ブートストラップサンプリングで精度向上

AIの初心者
先生、この『ブートストラップサンプリング』って、一部のデータだけで学習するのに、どうしてうまくいくのでしょうか?全部のデータを使った方が、良い結果になるんじゃないですか?

AI専門家
良い質問だね。確かに、全部のデータを使う方が情報量は多いように思えるよね。しかし、ブートストラップサンプリングを使うのには、いくつか理由があるんだ。一つは、一部のデータを使うことで、学習にかかる時間や計算資源を節約できること。もう一つは、色んな組み合わせのデータで学習することで、特定のデータに偏った学習をしてしまうことを防ぎ、より汎用的な学習ができるようになることなんだ。
AIの初心者
なるほど。特定のデータに偏らないようにするんですね。でも、一部のデータだけだと、そのデータにたまたま偏りがあったらどうするんですか?
AI専門家
その通り!そこで、何度もランダムにデータを取り出して、複数の決定木を作るんだ。それぞれの決定木は異なるデータセットで学習するので、一つ一つの決定木は偏りがあるかもしれない。しかし、たくさんの決定木を組み合わせることで、個々の偏りを打ち消し合って、最終的にはより正確で安定した結果が得られるんだよ。
ブートストラップサンプリングとは。
『人工知能』で使われる言葉、『復元抽出』について説明します。復元抽出とは、学習に全てのデータを使うのではなく、それぞれの決定木を作るために、一部のデータを繰り返し抜き出して学習させる方法のことです。
はじめに

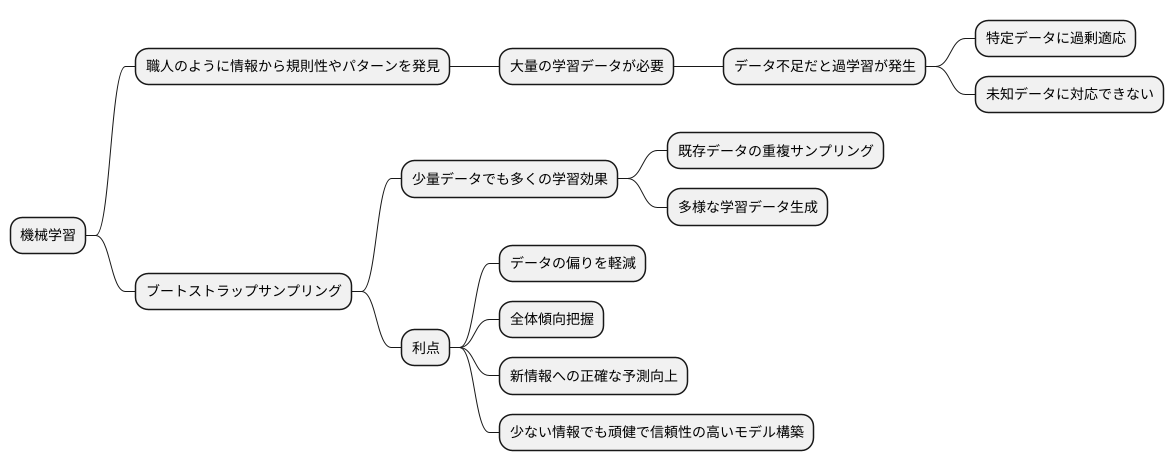
機械学習という技術は、まるで職人が経験から技術を磨くように、与えられた情報から規則性やパターンを見つけ出すことを得意としています。しかし、良い職人になるには豊富な経験が必要なように、機械学習でも大量の情報が必要です。もし経験が不足していたら、職人は特定の状況にしか対応できない、偏った技術しか持てないかもしれません。機械学習でも同じことが起こり、限られた情報だけで学習すると、特定のデータに過剰に適応し、未知の情報に対応できない、いわゆる「過学習」という状態に陥ってしまいます。
このような問題に対処するため、限られた情報をうまく活用する技術が求められています。その中で、「ブートストラップサンプリング」という手法は、少ない情報から多くの学びを得るための、まるで魔法のような技術と言えるでしょう。これは、元々持っている情報を何度も繰り返し活用することで、あたかも多くの情報を持っているかのような効果を生み出す方法です。具体的には、持っている情報の中から、重複を許してランダムに情報を抜き出し、新しい学習用のデータを作ります。これを何度も繰り返すことで、様々なバリエーションの学習データが作られます。
ブートストラップサンプリングを使う利点は、少ない情報でも、その情報に含まれる様々な特徴を捉え、偏りを減らすことができる点です。一部分だけの情報に囚われず、全体的な傾向を掴むことができるので、新しい情報に対しても、より正確な予測を行うことが可能になります。これは、職人が様々な経験を積むことで、どんな状況にも対応できるようになるのと似ています。
特に情報量が限られている場合、この手法は大きな効果を発揮します。ブートストラップサンプリングは、様々な機械学習の方法と組み合わせて使うことができ、限られた情報からでも頑健で信頼性の高い予測モデルを作るための、強力な道具と言えるでしょう。
手法の仕組み

この手法は、たくさんの模型を作ることで予測の正確さを上げることを目指しています。
例えるなら、ある町の人口を知るために、町全体を調べる代わりに、いくつかの地区を無作為に選び、その地区の人口を詳しく調べます。そして、選んだ地区の人口から町全体の人口を推測します。この時、同じ地区を複数回選ぶことも可能です。
この手法では、選び出した地区を「見本集団」と呼びます。見本集団は、元の集団(町全体)と同じ人数になるように、重複を許して選び出します。つまり、同じ人を複数回選ぶことも可能です。このようにして、元の集団からたくさんの見本集団を作ります。
次に、それぞれの見本集団を使って、町全体の人口を推測する計算をします。それぞれの見本集団から得られる推測値は、見本集団によって異なるでしょう。
たくさんの推測値が集まったら、それらをまとめて、より正確な町全体の人口を推測します。例えば、全ての推測値の平均値を最終的な推測値とすることもできます。
この手法の利点は、限られた情報からでも、より確かな推測を行うことができる点です。町全体を調べるのは大変ですが、いくつかの地区を調べるだけで、町全体の人口についてある程度の確信を持つことができます。
また、異なる見本集団を用いることで、推測のばらつきを把握することができます。ばらつきが小さい場合は、推測値の信頼性が高いと言えます。逆に、ばらつきが大きい場合は、推測値の信頼性が低いと言えます。
このように、たくさんの見本集団から得られた情報を組み合わせることで、より正確で信頼性の高い推測を行うことができます。
利点

たくさんのデータから取り出した一部を使って学習させる方法を、ブートストラップ標本抽出といいます。この方法は、まるで靴紐を引っ張って自分の体を持ち上げるかのように、データの一部から全体の性質を推測しようとする試みです。この方法には、いくつか良い点があります。
まず、学習しすぎた状態を防ぐ効果があります。学習しすぎた状態とは、まるで特定の相手に合わせた対策ばかり練習してしまい、他の相手との試合でうまく対応できなくなるようなものです。ブートストラップ標本抽出では、毎回異なるデータを使って学習するため、特定のデータの特徴にこだわりすぎることなく、様々なデータに対応できるようになります。これにより、初めて出会うデータに対しても、より正確な予測を行うことができるようになります。
次に、計算の手間が少ないという利点があります。複数の計算を同時に進めることができるため、全体の時間を短縮できます。これは、たくさんの料理を同時に作るために、複数のコンロを並行して使うようなものです。それぞれのコンロで異なる料理を作るように、それぞれの計算で異なるデータを使って学習を進めることで、効率的に学習を進めることができます。
ブートストラップ標本抽出は、限られたデータからでも効果的に学習を進めるための賢い方法と言えるでしょう。まるで、ジグソーパズルのピースの一部から全体像を推測するようなもので、全体を把握するために必要な情報だけを効率的に利用することができます。この方法によって、より正確で効率的な予測が可能になり、様々な場面で役立つことが期待されます。
| メリット | 説明 | 例え |
|---|---|---|
| 学習しすぎを防ぐ | 毎回異なるデータで学習することで、特定のデータの特徴に囚われず、様々なデータに対応できるようになる。初めて出会うデータに対してもより正確な予測が可能になる。 | 特定の相手への対策ばかり練習してしまい、他の相手との試合でうまく対応できなくなるようなもの。 |
| 計算の手間が少ない | 複数の計算を同時に進めることができるため、全体の時間を短縮できる。 | たくさんの料理を同時に作るために、複数のコンロを並行して使うようなもの。 |
| 限られたデータから効果的に学習できる | 全体を把握するために必要な情報だけを効率的に利用する。 | ジグソーパズルのピースの一部から全体像を推測するようなもの。 |
応用例

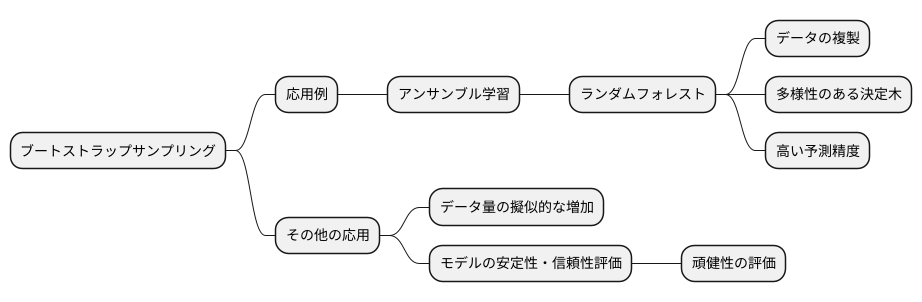
ブートストラップサンプリングは、様々な統計的手法や機械学習手法において、データの特性をより深く理解したり、モデルの性能を向上させたりするために活用されています。その応用例の一つとして、アンサンブル学習という手法が挙げられます。アンサンブル学習とは、複数のモデルを組み合わせて、より精度の高い予測を行う手法です。その代表例がランダムフォレストです。ランダムフォレストは、決定木と呼ばれる予測モデルを複数組み合わせることで、複雑な関係を持つデータに対しても高い予測精度を実現します。
ランダムフォレストでは、ブートストラップサンプリングを用いて、元のデータから複数の複製データセットを作成します。それぞれの複製データセットは、元のデータと同じサイズを持ちますが、一部のデータが重複して含まれている一方、含まれていないデータも存在します。このようにランダムにデータを抽出することで、各決定木が少しずつ異なるデータで学習され、多様性を持ったモデル群が生成されます。そして、それぞれの決定木による予測結果を統合することで、最終的な予測が得られます。この多様性こそが、ランダムフォレストの高い予測精度を支える重要な要素となっています。
ブートストラップサンプリングは、ランダムフォレスト以外にも、様々な場面で活用されています。例えば、限られた量のデータからでも有効なモデルを構築するために、データの量を擬似的に増やす目的で使用されることがあります。また、ブートストラップサンプリングを用いることで、モデルの安定性や信頼性を評価することも可能です。具体的には、ブートストラップサンプリングによって生成された複数のデータセットを用いて、モデルの精度やその他の評価指標を計算し、そのばらつき具合を調べることで、モデルの頑健性を評価できます。つまり、ブートストラップサンプリングは、データ分析や機械学習において、非常に有用な手法と言えます。特に、データ量が限られている場合や、モデルの頑健性を高めたい場合に有効です。
まとめ

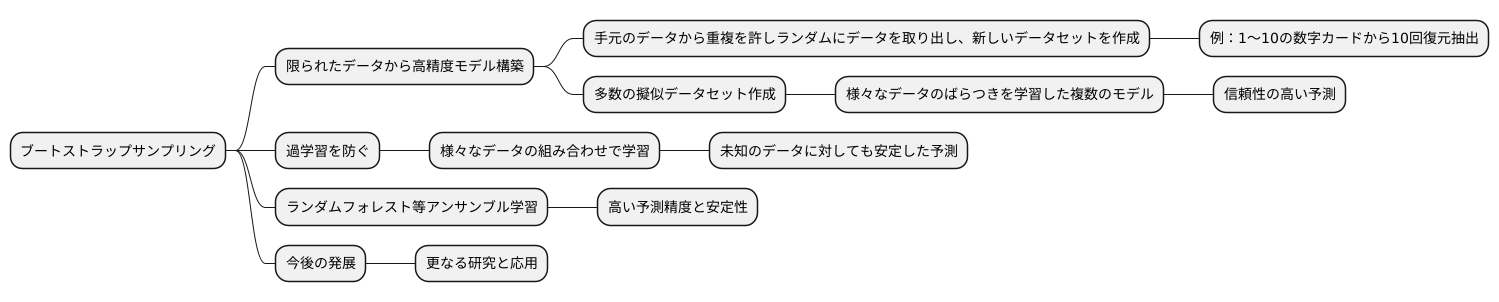
限られた量のデータから、精度の高い予測モデルを作り上げることは、機械学習の大きな課題です。ブートストラップサンプリングは、この課題を解決する強力な手法として知られています。
ブートストラップサンプリングの基本的な考え方は、手元にあるデータから、重複を許してランダムにデータを取り出し、新しいデータセットを作成することです。例えば、1から10までの数字が書かれたカードが10枚あるとします。ここから1枚カードを引いて数字を記録した後、カードを元に戻します。これを10回繰り返すと、同じ数字が複数回記録される可能性があります。これがブートストラップサンプリングの基本的な手順です。このようにして作られた新しいデータセットは、元のデータと同じサイズですが、データの組み合わせが異なっています。
この手法を用いることで、限られたデータから多くの擬似的なデータセットを作成できます。それぞれのデータセットを用いてモデルを学習させることで、様々なデータのばらつきを学習した複数のモデルを得られます。そして、これらのモデルの予測結果を統合することで、より信頼性の高い予測が可能になります。
ブートストラップサンプリングは、モデルの過学習を防ぐ効果も期待できます。過学習とは、学習データに過度に適合しすぎてしまい、未知のデータに対する予測精度が低下する現象です。ブートストラップサンプリングによって、様々なデータの組み合わせで学習を行うため、特定のデータに過度に依存することを防ぎ、未知のデータに対しても安定した予測を行えるようになります。
ランダムフォレストなどのアンサンブル学習は、ブートストラップサンプリングを効果的に活用した代表的な手法です。複数の決定木を組み合わせることで、高い予測精度と安定性を実現しています。このようにブートストラップサンプリングは、機械学習の様々な分野で応用されており、今後の発展においても重要な役割を果たすと考えられます。より高度な予測モデルの開発や、新たな応用分野の開拓など、更なる研究と応用が期待されています。
今後の展望

これからの世の中において、ブートストラップサンプリングはこれまで以上に活躍の場を広げ、様々な分野で役立つことが見込まれます。すでに多くの分野で成果を上げていますが、秘めた可能性はまだまだあります。
まず、今よりももっと効率的にデータをサンプリングする方法を開発することで、計算にかかる時間や資源を節約することが期待できます。例えば、データの特徴に合わせてサンプリング方法を調整することで、精度の高い結果をより早く得られるようになるでしょう。
さらに、様々な学習の仕組みと組み合わせることで、ブートストラップサンプリングの効果を高めることが可能です。例えば、決定木やサポートベクターマシンといった機械学習の手法と組み合わせることで、予測精度を向上させたり、新たな知見を発見したりすることができるでしょう。
また、近年注目を集めている深層学習といった複雑な学習の仕組みにも、ブートストラップサンプリングを応用することで、さらに高い精度を実現したり、今までにない活用方法を生み出したりすることが期待されます。例えば、画像認識や自然言語処理といった分野で、より高度な分析が可能になるでしょう。
そして、データの量がますます増え、計算機の性能が向上していくにつれて、ブートストラップサンプリングの重要性はますます高まっていくと考えられます。膨大なデータを効率的に扱うために、ブートストラップサンプリングは欠かせない手法となるでしょう。
今後の研究によって、ブートストラップサンプリングはさらに進化し、様々な分野で大きな貢献を果たしていくことが期待されます。医療、金融、工学など、幅広い分野での応用が期待されており、社会の発展に大きく寄与していくことでしょう。
| 今後のブートストラップサンプリングの展望 |
|---|
| より効率的なサンプリング方法の開発 |
| 様々な学習の仕組みとの組み合わせ |
| 深層学習への応用 |
| データ量の増加と計算機性能の向上に伴う重要性の高まり |
| 様々な分野への貢献 |