば、季節性や異常気象なども考慮する必要があります。
データの切り捨て時期を適切に設定することで、より精度の高い予測が可能になります。適切な期間のデータを用いることで、モデルは現在の状況をより正確に学習し、将来の予測に役立つ情報を抽出することができます。さらに、データ量が適切になることで、計算時間の短縮にも繋がり、効率的なモデル構築が可能になります。常に変化する状況に合わせて、データの切り捨て時期を調整し続けることが、時系列データ分析においては非常に重要です。
| 時系列データの切り捨て | 重要性 |
|---|---|
| 過去のデータが古すぎる | 現在の状況を反映しておらず、予測精度が悪化、学習を妨げる可能性 |
| 適切な時期にデータを切り捨て、最近の傾向を反映したデータのみで学習 | 予測したい期間に合わせて切り捨てる時期を調整(数ヶ月、数年など) |
| 適切な切り捨て時期の設定 | 精度の高い予測、計算時間の短縮、効率的なモデル構築 |
特定条件による絞り込み

時系列ではない情報を取り扱う場合でも、情報の取捨選択は重要な作業です。不要な情報を除くことで、分析の精度を高めることができるからです。いくつか例を挙げて説明します。
例えば、ある地域の顧客の買い物行動を調べたいとします。この時、他の地域の顧客の情報は必要ありません。分析対象の地域以外の顧客情報を除外し、その地域の顧客情報のみを用いることで、より正確な分析結果が得られます。全国規模の顧客データから特定の地域のデータだけを抜き出す作業は、まるで不要な枝葉を取り除き、幹だけを残す剪定作業のようです。
また、ある商品の顧客評価を調べたい場合を考えてみましょう。この場合は、他の商品の評価は邪魔な情報となります。特定の商品に関する評価だけを抜き出し、それ以外の商品の評価は無視することで、分析の精度が上がります。膨大な商品評価の中から、目的の商品に関する評価だけを選び出す作業は、砂金を探す作業に似ています。多くの砂の中から、わずかな砂金を見つけ出すように、必要な情報だけを丁寧に選び出す必要があります。
このように、情報の取捨選択は、分析の目的に合わせて不要な情報を排除し、分析の効率と精度を高めるために欠かせません。まるで、料理で素材を厳選するように、分析でも必要な情報だけを選び出すことが重要です。不要な情報を取り除くことで、分析の目的がより明確になり、結果として質の高い分析結果を得ることができるのです。
| 例 | 目的 | 必要な情報 | 不要な情報 | 例え |
|---|---|---|---|---|
| 顧客の買い物行動調査 | 特定地域の顧客行動分析 | 対象地域の顧客情報 | 他地域の顧客情報 | 剪定 |
| 顧客評価調査 | 特定商品の顧客評価分析 | 対象商品の顧客評価 | 他商品の顧客評価 | 砂金探し |
カットオフの注意点

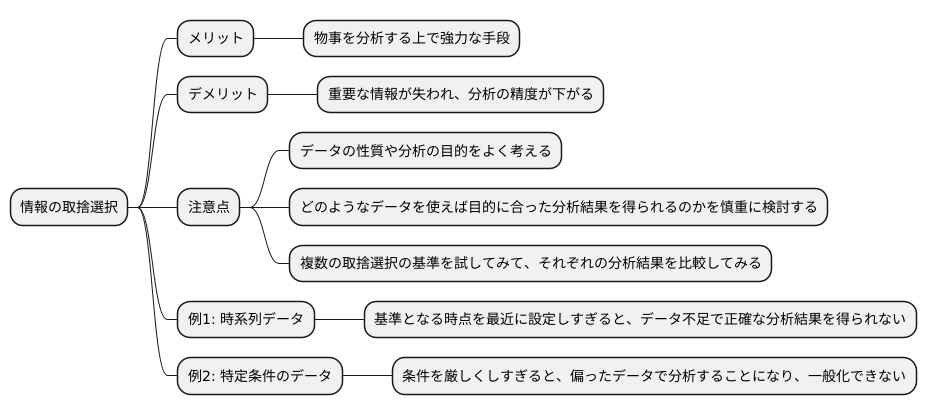
情報の取捨選択は、物事を分析する上で強力な手段となり得ます。しかし、その取捨選択を行う際の注意点もいくつか存在します。この取捨選択を適切に行わないと、重要な情報が失われ、結果的に分析の精度が下がる可能性があります。
例えば、時間の流れに沿って記録されたデータから、ある時点以降のデータだけを使う場合を考えてみましょう。この基準となる時点をあまりにも最近に設定してしまうと、分析に使えるデータが不足してしまうかもしれません。データが不足すると、そこから規則性や傾向を見つけることが難しくなり、正確な分析結果を得ることができなくなってしまうのです。
また、特定の条件を満たすデータだけを選んで分析する場合にも注意が必要です。条件を厳しくしすぎると、偏ったデータだけを使って分析を行うことになりかねません。例えば、特定の地域に住む人たちのデータだけを使って分析を行うと、その地域特有の傾向に合わせた分析結果になってしまいます。これは、他の地域にも当てはまる一般的な分析結果を得るためには不適切です。
このように、情報の取捨選択を行う際には、データの性質や分析の目的をよく考えることが大切です。闇雲にデータを絞り込むのではなく、どのようなデータを使えば目的に合った分析結果を得られるのかを慎重に検討する必要があります。そして、複数の取捨選択の基準を試してみて、それぞれの分析結果を比較してみるのも良いでしょう。そうすることで、最も適切な取捨選択の基準を見つけることができるはずです。
データの偏りへの対策

情報を扱う上で、データの偏りは結果の信頼性を大きく左右する問題です。データの一部だけを切り取って使う場合、切り取った部分に特有の傾向が強く出てしまうことがあります。例えば、ある商品の売れ行きを過去1年間のデータだけで調べたとします。たまたまその1年間が景気が良かった時期だったとしたら、本来よりも売れ行きが良く見えてしまうかもしれません。また、1年間を通して気温が平年より高かった場合、季節商品の売れ行き予測に大きな誤差が生じるでしょう。
このような偏りを防ぐためには、いくつかの方法があります。まず、データの切り取り方を変えてみて、結果がどう変わるかを確認することが大切です。例えば、先ほどの商品の売れ行きの場合、過去1年間だけでなく、過去3年間、過去5年間といった異なる期間で分析してみることで、より正確な傾向が見えてくる可能性があります。また、データ全体の様子をグラフなどで見て、偏りがないかを確認することも重要です。数値を眺めるだけでなく、視覚的に捉えることで、隠れた偏りに気づくことができる場合があります。
もし偏りが見つかった場合は、その偏りを修正する必要があります。例えば、ある地域の人々のデータだけが多く集まっている場合は、他の地域の人々のデータをもっと集めることで偏りを少なくできます。また、複数の異なる切り口で分析した結果を組み合わせて使う方法も有効です。1年間のデータ、3年間のデータ、5年間のデータでそれぞれ予測モデルを作り、それらの結果を組み合わせて最終的な予測とすることで、特定の期間の偏りの影響を抑えることができます。
データの偏りは、分析結果の信頼性を損なう大きな要因です。偏りが生じる原因を理解し、適切な対策を行うことで、より正確で信頼性の高い結果を得ることが可能になります。
| 問題点 | 対策 | 具体例 |
|---|---|---|
| データの偏りによって結果の信頼性が低下する | データの切り取り方を変えて結果の変化を確認する | 過去1年間だけでなく、過去3年間、過去5年間といった異なる期間で分析する |
| データ全体の様子をグラフなどで見て偏りがないかを確認する | 数値だけでなく視覚的に捉えることで隠れた偏りに気づく | |
| 偏りが見つかった場合は修正する | 特定の地域の人々のデータが多い場合は、他の地域の人々のデータをもっと集める | |
| 複数の異なる切り口で分析した結果を組み合わせて使う | 1年間、3年間、5年間のデータでそれぞれ予測モデルを作り、結果を組み合わせて最終予測とする |
今後の展望

機械学習の分野において、学習に用いる情報を適切に取捨選択することは、モデルの精度向上に欠かせません。この取捨選択を指す「情報の切り捨て」は、今後も重要な役割を担うと考えられます。特に、近年の情報量の爆発的な増加に伴い、学習に用いる情報を効率的に選ぶことの重要性はますます高まっています。情報の切り捨てを適切に行うことで、不要な情報に惑わされず、本当に重要な情報に基づいてモデルを学習させることができるため、精度の高いモデルを構築することが可能になります。
今後の研究においては、幾つかの重要な方向性が考えられます。まず、最適な切り捨ての基準を自動的に決定する計算手順の開発が挙げられます。現状では、経験に基づいた手作業での調整が必要となる場合が多く、自動化による効率化が期待されます。さらに、扱う情報の性質に合わせて切り捨ての基準を柔軟に調整する技術の研究も重要です。すべての情報に同じ基準を適用するのではなく、情報の特性に合わせた最適な基準を適用することで、より効果的な切り捨てが可能になります。
また、情報の切り捨てに伴う問題点への対策も重要な研究課題です。例えば、情報の切り捨てによって特定の傾向を持った情報が学習データから除外され、結果としてモデルに偏りが生じる可能性があります。このような偏りを自動的に見つけ出し、修正する技術の開発が求められます。具体的には、切り捨てられた情報も考慮した公平な評価指標を導入したり、切り捨ての基準自体に公平性を担保する仕組みを組み込むといったアプローチが考えられます。
これらの技術開発が進むことで、情報の切り捨てはより洗練された手法へと進化し、機械学習モデルの性能向上に大きく貢献していくと期待されます。より精度の高いモデルの構築は、様々な分野における課題解決や新たな価値の創造につながるため、今後の発展が期待されます。
| 情報の切り捨ての重要性 | 今後の研究方向性 | 問題点と対策 | 展望 |
|---|---|---|---|
| 機械学習モデルの精度向上に欠かせない。情報量の増加に伴い重要性が増している。不要な情報に惑わされず、重要な情報に基づいて学習させることで、精度の高いモデル構築が可能。 |
|
情報の切り捨てにより、特定の傾向を持った情報が除外され、モデルに偏りが生じる可能性。対策として、公平な評価指標の導入や、切り捨て基準に公平性を担保する仕組みの構築が必要。 | 情報の切り捨てはより洗練された手法へと進化し、機械学習モデルの性能向上に大きく貢献。様々な分野における課題解決や新たな価値の創造につながる。 |